Secure Low-level Programming
Writing secure software is a daunting task. Problems may occur at various levels of a software product: down from low-level programming to high-level design architectures. This part of the course covers low-level programming issues that could potentially be turned into exploitable vulnerabilities usually involving the term “RCE” for “Remote Code Execution”. Many different types of RCE exist; research in software security keep finding novel methods to design RCEs. Designing a RCE requires a deep understanding of the underlying software architecture as they involve understanding and exploiting its limitations. We’ll try to review the fundamentals that were scattered in previous classes, such as Computer Architecture and Operating Systems to get the necessary background, then we will cover fundamental low-level programming issues that should give us some intuitions over potential problems. Eventually, we’ll explore one of them in details and write a RCE ourself.
Secure Software Preliminaries
Machine Architecture
Modern machines are mostly based on the Von Neumann Architecture

Modern machines have at least these components:
-
A processing unit with arithmetic logic and registers. Eventually, computers perform basics computation between memory words, such as addition, multiplication, XOR, etc. There is a lot of complexity in how doing these operations efficiently, potentially in parallel. Some modern architectures also have advanced instructions to perform many computations at once, speeding up certain algorithms.
-
A control unit with registers and program counter to track the next instruction to execute
-
Memory for storing data and code to execute. The code to execute is data as well; from the perspective of the computer, code is just information. It happens that code is information written in way that the machine can execute it. The way we write code depends solely of the machine architecture; yet at the high level of programming language (such as C, Java, Python), we do not see much of these details, as these languages strike their own compromise between usability, security and efficiency. Eventually, they do the translation between the code we write and the machine code that the computer eventually executes within its memory. Compilation is one approach chosen by some languages. Interpretation is another.
-
External Storage. Anything storage that keep holding information when the power is down.
-
IO mechanism. How to interact with the outside world; transferring memory or acquiring information.
Historical aspect of computer sciences are critical to the understanding of modern computer sciences. Modern achievements are built on the foundational work and knowledge of past computer scientists. Truly understanding modern achievements requires somewhat knowledge of the past. Regarding machine architectures, Intel shares detailed documentation and historical documents regarding the evolution of Intel processors.
Chapter 2 (~20 pages) is an interest read covering basic x86-32 bits to modern processors being used today. You’ll find information about Intel’s efforts through years to improve their processors in a backward-compatible manner, a necessary goal to keep compatibility to old programs written and compiled for older processors architectures than the ones we use today.
Backward-compatibility is also the reason why even in modern architectures like x86-64 (what we likely have on our laptop), most programs compiled and publicly distributed do not use the extend of our machine capabilities. Indeed, Intel designed and deployed many instruction extensions able to crunch certain operations much faster than regular instructions. Using them depends on compilers producing these machines code instructions, but since programs are today compiled and distributed ahead of the time in which we run them, we may not be using our processors to its full capability. Indeed, developers compiling their software have to produce a binary that would be compatible to most x86-64 processors, thus limiting usage of special instructions. Dynamic detections of extensions is possible, but put the burden on the developers to use these extensions safely.
Note
Some people prefer to download program sources and re-compile everything themselves. The compiler would then know what extensions are available and would produce a binary that uses them, improving performance quite a lot in some cases. It is one of the existing motivations for open-sourcing software, and it all stems down from Architectures’ backward compatibility goal. In this class, we’ll exemplify concepts using the Rust language. So, as a first example, for compiling Rust code with native instructions, we can do the following:
Tip
$ RUSTFLAGS='-C target-cpu=native' cargo build --releasewhich instructs
rustc, Rust’s compiler, to build the software using the processor’s native capabilities. We will soon cover the very basics of Rust. In the meantime, keep in mind that locally compiling ourself programs may be quite advantageous!
Specifying an architecture
A machine architecture defines what we call a “Basic Execution Environment” that defines itself how a program should be structured and evolves during its execution, how it is held in memory, and eventually how it impacts secure programming due to its limitations.
A x86-32 architecture is a slightly more complex Von Neumann architecure. Among other things, x86-32 processor holds a few registers: dedicated memory regions very close to the processor unit, whose content is extremely fast to retrieve. These registers play a critical role for the execution of any program. We have 8 registers, 6 general purpose registers and 2 EFLAGS register with specific roles, 6 segments registers and 1 PC register.
- 6 general purpose registers (named %eax, %ebx, %ecx, %edx, %esi, %edi) These are 32-bits memory region that may hold operands for logical and arithmetic operations or operands for address calculation. These registers have historical role to contain some information in particular (with older architectures), but should today be regarded as general purpose.
- 2 EFLAGS register (%esp, %ebp) %esp = stack pointer, %ebp = base pointer Hold memory pointers (address).
- 6 segment registers (%cs, %ds, %ss, %es, %fs, %gs) 16-bits registers holding a 16-bits pointer pointing to a memory segment of the program address space.
- 1 PC register (%eip). This register cannot be accessed directly by the programmer/programs for security reason. This register contains an offset of the current code segment for the next instruction to execute. The register’s value is automatically updated by assembly instructions JMP, Jcc, CALL, RET, and IRET, interrupts and runtime exceptions.
These registers happen to be designed with backward compatibility for the 16-bits version of Intel processors. So we can directly reference 16-bits and 8-bits portions of these registers using shortcuts, such as %ah, %al, %bh, %bl, %ch, %cl, %dh, %dl. Note that naming in assembly language are not case sensitive, so for example %esp is the same as %ESP.

Memory Model
Programs require memory to run and store temporary results of their execution as well as data provided as input. To store this data, the program needs a memory model, essentially a structure to address information. In the Intel IA-32 architecture, programs can address into a linear space of up to 4 GiB (from 0 to \(2^{32}-1\) in bytes), which is different than the amount of available physical memory in the system. The maximum physical memory an IA-32 architecture can deal with is 64 GiB.
The operating system is the one responsible to provide this simple linear abstraction of the memory model to programs, and hide non-contiguous ranges into contiguous pages of memory with paging. So, from the perspective of any program (and ours, since we will not dive below this abstraction), the memory is a simple, flat and contiguous region of bytes.
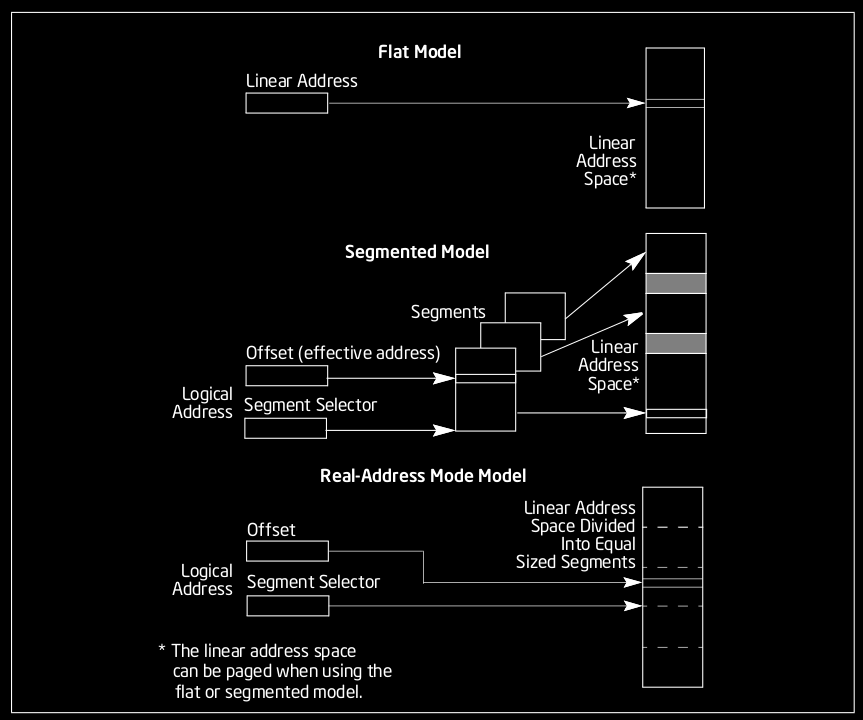
Program Layout
To run a program, an operating system launches a process. A process divides the program’s contiguous memory into several different sections (also called segments) from the program’s file. Two of these segments created by the process at launch can grow and shrink during the program’s execution, following the program’s memory requirements. Other segment names and purpose may vary depending on the compilation target, and most of them are directly structured within the program’s file and loaded by the process.
We have the following typical segment within a program:
-
.text segment: contains the executable code (i.e., compiled code) of the program. This is generally read-only and its size is fixed at compile time. This segment is also within the program’s file.
-
.data segment: Contains the initialized static variables of the compiled program. These variables may be global or local, and can be modified during the program’s execution. This segment is also within the program’s file.
-
.rodata segment: Contains the initialized static constants (local or global). It is usually Put below the data segment. This segment is also within the program’s file.
-
.bss segment: Contains the uninitialized static variables of the compiled C program. Usually this section contains the length of the uninitialized data, and the program’s loader would simply fill the memory layout’s bss with zero-valued bits. After the program has loaded, this section would typically contain all uninitialized variables and constants declared outside any function, as well as uninitialized static local variables. Static local constants must be initialized at declaration as required by the C standard, so they do not exist in this section. This segment is also within the program’s file.
-
.heap segment: Contains the program’s dynamically allocated memory, which occurs during its execution. Assuming the address 0 refers to the bottom of the text, the heap starts at the end of the bss’s address and grows to higher address values. The heap acts as a memory dump shared by all threads, dynamically loaded libraries and modules in a process. This segment in created on program launch; it is not part of the program’s file.
-
.stack segment: Contains the call stack, there is usually one per active thread of a process. The stack serves several purposes: storing the return address of the caller, and offering a local fast memory space for the routine being executed.
Important
A special register (%esp) contains the “stack pointer” which tracks the “top” of the current stack frame. In x86, the top of stack is growing downward in address value. The stack boundary is always aligned to a multiple of its architecture word size, and chosen at compilation. Usually, we have a 16-bytes alignment. The reason is speed; the why is well explained on Wikipedia, for curious minds.
For example, the following program memory_layout.c:
#include <stdlib.h>
unsigned char x = 42; // into .data
static char *p = "Hellow!"; // into .rodata
static const unsigned char XX = 42; // into .rodata
int main() {
static int y = 43; // into .data
int w = 44; // allocated on the stack during exec.
int *my_p = (int *) malloc(sizeof(int)); // 4 bytes allocated on the heap
// during execution
my_p[0] = 45;
free(my_p); // tell the OS that we don't need the memory block allocated at
// address my_p.
return 0;
}
may be compiled and then inspected using the following unix utilities:
gcc -g -static -m32 memory_layout.c -o memory_layout
readelf -x .rodata memory_layout
Tip
To be able to compile, you might need installing developers headers for 32-bits architecture. The details of this operation depends on your linux distribution.
x86-32 instructions background
Typical x86-32 instructions perform data movement, arithmetic, control flow and string operations. They operate on data within the memory, either on the stack or the heap, and with registers. They act on zero or more operands. Some operands need to be explicit, other are implicit to the instruction.
Note
An operand is the quantity or address on which the operation is performed.
Immediate Operands: an instruction may use a source register and a value, and operate with that value. A value operand is said to be an immediate operand.
E.g.,:
ADD 42, %eax.
Warning
Sometimes source and destination may be reversed. We will try being consistent with “INSTRUCTION” src, dest format.
Note
All arithmetic instructions (except DIV and IDIV) allow the source operand to be ‘immediate’. 42 is immediate. The value can never be greater than \(2^{32}\) on i386, otherwise it loopbacks to 0 (integer overflow). If an overflow happens, the instruction sets a flag; conditional statements can then check for the presence of such flag. All of this may be automatically added by the compiler. You may find more information on CPU flags on Wikipedia
Some common instructions manipulating register and memory Operands Source and destination operands can be any of the registers
MOV – Copy value from source to destination. MOV may interpret values differently depending on variants.
MOV %ebx, %eax – Copy the value from %ebx to %eax
MOV [%ebx], %eax – Move the 4 bytes in memory at the address contained in
EBX into EAX
MOV %ebx, [var] – Move the contents of EBX into the 4 bytes at memory address var. (Note, var is a 32-bit constant).
MOV [%esi-4], %eax – Move 4 bytes at memory address ESI + (-4) into EAX
MOV cl, [%esi+%eax] – Move the contents of CL into the byte at address ESI+EAX
MOV [%esi+4\(\times\)%ebx], %edx – Move the 4 bytes of data at address ESI+4\(\times\)EBX into EDX
MOV supports various operations, and the instructions has several opcodes for each variant. The opcode is the byte(s) value identifying the instruction.
PUSH – Push on the top of the stack its operand. Remember that in x86, the stack is growing downward to lower addresses. The top of the stack would be the bottom on our representation. How? PUSH internally uses %esp, and first decrement it by 4, and then moves its operand to the 32-bits location at [%esp].
PUSH %eax – Push the value contained in %eax to the top of the stack.
PUSH [var] – Push the 4 bytes located at address var to the top of the stack.
PUSH [%eax] – push the 4 bytes located at the address contained in the %eax
register on the top of the stack.
POP – Removes and move the 4-byte element from the top of the stack into the specified operand. Then increment %esp by 4.
POP %ebx – pop the top of stack into %ebx
POP [var] – pop the top of the stack at the address pointed by var.
Some common control flow instructions (i.e., maniputating where we are into the execution).
JMP – Jump instruction. Transfer the flow execution by changing the value of the program counter (%eip). Different opcodes to accomodate to variant, such as the mode into which the processor is running, or the type of jump.
JMP %eax – jumps to the address within %eax
JMP [var] – jumps to the address pointed by var.
JMP foo – jumps to the label foo within program.
Jcc – Jumps under condition cc. Conditional jump based on the status stored within a special register called machine status word. The status indicate information about the last arithmetic operation performed. There many different cc resulting to variants jumps: (JA, JAE, JB, JBE, JC, JE, JG, JGE, JL, JLE, JNA, JNAE, JNB, JNBE, JNC, JNE, JNG, JNGE, JNL, JNLE, JNO, JNP, JNS, JNZ, JO, JP, JPE, JPO, JS, JZ). e.g., JLE would jump if the status indicates that the last arithmetic operations resulted to a value less or equal to 0.
CMP – Compares the value within the two operands. Implemented by doing a subtraction between the two operands. CMP is usually followed from a Jcc instruction, for example to branch following a condition.
CMP %ebx, %eax – performs the subtraction %ebx - %eax, then set appropriate flags
CMP %eax, 42 – performs the subtraction %eax - 42, then set appropriate flags
CMP %eax, [var] – %eax - 32-bits value contained at addr var, then set appropriate flags.
CALL – Pushes %eip onto the stack and then perform an unconditional jump to the label operand. Pushing %eip to the stack allows to restore the current stack frame when the next sequence of instruction hits a RET instruction, since %eip contained a pointer to the code next to the call instruction.
RET – Pops the return address from the stack and jumps to it. This instruction changes the %eip value and sets the return address.
The stack in more details: an example
Let’s have the following C program stack_details.c:
static void foo(int a, int b) {
int x, y;
// Store x and y on the stack, from a and b stored on the stack during
// the function execution preparation phase.
x = a + b;
y = a - b;
// Here the stack pointer is set back from the value of the frame pointer The
// return address is pop'ed, and the program jumps back to where it was
// before func() was called. x and y still lives on the stack, below the
// current value of the stack pointer (hence are lost, and will be erased
// by introducing any local variable or function call).
}
int main() {
foo(42, 43);
return 0;
}
This code is a simple function foo() getting called with two integers
in parameters. Let’s compile the code and look at its assembler output:
$ gcc -fno-stack-protector -fno-asynchronous-unwind-tables -fno-pie -m32 -S stack_detail.c
It should produces a file named stack_detail.S hopefully similar to the following:
.file "stack_detail.c"
.text
.type foo, @function
foo:
pushl %ebp
movl %esp, %ebp
subl $16, %esp
movl 8(%ebp), %edx
movl 12(%ebp), %eax
addl %edx, %eax
movl %eax, -4(%ebp)
movl 8(%ebp), %eax
subl 12(%ebp), %eax
movl %eax, -8(%ebp)
nop
leave
ret
.size foo, .-foo
.globl main
.type main, @function
main:
pushl %ebp
movl %esp, %ebp
pushl $43
pushl $42
call foo
addl $8, %esp
movl $0, %eax
leave
ret
.size main, .-main
.ident "GCC: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0"
.section .note.GNU-stack,"",@progbits
Note
Some differences may exist depending on the compiler’s version and OS configurations. This was generated on an Ubuntu 22.04 with gcc 11.4.
From the assembler, we may draw a picture of what the stack of the
program looks like when the function foo() is called and executes its
first two instructions.
Higher addr +------------------+
| | |
| | |
| | |
| +------------------+
| | b |
| +------------------+
| | a |
V +------------------+
| return address |
+------------------+
%ebp ------> | saved main %ebp |
+------------------+
| x |
+------------------+
| y |
+------------------+
| |
+------------------+
%esp ------> | |
Lower addr +------------------+
The stack layout, function prologue and function epilogue are made from “calling conventions”:
function prologue: When a function is called, the computer performs the following two instructions:
push %ebp (1)
mov %esp, %ebp (2)
These instructions (1) saves the previous stack’s frame EBP value by
pushing it on the stack. When foo() returns, the value will be
restored. (2) updates the value of EBP by setting the value of ESP. It
is the beginning of function foo()’s stack frame. The prologue is also
parts of the conventions forming what we call the x86’s ABI (Application
Binary Interface). Summary the following elements describes the x86’s
ABI:
-
The order in which atomic (scalar) parameters, or individual parts of a complex parameter, are allocated
-
How parameters are passed (pushed on the stack, placed in registers, or a mix of both)
-
Which registers the called function must preserve for the caller (also known as: callee-saved registers or non-volatile registers)
-
How the task of preparing the stack for, and restoring after, a function call is divided between the caller and the callee
It is important to understand that without such conventions, we cannot safely link and execute portions of code compiled by different parties. Without these conventions, the concept of library would not be possible.
The function prologue is parts of the convention that a Callee must follow. There are also Caller conventions, such as pushing parameters on the stack within a predefined order.
Tip
Observe the assembler’s code above to deduce the order. With all the information provided, you should be able to read and understand the assembler of such a simple function.
Writing Secure Software: it is complicated
Now that we have covered the basics, we can start diving into security specific issues of low-level software programming. Usually, a beginner in C programming would start exploring programming by doing simple small project, like a terminal-based hangman game. To do such program, we only need to understand loops, conditions, writing/reading to and from stdin, which makes it excellent to learn to master basics. Browsing github; the first one I found:
#include <stdio.h>
#include <string.h>
void hangman(int i){
switch (i){
case 0:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| | | / \n| |/ \n| | \n| | | \n| | \n| | \n| | | \n| | \n| | \n| | | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 1:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| | | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | | \n| | \n| | \n| | \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 2:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | . . \n| | | | \n| | | . | \n| | | | \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 3:
printf("___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . \n| | // | | \n| | // | . | \n| | ') | | \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 4:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . Y\ \n| | // | | \\ \n| | // | . | \\ \n| | ') | | (` \n| | \n| | \n| | \n| | \n| | \n|=========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 5:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . Y\ \n| | // | | \\ \n| | // | . | \\ \n| | ') | | (` \n| | || \n| | || \n| | || \n| | || \n| | / | \n==========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
case 6:
printf(" ___________.._______ \n| .__________))______| \n| | / / || \n| |/ / || \n| | / ||.-''. \n| |/ |/ _ \ \n| | || `/,| \n| | (\\`_.' \n| | .-`--'. \n| | /Y . . Y\ \n| | // | | \\ \n| | // | . | \\ \n| | ') | | (` \n| | || || \n| | || || \n| | || || \n| | || || \n| | / | | \\ \n==========|_`-' `-' |===| \n|=|=======\ \ '=|=| \n| | \ \ | | \n: : \ \ : : \n. . `' . . \n");
break;
}
}
int main()
{
char word[20]; //Used to store the user word. Most words are less than 20 characters so the default size is 20.
char stars[20]; //A string full of * that are replaced upon the user entering the right letter of the word.
int counter = 0; //A counter to use in the for loops.
int len; //len is the length of the word entered.
char ch; //ch is a temporary character variable.
int strikes=0; //strikes counts how many wrong characters the user has guessed.
int trigger = 0; //The trigger variable serves as a flag in the for loops bellow.
int wincounter=0; //wincounter keeps track of the number of correct guesses.
int i; //Another counter variable to be used in for loops.
//Ascii Art
printf(" _ \n");
printf("| | \n");
printf("| |__ __ _ _ __ __ _ _ __ ___ __ _ _ __ \n");
printf("| '_ \\ / _` | '_ \\ / _` | '_ ` _ \\ / _` | '_ \\ \n");
printf("| | | | (_| | | | | (_| | | | | | | (_| | | | | \n");
printf("|_| |_|\\__,_|_| |_|\\__, |_| |_| |_|\\__,_|_| |_| \n");
printf(" __/ | \n");
printf(" |___/ \n");
printf("\n\nEnter a word:"); //Ask the user to enter a word.
scanf("%s", &word);
len = strlen(word); //Make len equal to the length of the word.
//Fill the stars string with * according to the input word length (len)
for(counter=0; counter<len; counter++)
{
stars[counter]='*';
}
stars[len]='\0'; //Insert the terminating string character at the end of the stars string.
//Enter main program loop where guessing and checking happens. 26 is for 20 maximum characters + 6 strike characters.
for(counter = 0; counter<26; counter++)
{
if(wincounter==len) //If the number of correct guesses matches the length of the word it means that the user won.
{
printf("\n\nThe word was: %s\n", word);
printf("\nYou win!\n");
break;
}
hangman(strikes); //Print the hangman ascii art according to how many wrong guesses the user has made.
if(strikes==6) //If the user makes 6 wrong guesses it means that he lost.
{
printf("\n\nThe word was: %s\n", word);
printf("\n\nYou lose.\n");
break;
}
printf("\n\n\n\n%s", stars); //Print the stars string (i.e: h*ll* for hello).
printf("\n\nGuess a letter:"); //Have the user guess a letter.
scanf(" %c",&ch);
for(i=0; i<len; i++) //Run through the string checking the characters.
{
if(word[i]==ch)
{
stars[i]=ch; //If the guess is correct, replace it in the stars string.
trigger++; //If a character the user entered matches one of the initial word, change the trigger to a non zero value.
wincounter++; //Increase the number of correct guesses.
}
}
if(trigger==0)
{
strikes++; //If the trigger is not a non zero value, increase the strikes counter because that means that the user input character didn't match any character of the word.
}
trigger = 0; //Set the trigger to 0 again so the user can guess a new character.
}
return 0;
}
This program was written by a beginner C programmer, and it contains vulnerabilities. These kind of vulnerabilities are discussed below and we will learn how to exploit some of them within a controlled environment, in an ethical way. A question that could tickle you: do you think it is “normal” for a beginner programmer to create vulnerabilities? Is that part of the journey; i.e., we make mistake, learn, and hopefully make less of these mistakes in the future?
Maybe… But maybe we got the C language wrong, an unsafe tool in the hands of many, beginners like experts. Experts are still making similar mistakes all of the time. Today, the industry is moving away form C/C++ and is looking for more robust languages with the same performance guarantee. Rust is one answer, and the reason we will extensively use it during this class. And indeed, the whole high profile industry has started moving to Rust, as well as many high profile open-source projects.
Typical C Programming Issues
C programming vulnerabilities stem from the fact that the semantic of
the language is loosely defined. Programmers are allowed to perform
actions that cannot be semantically valid, which results to what we call
Undefined Behavior or UB once the code is compiled and executed, since
the compiler does not have any rule to follow while compiling an
undefined action. The compiler can do anything it wants.
The following programming issues in C are classical programming errors
known to lead to UB and for some of them, potential vector of
exploitations:
- Buffer overrun (also called Buffer Overflow).
- Dangling Pointer
- Double Free
- Integer Overflow
- Usage of uninitialized memory
So let’s cover them.
Buffer Overrun
Look at the following code that reads from stdin and prints to stdout.
#include <stdio.h>
#include <stdlib.h>
char *
gets(char *buf) {
int c;
while((c = getchar()) != EOF && c != '\n')
*buf++ = c;
*buf = '\0';
return buf;
}
int
read_req(void) {
char buf[10];
int i;
gets(buf);
i = atoi(buf);
return i;
}
int
main() {
int x = read_req();
printf("x = %d\n", x);
}
Compile the code, run it, the program would wait for input (due to
getchar()), and type something longer than 10 characters. Here’s what
I did:
$ gcc -m32 -fno-stack-protector unsafe_ex1.c -o unsafe_ex1
$ ./unsafe_ex1
$ 1R2512553252355A525523525(2535235
Erreur de segmentation (core dumped)
The error says that the program is attempting to access an address that the OS didn’t mapped for it, resulting in a segmentation fault. What happens exactly will be discussed in details in a next chapter, for now, observe that going beyond the expected buffer size at runtime may result to a crash.
Note as well that it is possible to program a safer version. Look at the following safe piece of code, and compare it to the first one:
#include <stdio.h>
#include <stdlib.h>
#define MAX_BUFF_SIZE 10
char *
gets(char *buf) {
int c, i = 0;
while(i < MAX_BUFF_SIZE - 1 && (c = getchar()) != EOF && c != '\n') {
i++;
*buf++ = c;
}
*buf = '\0';
return buf;
}
int
read_req(void) {
char buf[MAX_BUFF_SIZE];
int i;
gets(buf);
i = atoi(buf);
return i;
}
int
main() {
int x = read_req();
printf("x = %d\n", x);
}
The problem is: we need the programmer to be extra careful while manipulating some APIs and some constructs, like buffers. Many functions from the standard library were designed with a performance focus, helping the compiler to get optimizations right easily.
Note
The git software publicly available on github has a
Cheader preventing contributors to use what they consider to be unsafe functions from the standard library. If a contribute tries using one of these functions, he would not be able to compile.#ifndef BANNED_H #define BANNED_H /* * This header lists functions that have been banned from our code base, * because they're too easy to misuse (and even if used correctly, * complicate audits). Including this header turns them into compile-time * errors. */ #define BANNED(func) sorry_##func##_is_a_banned_function #undef strcpy #define strcpy(x,y) BANNED(strcpy) #undef strcat #define strcat(x,y) BANNED(strcat) #undef strncpy #define strncpy(x,y,n) BANNED(strncpy) #undef strncat #define strncat(x,y,n) BANNED(strncat) #undef strtok #define strtok(x,y) BANNED(strtok) #undef strtok_r #define strtok_r(x,y,z) BANNED(strtok_r) #undef sprintf #undef vsprintf #define sprintf(...) BANNED(sprintf) #define vsprintf(...) BANNED(vsprintf) #undef gmtime #define gmtime(t) BANNED(gmtime) #undef localtime #define localtime(t) BANNED(localtime) #undef ctime #define ctime(t) BANNED(ctime) #undef ctime_r #define ctime_r(t, buf) BANNED(ctime_r) #undef asctime #define asctime(t) BANNED(asctime) #undef asctime_r #define asctime_r(t, buf) BANNED(asctime_r)
Dangling pointer
A dangling pointer is a pointer that does not point to an object of the pointer’s type. A typical programming error creating a dangling pointer would be to return from a function a pointer that points over an element that lives on the stack frame of that function. For example:
#include <stdio.h>
int* foo() {
int x = 42; // Local variable lives on foo's stack frame
return &x; // Returning the address of a local variable (DANGLING POINTER!)
}
int main() {
int *ptr = foo(); // ptr now points to an invalid memory location
// that may be overriden by other parts of the
// program; e.g., at the next function call.
printf("ptr points to: %d\n", *ptr); // Undefined behavior! May crash or print garbage
return 0;
}
With modern gcc, the compiler may use a static analyzer and generate
warnings that would tell you that something is wrong.
dangling.c: In function ‘foo’:
dangling.c:5:12: warning: function returns address of local variable [-Wreturn-local-addr]
5 | return &x; // Returning the address of a local variable (DANGLING POINTER!)
By default, gcc enables the -Wreturn-local-addr flag while compiling.
There are many others flags to run static analysis on the code while
compiling; most of them are deactivated to not impair compile time. It
is however best to enable a bunch of them, take a look at gcc --help=W’s documentation. Usually debug builds enable all of them while
compiling using the -Wall flag.
Another typical mistake creating dangling pointers is to reallocate memory behind a pointer, yet still keeping the first pointer around.
#include <stdio.h>
#include <stdlib.h>
int main() {
int *ptr = (int *)malloc(sizeof(int));
*ptr = 42;
printf("Initial value: %d\n", *ptr); // Output: Initial value: 42
// Reallocate memory
int *nptr = (int *)realloc(ptr, 10 * sizeof(int));
if (nptr == NULL) {
printf("Memory reallocation failed\n");
return -1;
}
// The old memory location is now deallocated
// ptr points to a new memory location
printf("Reallocated value: %d\n", *nptr); // Output: Reallocated value: 0 (or some garbage value)
// The original pointer is now a dangling pointer
// Accessing the original memory location is undefined behavior
printf("Original value: %d\n", *ptr); // Undefined behavior
free(nptr);
return 0;
}
In practice, it usually happens by holding a pointer to elements stored within a data structure, such as a map or a dynamic list. The data structure may reallocate its memory upon, for example, new elements being added, and the previous memory the pointer is pointing to becomes invalid. From a security point of view, if an attack eventually gain the ability to make that pointer points to an arbitrary location of its choice, it may gain arbitrary code execution capability.
Double Free
Double free in another classical programming error. In C, the
programmer is responsible for allocating and deallocating heap memory.
Forgetting to free memory leads to a memory leak, where a program may
gradually eat all the system’s memory. Freeing twice the same pointer
may have various consequences such as program crash or potential
exploitation vector for executing other piece of codes.
To understand how these exploitations may happen, we first have to
understand how allocation and deallocation works on a modern system.
Memory allocation and deallocation within the heap is controlled by the
operating system’s developers libraries. Linux has multiple C
libraries, also called GNU C Library. glibc is the default system
library on most modern Linux OSes. This library may have however various
names for backward compatibility reasons, since we need old software to
still compile properly on modern OS. glibc library has, among others,
APIs for memory allocation and deallocation: malloc() and free(),
and deal itself with all the logic for this allocation to be performant,
thread-safe and hopefully free from exploitable vulnerabilities. This is
hard to do, since these are conflicting properties. So, we’ll try here
to get a bit more insight on how memory works, and what can go wrong.
Let’s exemplify with a simple program taking a command from stdin and
executing code related to the provided command. The program has the
ability to echo the typed text, reversed the typed text or simply
exiting the program.
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#define MAX_INPUT 256
typedef struct {
uint8_t command;
char *params;
} Command;
void reverse_string(char *str) {
int len = strlen(str);
for (int i = 0; i < len / 2; i++) {
char temp = str[i];
str[i] = str[len - i - 1];
str[len - i - 1] = temp;
}
}
void execute_command(Command *cmd) {
switch (cmd->command) {
case 1: // Echo
printf("Echo: %s\n", cmd->params);
break;
case 2: // Reverse string
reverse_string(cmd->params);
printf("Reversed: %s\n", cmd->params);
break;
case 3: // Exit
printf("Exiting...\n");
exit(0);
default:
printf("Unknown command.\n");
}
}
uint8_t parse_command(const char *input) {
if (strncmp(input, "echo", 4) == 0) return 1;
if (strncmp(input, "reverse", 7) == 0) return 2;
if (strncmp(input, "exit", 4) == 0) return 3;
return 0;
}
int main() {
char input[MAX_INPUT];
Command cmd;
while (1) {
printf("Enter a Command: ");
if (!fgets(input, MAX_INPUT, stdin)) {
perror("Error reading input");
continue;
}
input[strcspn(input, "\n")] = 0;
char *space = strchr(input, ' ');
if (space) {
*space = '\0';
space++;
} else {
space = "";
}
cmd.command = parse_command(input);
cmd.params = malloc(strlen(space) + 1);
if (!cmd.params) {
perror("Memory allocation failed");
continue;
}
strcpy(cmd.params, space);
execute_command(&cmd);
free(cmd.params);
}
return 0;
}
Start by carefully read the program, and observe that one may draw a representation of the main function stack frame as follows:
Higher addr +------------------+
| | ... |
| +------------------+
| | input[255] |
| +------------------+
| | ... |
| +------------------+
| | input[0] |
V +------------------+
| command |
+------------------+
| params | ---
+------------------+ |
%esp ------> | | |
+------------------+ |
| ... | |
+------------------+ |
| | |
^ | | |
| | | |
| | Heap | |
| | |<--|
| | |
lower addr +------------------+
in particular, params is a heap allocation created by the malloc()
call. It points to a memory region which lives in the heap, and which is
provided by glibc.
One can compile to program as follows, assuming your filename for the
code is malloc_ex1.c:
$ gcc -m32 malloc_ex1.c -o malloc_ex1
If one runs the program as follows:
$ ./malloc_ex1
Enter a Command: reverse test test
Reversed: tset tset
Executing this code, the program calls malloc() to get an allocation
in the heap of the size of strlen("test test") + 1. Such an allocation
in the heap is in fact larger than the size requested. It looks like
this:
+------------------+
| Metadata |
params -------> +------------------+
+ +
+ User Allocation + size strlen("test test") + 1
+ +
+------------------+
| Metadata |
+------------------+
The allocation creates metadata above and below the requested allocation
by the program. Metadata may contain padding to align the location
address of params (the pointee) to a value we may divide by 16 (16-bytes
alignment is usually used, although other powers of 2 may be in use
depending on the architecture or OS). The program that manages the Heap
(i.e., internal code within glibc) also needs to put information in
there to avoid remembering it elsewhere. You may read more about
malloc() and free()’s internals
here.
Let’s see what happens when the program calls free() on a memory
allocation. In our case, when we free the pointer params. The free
call marks a chunk as being free to be reused by the process. It is a
recycling design. The memory, while being freed, is still mapped for a
given process. Other process do not necessarily have access to this
mapping.
The free() call arranges the freed memory in bins using a circular double-linked list
manipulated by a fwd_pointer and a bwd_pointer written inside the
freed chunk. That is, upon free’ing, glibc overrides part of the memory
data with metadata it needs for managing the chunk of memory within its
caching logic.
+------------------+
| Metadata | Original metadata
params -------> +------------------+
+ fwd_pointer + More metadata
+------------------+
+ bwd_pointer +
+------------------+
+ rest of chunk +
+ +
+------------------+
| Metadata |
+------------------+
The free() call does also a bunch of sanity check to avoid running
code on obviously wrong addresses (a correct pointer would be one given
by an allocation function). The addresses are stored in a bins, and free
chunks can then be iterated using the linked list. There are several
bins for performance reasons, especially for multi-threaded
code that may free() at the same time.
So that we know a bit more how malloc() and free() work, let’s take
the following code example:
#include <stdlib.h>
int main() {
int *p = malloc(sizeof(int));
*p = 0;
free(p);
// Dereference pointer again after freeing it.
if (*p) {
printf("Holly cow!\n");
}
}
We are using p again after freeing it. This is called a
use-after-free. It may lead to undefined behavior, and is some case
potential vectors of exploitation.
Integer Overflow
An integer overflow happens when we try to store an integer bigger than what the type can
hold. E.g., int is 32-bits, if one stores MAX_INT + 1 (i.e.,
\(2^{32}\)), it would
overflow. The C standard does not specify what to do. It is an undefined behavior
(anything might happen in your program), the compiler chooses what to do. Such error
usually arises from an arithmetic expression that results in an integer outside
of the allowed bounds defined by a given type.
Overflowing an integer usually results in wrapping around the maximum value
by cutting the most significant bits, but this behavior is not
guaranteed.
In some occasions, an integer overflow can lead to an exploitable vulnerability. The SHA3 design who won the contest for the new standard cryptographic Hash function (NIST) was submitted with its code holding an integer overflow, which was exploitable.
...
partialBlock = (unsigned int)(dataByteLen - i);
if (partialBlock + instance->byteIOIndex > rateInBytes)
partialBlock = rateInBytes - instance->byteIOIndex;
i += partialBlock;
SnP_AddBytes(instance->state, curData, instance->byteIOIndex,
partialBlock);
-> partialBlock, instance->byteIOIndex and rateInBytes were unsigned 32-bit integers
-> dataByteLen and i were unsigned 64-bits integers from size_t, which are 64
bits on x86_64
So, first a 64-bits integer is cast into a 32-bits integer (partialBlock).
This is an incorrect type casting that can already be an issue on any 64-bits system.
On a 32-bits system, the cast is correct.
Second, partialBlock + instance->byteIOIndex may overflow, making the condition evaluate
to false.
It results to a partialBlock value much larger than expected to be
passed to SnP_AddBytes. Without much more details, it turns out that
partialBlock is used in this function alongside buffer manipulations,
resulting in an exploitable write primitive (i.e., the ability for the
attacker to write code at an address it can choose).
The write primitive in SHA3 can then be used to break pretty much any cryptography algorithm used with this SHA3 implementation.