An overview of Blockchain, Bitcoin and digital currency
Digital Currency
Digital currencies group many different forms of money and payment systems sharing the property to be managed and exchanged from computers, mostly over the Internet. We may have a simplified model to reason on a currency. We need a few properties to have a receptacle of value that can act as a currency:
- We need the ability to create an account which can store value.
- If Alice creates an account, only Alice can manage it. In particular Bob cannot perform actions using Alice’s bank account. This property is already difficult to obtain: the account is usually a service exposed by a third-party to Alice, and this third-party has a potential control over Alice’s account. In the real world, Alice is protected from the third-party by laws and regulations that limits the third-party to act arbitrarily or face legal repercussions.
- We need the ability to transfer value from an account to another.
- We cannot transfer more value than what we have.
These properties are mixing functional design goals and security guarantees. In the banking system we’re used to know as citizens, security is enforced by a trusted third-party almighty over our account balance. The bank is the trusted third-party, and unless we transfer value from our bank account to fiat currency (another form of currency!), we have no guaranteed control over it, technically speaking (we have legal guarantees only).
Since modern cryptography arose, ideas were proposed to give citizens more control over their own money in the digital world. The first cryptography-based digital currencies dates from the 80ies, and were called e-cash. David Chaum designed the first Untraceable Payment System to copy the property of fiat currency exchange, but over the digital world. The design however still relies on a trusted third-party for running the payment protocol and applying the desired transfers. However, moving funds requires a cryptographic (with blinded recipient) signature from the account owner, so technically, the bank cannot move funds by itself in e-cash based system: it needs assistance from the owner.
Identity & authenticity
Identity and authenticity are related but sometimes obscure for the end user to understand the guarantee we may have for a given displayed identity. For example, if you receive an email from an address: firstname.lastname@unamur.be, there is no guarantee that the identity owner wrote it. The email protocol does not force authentication of identities for sending emails. The same goes if you receive a network packet from an IP address. There is not guarantee the packet was issued really from the claimed IP address; IP does not support authentication.
In general, we don’t want to give malicious users the ability to pretend to be someone else. It is a defect of many Computer systems built in the past and maintained for backward-compatibility. For money transfer, it is relatively obvious that we don’t want to give such a capability to malicious users. One approach to do this is to try to have self-authenticated identities. That is, receiving from a given identity implies that only this identity could have produced it. How can we do that?
Remember Asymmetric Cryptography from Chapter 4. We discussed generation of pairs of public key (\(pk\)) and secret key (\(sk\)) together linked by an intractable problem that prevents anyone with knowledge of the public key to perform operations that only the private key allows. Therefore, one could generate a pair (\(pk, sk\)) and sets its public identity as \(pk\). When \(pk_{Alice}\) interacts with the outside world, she then can prove to be the owner of the identity by signing messages with her private key. Anybody with knowledge that \(pk_{Alice}\) is Alice (remember that \(pk_{Alice}\) is just a number belonging to a group \(\mathbb{G}\)) can then verify the signature using Alice’s identity directly.
Digital Transactions
If Alice wants to transfer money to someone else, Alice could for example write the message:
“\(pk_{Alice}\) transfers 42.322 Coins to \(pk_{Bob}\)”.
and signs it with \(sk_{Alice}\). Everybody can verify using \(pk_{Alice}\) that the transaction order has been signed by Alice, and thanks to the unforgeability property of the digital signature, only the holder of \(sk_{Alice}\) can produce such a signature.
Tracking Balance
“We cannot transfer more value than what we have”. This property requires more than just signatures and asymmetric cryptography. The signature only guarantees that the signed message has been indeed produced by the secret key owner, but we do not trust the secret key owner to have enough money to make the transfer.
The simple approach to solve this problem is to establish a trusted third-party that would track each message “\(pk_{user1}\) transferred X Coins to \(pk_{user2}\)” and write them into a ledger. You could picture this ledger as a simple book where each line contains a transaction. Going through all the book, following each transaction update the state of accounts.
\( Pk_{user42} \) transfers 499 coins to \( Pk_{user110} \). Signed with \( user42 \)'s key.
The trusted third-party would know the account balance by going through the ledger what is the status of, say, Alice’s account. Upon receiving a transfer order, the trusted third-party would check the balance and accept the transaction or refuse it. If the trusted third-party accepts it, it is added to its ledger, otherwise, the transaction is denied.
One problem with that approach is that, while the bank isn’t able to move Alice’s fund, or create transactions on Alice’s behalf, the bank may be able to manipulate the ledger after-the-fact and eventually deny to Alice the existence of some incoming or outgoing transactions. That is, the state of the ledger is dependent of the third-party. This one problem could be addressed by specific data structures involving usage of cryptography. The properties that we may seek for this ledger could be:
- Append-only. We can only add new transactions.
- Securely immutable data. We cannot change existing past entries, and this is ensured by cryptography primitives.
- Public. Everybody can see the ledger and ensure that the two above properties are verified, using cryptography.
Research has solved this problem with a body of literature called append-only logs. A hash chain is a simple data structure having the required properties, but other structures do exist as well (mostly trees).
Hash Chains
Let’s label a transaction as TX, a signature as \(\sigma \) that
contains the output of a cryptography sign algorithm over TX, the
output of cryptographic hash function Hash, we can
define a block with the following content:
The block contains information about the transaction, like a one-liner on the previous trusted third-party ledger, but this time the block also “commits” to the history of the ledger by storing a hash of the previous block, itself storing a hash value of the previous block. This is a hash chain, with contextual information next to each hash.
With this form of data structure, we can have the central authority (the bank) write transactions into the hash chain. We can have clients download or even exchange blocks in peer-to-peer and let them verify that the blocks are correct by recomputing their claimed position in the hash chain. The properties of cryptographic hash function guarantee (see Chapter 4) that the bank or other parties cannot replace existing blocks that were shared to everyone without being detected.
Assume Alice receives a block B. Alice would first verify the bank’s
signature using the signature scheme’s verify algorithm
verify(Pk_{Bank}, B.TX, B.signature_bank) ?= true , and then checks
whether the block correctly inserts in her view of the hash chain by:
- Verifying that no other valid block exist at position \(i \). Such event could indicate that the bank is trying to rewrite the history by forking the existing chain at position \(i\), i.e., creating a new hash chain from position \(i\).
- Verifying \(H(Block_{i-1}) == B.previous\_block\_hash\) by recomputing the hash value of Block at position \(i-1\).
An interesting property of the hash chain is that, if you receive the last block from a trusted source, you can verify that the whole chain is correct by hashing the blocks up to finding the same hash value than the one contained in the received trusted block.
Blockchain != Hashchain
So far we discussed a centralized trusted third-party, and improved the system up to the point where we can check that the centralized party is correctly performing its task, but we are still dependent from it. In terms of system security, we may see this central party as a single point of failure. If the central party stops doing its work, the whole system stops.
Distributed Consensus
The trusted centralized third-party has an authoritative power on whether or not it includes some transaction, since it is the central party that produces the blocks and makes them available. If we want to move away from a central power, we need a method to have an agreement among different parties on how to add a block to the chain, in which order and what transaction is added. This agreement is also called a consensus algorithm; there are many consensus algorithms, with different liveness, safety and security properties. In the case of a monetary system, we may assume that any party is potentially malicious, and we need a consensus algorithm that resists a malicious identity, as well as a group of malicious identities. This last bit is really challenging; we call this sort of collective attack a Sybil attack: the group of identities can be different people, but also a single individual generating many identities, since an identity is defined by a public key, and the adversary can generate as many pairs of secret keys and public keys as they wish. Remember, an asymmetric cryptosystem has a \(Gen\) algorithm to generate a pair (\(pk, sk\)). These algorithms are fast, and can generate hundreds of pairs of keys per CPU core per second.
Proof of Work
The best known algorithm security-wise to defend against Sybil, while allowing all the participating members to agree on the hash chain ordering problem and transaction selection problem, is the Proof of Work (PoW). The PoW algorithm provides an asymmetry in the work needed to build a block, and the work needed to verify that a block is correctly built. Building a block is expensive, and the expected amount of CPU work to successfully build one can be controlled by a global network parameter linked to the underlying PoW algorithm. However, verifying the validity of the proof of work is immediate. We’ll discuss one example of PoW algorithm below.
The name, “Proof of Work”, may be misleading. The fundamental idea is not to prove that some user did some computational work, but to deter manipulation of the hash chain by establishing a minimum amount of computational power to be able to do so. The security of the resulting chain would then depend on whether this assumption holds. So, importantly, if you see a system with a consensus algorithm involving a proof of work, its usage may only be justified if Sybil attacks are a threat to the system. If it is not the case (e.g., because the system force authentication by a central party), then doing a PoW is pure nonsense to its finest form: technical misunderstanding, or worse, an overhyped tech mistreated as a social progress.
To exemplify a proof of work algorithm, we modify the previous block
definition by removing the bank’s signature (there is no bank anymore)
and adding a nonce value, and a constraint on the previous hash block
from a global parameter. Nonce is short for “number once”, and is
generally used in cryptographic systems as a value that is guaranteed to
appear only once. In blockchains, think of the nonce rather as an
integer that is probabilistically likely to appear once. Our Block
definition becomes:
The constraint on the previous hash block is that the hash value of the previous blocks must start by \(n\) bits to zero. We can influence the result of the hash computation by selecting the nonce, which is a simple integer value in a large range. There we have our Proof of Work, which consists of finding an integer and setting it in the block such that its hash fulfills the constraint starting of \(n \) bits at value 0.
function solve_block(B) {
nonce = rand(0, 2^64)
B.nonce = nonce
while !hash_starts_with_n_zeroes(H(B)) {
nonce++
B.nonce = nonce
}
return B
}
In this simple solve_block function, the cost of solving a block
depends on the probability to find a nonce that results in the desired
hash. As per the properties of a cryptographic hash function, any
modification of the input leads to another output value taken uniformly
at random in the output space (but deterministic).
We may model this problem as a Bernoulli trial; that is, a random experiment with two possible outcomes, either a valid is found, or no valid hash is found. Let \(p\) the probability of success, i.e., we obtain of valid hash, and \(q\) the probability of failure. Clearly, \(q\) is \(p\)’s complementary: \( q = 1 - p \). From a Bernoulli trial, we may derive what is called a binomial experiment, which consists of a series of \(n\) statistically independent Bernoulli trials (that is, the occurrence of one Bernoulli trial does not affect the occurrence of another) each with a probability of success \(p\). The pseudocode above can be modelled as a random variable corresponding to a binomial experiment with a probability of success influenced by the number of prepended zeroes. We usually note such a binomial experiment \(X \sim B(n, p)\), and we can compute the probability of \(k\) successes in the experiment \(B(n, p)\) by:
$$ Pr[X = k] = \binom{n}{k}p^kq^{n-k} = \frac{n!}{k!(n-k)!}p^kq^{n-k} $$
We are interested in a single success, i.e., \(k = 1 \) for \(n\) tries that corresponds to the number of loop iterations within the algorithm until a success is found. The expected value of this probability function is given by \(E[X]\), which follows the sum of the expected value of each Bernoulli trial (hence \(p + p + p\) … \(n\) times), so we have:
$$ E[X] = np $$
Let’s assume we want our Hash output to starts by 26 bits set to 0. Since the probability that each bit is 0 is independent, the probability that the first 26 bits are 0s is given by \( (1/2)^{26} \). That’s our \(p\) value. This means we would need to run the loop \( 2^{26} \) times to find a single matching hash in expectation.
But are we not too conservative asking for a single success? We might rather be interested in the probability of at least one success, that is we run our algorithm for \(n\) iterations, and we are wondering how many successes we can get: 1, 2, 3, 4, … more than 1 is still valid. We can express this random variable as follows:
$$ Pr[X >= 1] = 1 - Pr[X = 0] = 1 - q^n $$
This random variable is still a binomial; we can take the cumulative probability function with respect to \(n\), which would show how the probability to find at least one valid hash increases with the choice of \(n\).
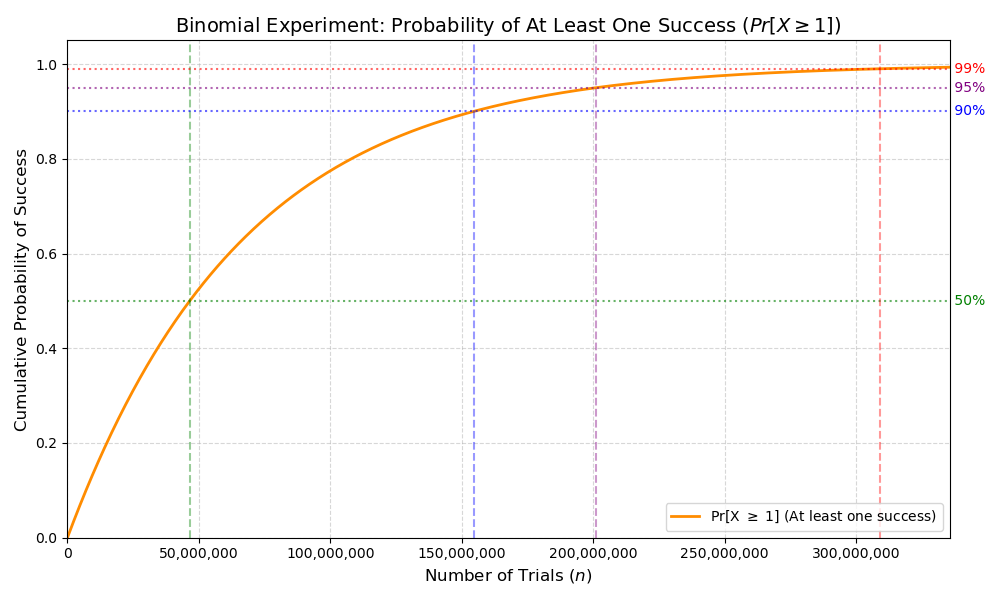
You may test it using the following naive Rust implementation:
use clap::Parser;
use rand::prelude::*;
use sha2::{Digest, Sha256};
#[derive(Debug)]
struct Block {
miner: String,
nonce: u64,
transaction: String,
}
impl Block {
/// Naive implementation finding a nonce such that the block hashes (using SHA256)
/// to any value starting with a number zeroes at least equal to 'difficulty'.
fn solve_block(&mut self, difficulty: u8) -> Vec<u8> {
let mut rng = rand::rng();
self.nonce = rng.random();
let mut hash = Sha256::new()
.chain_update(&self.miner)
.chain_update(self.nonce.to_le_bytes())
.chain_update(&self.transaction)
.finalize();
let init = self.nonce;
while !leading_zeros(hash.as_slice(), difficulty) {
self.nonce += 1;
hash = Sha256::new()
.chain_update(&self.miner)
.chain_update(self.nonce.to_le_bytes())
.chain_update(&self.transaction)
.finalize()
}
println!("Loop iteration: {}", self.nonce - init);
hash.to_vec()
}
}
fn leading_zeros(hash: &[u8], difficulty: u8) -> bool {
let intermediate: [u8; 8] = hash[0..8].try_into().expect("conversion");
let prefix: u64 = u64::from_be_bytes(intermediate);
prefix.leading_zeros() >= difficulty as u32
}
#[derive(Parser)]
#[command(version, about, long_about = None)]
struct Args {
#[arg(short, default_value_t = 10)]
diff: u8,
}
fn main() {
let args = Args::parse();
let mut block = Block {
miner: "Frochet".to_string(),
nonce: 0,
transaction: "Frochet pays 42 coincoincoin to Bob".to_string(),
};
let hash = block.solve_block(args.diff);
println!(
"Solved block: {:?}, with hash {:?}",
block,
hash.iter()
.map(|elem| format!("{:08b}", elem))
.collect::<String>()
);
}The position choice of the zeroes, and even the fact that we choose 0
is arbitrary. We could have said that the hash value finishes by \(n\)
bits set to 1, this would be computationally equivalent to build a
block.
Incentive mechanism
The proof of work supports everyone to add a block to the chain by finding a correct nonce. Why would anyone invest CPU time to find the winning ticket? Especially, to resist Sybil attack, the number of zeroes at the beginning of the resulting hash value should be high (the higher the better) such that no adversary has enough computational capabilities to modify the history of the chain.
How could the adversary modify the chain of size \(n\)? The adversary can add blocks and fork the chain at any position \(i\) forking it by publishing a block that solves the proof of work at position \(i+1\) and then building a largest chain faster than the pre-existing chain is growing. Once the attacker publishes blocks creating a new bigger chain forking at position \(i\) to \(m\) where \(m > n\), honest network members would always follow protocol and add blocks to the largest chain, hence abandoning the previous chain, revoking instantly all transactions from blocks \(i+1\) to \(n\) of the previous chain, modifying the balance of every account that operated movement on the initial chain.
b0----b1----b2----...----bi---bi+1-----...----bn (initial chain)
\
\
\--bai+1---bai+2----...----bam (forked chain)
Typically, we would define the main chain as the chain that cumulates the most CPU work which is the “longest” chain in our simple design, although keep in mind that within a real blockchain protocol, this notion of “longest” is a little more complex than just the number of blocks.
What motivates the honest members of the network to add blocks to the
chain? What is the incentive? Currently nothing but intrinsic
motivations to participate and have a distributed system. This would
likely not be enough in the real world to outrun the adversary in terms
of cumulated CPU power. We can easily add extrinsic motivations to
intrinsic ones with money, and then expect people to add blocks either
for money, for personal reasons, or for both. To add motivations for
money, we again extend our block definition and add what we could label
as a miner: the identity that generates the block, as well as a
monetary creation transaction order that creates coin from thin air
and transfers it to the miner identity.
TX2 could be a simple message “X coins created and allocated to \(PK_{miner}\)”. It does not need to be signed by anyone since attempting to modify the transaction would automatically fork the chain.
Bitcoin
What we designed so far is essentially a simplified version of Bitcoin. Our current limitations are essentially the following:
- There is only one transaction per block (two if we count the money creation).
- There is no monetary creation policy (it is a fixed value leading potentially to infinite money if we have an infinite chain).
- There is no policy to select transactions, nor a protocol to let everyone knows about pending transactions.
- The proof of work difficulty adjustment is not defined. We need one to adapt to surge/decrease of mining power.
- Everyone has to download the full chain – we defined no hierarchy.
- Some of the information is redundant (e.g., miner’s identity contained again in TX2).
Bitcoin is essentially a more complete protocol than our straw man
approach, solving these limitations. However, Some of these limitations
are only partially addressed in the real Bitcoin protocol. For example,
Bitcoin can store a limited amount of transactions on a block, organized
in a data structure called a Merkle Tree. The choice of the data
structure is linked to the performance and security guarantees it
provides when dealing with transactions contained in a block. But
overall, Bitcoin decided to stick to a particular block size limiting
the amount of transactions that can be propagated in a block. To address
the Sybil attack problem, Bitcoin dynamically adjust the difficulty of
the proof of work such that the whole network hashing power combined can
mine one block every 10 minutes in expectation. There is simple
probability and statistic behind the adjustment logic to enforce such
a behavior, based on observing how many blocks were added to the chain
in the recent past. Therefore, the limited block size combined with an
expectation of 1 block every 10 minutes defines the transactional
throughput that the bitcoin network is capable to perform. Needless to
say, this throughput is very slow with about 5 transactions per second
on average, making the protocol practically unusable for anyone else
than a minor fraction of the population adepts of financial speculation
and/or libertarian ideologies.
As far as research has been going, we are still unable to produce a secure distributed payment system that can scale to the point real world usage by common people is possible. Moreover, it only consider the throughput problem. Other properties of Bitcoin and other cryptocurrencies are questionable for a base payment layer in the society, due to its absence of trusted third-party that is as well useful to derive defenses against scammers and protecting vulnerable people. Do we want to live in world in which we can’t trust anyone but ourself?
Blockchain misconceptions
What we have covered so far should allow you to understand why some applications of blockchains may not have much sense.
-
Blockchains without cryptocurrencies. If we remove the cryptocurrency creation and management from the blockchain, we remove the extrinsic motivation to perform the proof of work. This proof of work is what prevents Sybil attacks and its strength depends solely on network’s members participation. Without the cryptocurrency attached to the blockchain, it is unlikely a Sybil-resistant distributed consensus would be achievable.
-
Blockchains as a certification service. The diplomas certified in a blockchain is a regular use case brought up by blockchain aficionados. However the value of a diplomas inherently depends from the value we perceive from a trusted third-party: the issuer. The blockchain has no control over that aspect; we’re better off simply having the diplomas available online and signed by the trusted third-party, without costly proof of work in the process, as it brings no added value.
Certification is inherently linked to the concept of authority; blockchain has authority only for what is conceptually inherent to the blockchain itself (e.g., the state of an account defined from all the transactions within the blockchain), not for anything within the real world. It is not because, say, we certify in the blockchain that the Golf of Mexico is called the Golf of America that suddenly all the world agrees that it is truth. No, the “truth” within a blockchain only applies to the resulting state read from all block transactions; nothing is inherently true to anything attached to these transactions.
-
Blockchain is the solution if you need immutability. No. Cryptography provides the necessary tools to create immutable data structures. There are many variants with performance and security trade-offs. Blockchain is a solution when no system users share any common trusted third-party. Besides financial transactions, it is unclear any other real world use case may have such a severe threat model.
More details may be read (in French) in this article.